《烽火通信》专题
-
奴隶丢失,加入火花的速度很慢
-
由于存储帐户防火墙,Azure Runbook失败
我有一个每天早上运行的Azure Runbook。 Runbook执行“Get-AzureStorageBlob”,但由于我们在存储帐户上启用了防火墙,它现在失败并出现错误: Get-AzureStorageBlob:远程服务器返回错误:(403)禁止。HTTP状态代码:403-HTTP错误消息:此请求无权执行此操作。第8行字符:17。。。ldBackups=Get AzureStorageBlo
-
Azure存储帐户:防火墙和虚拟网络
我为Azure存储帐户启用了虚拟网络和防火墙访问限制,但遇到了一个问题,即我无法从Azure Functions(ASE环境)访问存储帐户,尽管ASE公共地址是作为例外添加的。此外,我添加了所有环境的虚拟网络,只是为了确保。是否有任何方法可以检查函数/其他服务试图从哪个地址访问存储帐户?此外,我有一个勾选“允许受信任的Microsoft服务访问此存储帐户”。我不确定“受信任的Microsoft服务
-
Azure功能访问Azure存储帐户防火墙
我想要实现什么 通过Azure Function连接到位于防火墙后面的Azure BLOB存储帐户。 迄今为止采取的步骤 Azure Function针对按预期工作的公共存储帐户开发和测试。 在我的Azure Function的Azure资源管理器之后,我找到出站地址(条目),并将它们添加到存储帐户的防火墙中。 问题 在尝试对具有防火墙的存储帐户运行Azure功能时,我收到一个状态:500内部服务
-
将点火器[T]/Iterable[T]转换为Future[SEQ[T]]
基本上,我想读取Apache Ignite上的查询返回的所有值,该查询返回一个IgniteCursor。 我想以非阻塞的方式读取光标。 我可以写: 也许我错过了什么? 换句话说,有一种方法可以使用“异步非阻塞IO”从Ignite获取记录列表?
-
使用命令提示符修改Windows防火墙
使用命令提示符修改Windows防火墙 我可以允许域/公共/私有复选标记都在同一行中(就像我可以手动单击一样)? 到目前为止,我有3个条目,每种类型都有一个复选标记: netsh advfirewall firewall add rule name=“MyApp”dir=in action=allow program=“C:\MyApp.exe”enable=yes profile=domain
-
星火结构化流-如何忽略检查点?
我正在使用微批处理()从Kafka stream读取消息,处理消息并通过将结果写入另一个Kafka主题。该作业(流式查询)被设计为“永远”运行,处理大小为10秒(处理时间)的微批。已设置选项,因为Spark需要检查点。
-
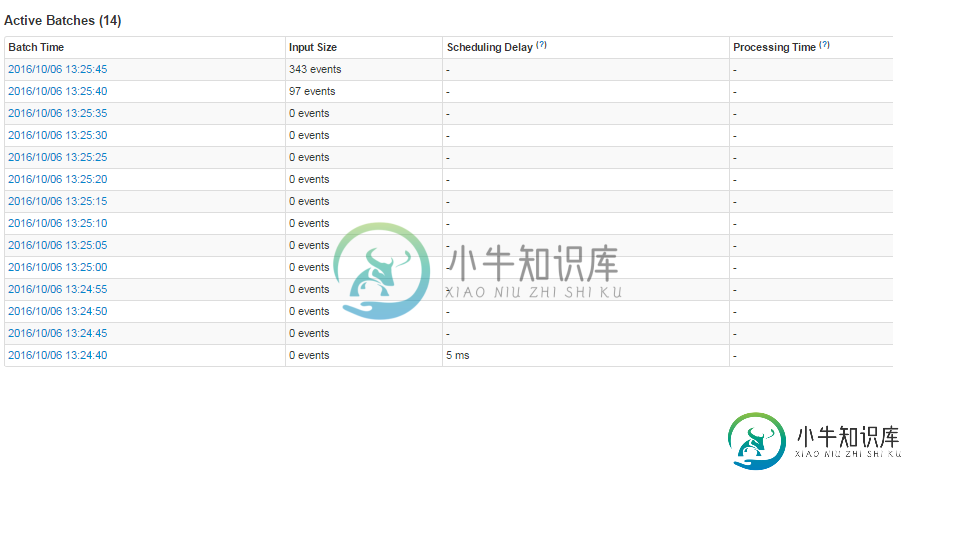 火花流与Kafka-从检查点重新启动
火花流与Kafka-从检查点重新启动我们正在构建一个使用Spark Streaming和Kafka的容错系统,并且正在测试Spark Streaming的检查点,以便在Spark作业因任何原因崩溃时可以重新启动它。下面是我们的spark过程的样子: Spark Streaming每5秒运行一次(幻灯片间隔),从Kafka读取数据 Kafka每秒大约接收80条消息 我们想要实现的是一个设置,在这个设置中,我们可以关闭spark流作业(
-
错误火花流中重载的方法值createDirectStream
在调用参数化版本的CreateStream时,我也会遇到类似的错误。 你知道有什么问题吗?
-
在火花scalaGroupByKey($"coll")和GroupBy($"coll")之间的区别
当我使用DF的列名作为参数时,与使用和有什么根本区别? 哪一个是省时的,每一个的确切含义是什么?当我通过一些例子时,请有人详细解释一下,但这是令人困惑的。
-
火花2。x数据帧或数据集?[副本]
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
并行化步骤中的火花内存错误
我们正在使用最新的Spark构建。我们有一个非常大的元组列表(8亿)作为输入。我们使用具有主节点和多个工作节点的docker容器运行Pyspark程序。驱动程序用于运行程序并连接到主机。 运行程序时,在sc.parallelize(tuplelist)行,程序要么退出并显示java堆错误消息,要么完全退出而不出错。我们不使用任何Hadoop HDFS层,也不使用纱线。 到目前为止,我们已经考虑了这
-
火花-如何从时间戳中提取小时?
请帮助理解为什么不提取为8:15am? W3C日期和时间格式 示例1994-11-05T08:15:30-05:00对应于美国东部标准时间1994年11月5日上午8:15:30。 用于格式化和解析的日期时间模式
-
在火花scala中使用结构创建模式
我是scala新手,尝试从元素数组中创建自定义模式,以读取基于新自定义模式的文件。 我正在从json文件中读取数组,并使用爆炸方法为列数组中的每个元素创建了一个数据框。 获得的输出为: 现在,对于上面列出的所有值,我尝试使用下面的代码动态创建val模式 上面的问题是,我能够在struct中获取数据类型,但我也希望仅为数据类型decimal获取(scale和preicion),其限制条件为max a
-
从火花DataFrame在elasticsearch中索引嵌套字段
假设我有一张这样的桌子: 它以拼花地板的形式存储。我需要在spark中读取表,在“field1”上执行groupBy,然后我需要在ES中存储一个嵌套字段(例如,称为“agg\u字段”),其中包含一个字典列表,其中包含字段2和字段3的值,这样文档将如下所示: 我可以阅读表格并进行分组: 我可以做一些聚合并将结果发送给es: 但我不知道如何将聚合更改为嵌套的“agg\u fields”列,该列将被el