《烽火星空》专题
-
