《烽火星空》专题
-
 最近Python有点火? 给你7个学习它的理由!
最近Python有点火? 给你7个学习它的理由!本文向大家介绍最近Python有点火? 给你7个学习它的理由!,包括了最近Python有点火? 给你7个学习它的理由!的使用技巧和注意事项,需要的朋友参考一下 Python 是一门更注重可读性和效率的语言,尤其是相较于 Java,PHP 以及 C++ 这样的语言,它的这两个优势让其在开发者中大受欢迎。 诚然,它有点老了,但仍是80后啊 —— 至少没有 Cobol 或者 Fortran 那么老。而且
-
配置火花应用参数的最佳开端是什么?
我很困惑我应该使用哪种方法来配置火花应用程序参数。 让我们考虑以下集群配置:10个节点、每个节点16个内核和每个节点64GB RAM(例如https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application.html0 根据上述建议,让我们为每个执行器分配5个
-
 如何在HDFS中附加到相同的文件(火花2.11)
如何在HDFS中附加到相同的文件(火花2.11)我正在尝试使用SparkStreaming将流数据存储到HDFS中,但它会继续在新文件中创建附加到一个文件或几个多个文件中 如果它一直创建n个文件,我觉得效率不会很高 代码 在我的pom中,我使用了各自的依赖项: 火花-core_2.11 火花-sql_2.11 火花-streaming_2.11 火花流-kafka-0-10_2.11
-
如何通过apache火花图形获取SSSP实际路径?
我在火花站点上运行了单源最短路径(SSSP)示例,如下所示: Grax-SSSP预凝胶实例 代码(scala): sourceId:0获取结果: (0,0.0) (4,2.0) (2,1.0) (3,1.0) (1,2.0) 但是我需要如下实际路径: = 如何通过spark graphX获得SSSP实际路径<有人给我一些提示吗<谢谢你的帮助
-
PySpark火花与库伯内特斯大师会话生成器
我最近看到一个pull请求被合并到Apache/Spark存储库中,该存储库显然为K8s上的PySpark添加了初始Python绑定。我在公关上发表了一条评论,问了一个关于如何在Python Jupyter笔记本中使用spark-on-k8s的问题,并被告知在这里问我的问题。 我的问题是: 有没有办法使用PySpark的主控设置为
-
如何通过获取js在火狐API的请求?[重复]
我有一个web服务器,它有API。我使用Postman来创建POST和Get请求,所有的工作都很好。现在我已经开始编写前端应用程序,无法从浏览器发出post请求。从计算机上运行index.html时,出现以下错误:“跨源请求被阻止:同一源策略不允许读取远程资源https://localhost:3000/python. 原因:CORS标头“访问控制允许来源”丢失。这是我的密码:
-
防火墙背后的Apache背后的Tomcat:AJP忽略X-Forwarded-Proto
防火墙:终止https,添加“x-forwarded-proto:https”,通过http转发到Apache Apache:通过ajp转发到Tomcat Tomcat:通过ajp-connector接收请求 我们已经将RemoteIpValve添加到Tomcat的server.xml中: 如果我们跳过Apache,直接从防火墙转到使用常规HTTP连接器的Tomcat,它就可以工作。在这种情况下,
-
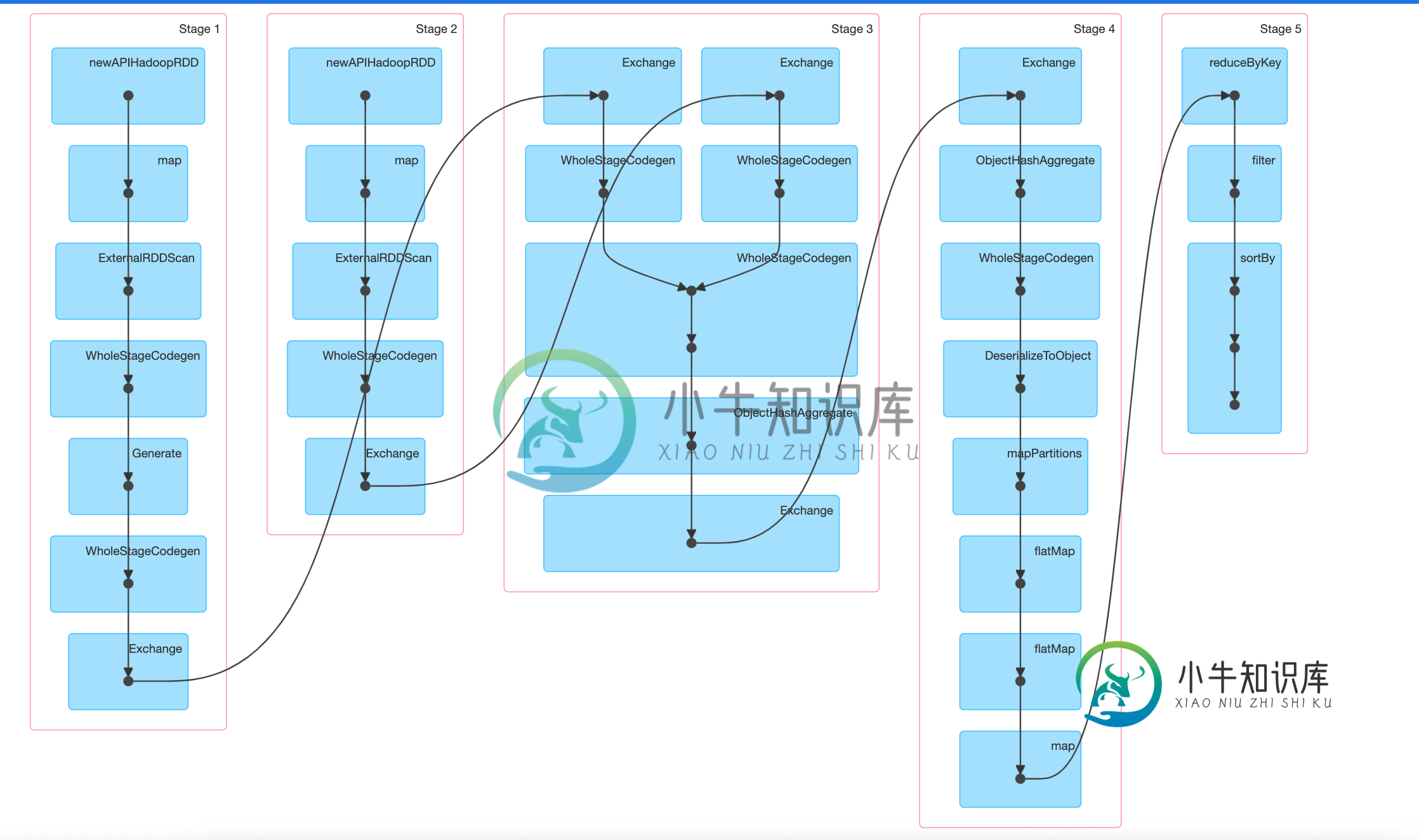 连接后在各阶段之间卡住的火花作业
连接后在各阶段之间卡住的火花作业我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘
-
如果否,如何处理火花RDD分区。执行者数
我想了解火花流中的一个基本的东西。我有50个Kafka主题分区和5个执行者的数字,我正在使用DirectAPI所以没有。的RDD分区将为50个。这个分区将如何在5个执行器上处理?将在每个执行器上一次触发进程1个分区,或者如果执行器有足够的内存和内核,它将在每个执行器上并行处理超过1个分区。
-
火狐浏览器打开后一秒关闭,忽略场景
我的控制台: RG.OpenQA.Selenium.Remote.UnreachableBrowserException:无法启动新会话。可能的原因是远程服务器地址无效或浏览器启动失败。生成信息:版本:“3.4.0”,修订版:“Unknown”,时间:“Unknown”系统信息:主机:“WS00MU016”,IP:“”,OS.Name:“Windows 10”,OS.ARCH:“AMD64”,OS
-
 如何比较火库颤振应用中的两个集合?
如何比较火库颤振应用中的两个集合? -
验证后角度火灾库电子邮件验证错误
我正在用电子邮件和密码设置授权功能。一切正常,但当我创建一个新用户时,应用程序会发送一封带有验证链接的电子邮件。在我验证电子邮件地址后,我想登录,因此我返回登录表单。在我硬重新加载页面后,emial_。有人能帮我吗?
-
石英下次点火时间还是上次触发时间?
我正在使用Quartz和Spring来安排工作。我有一份按计划每小时运行的工作。问题是,当计划的作业耗时超过一小时时,该作业的“下一次启动时间”仍然是旧时间,不会启动(因为启动时间已经过去)。 我的问题是,如果工作时间超过预定时间,我们如何更改“下一次点火时间”?
-
阿拉莫火挑战委托和逃避关闭的问题
我正在使用AF并使用它的委托来捕获我的服务器返回的身份验证质询。 我的问题: > 如果我按原样使用上面的代码,我会 错误:“将非转义参数'completionHander'传递给需要@escaping闭包的函数” 如果我使函数handleAuthenticationSession的参数不转义,我会得到: 错误:“使用非转义参数“completion”可能会使其转义” 此外,AuthHandler类
-
Google Cloud Dataproc最后阶段作业失败引发的火花
我在Dataproc上使用Spark集群,但我的作业在处理结束时失败了。 我的数据源是Google Cloud Storage上csv格式的文本日志文件(总量为3.5TB,5000个文件)。 处理逻辑如下: 将文件读到DataFrame(模式[“timestamp”,“message”]); 将所有邮件分组到1秒的窗口中; 对每个分组消息应用管道[tokenizer->HashingTF]以提取单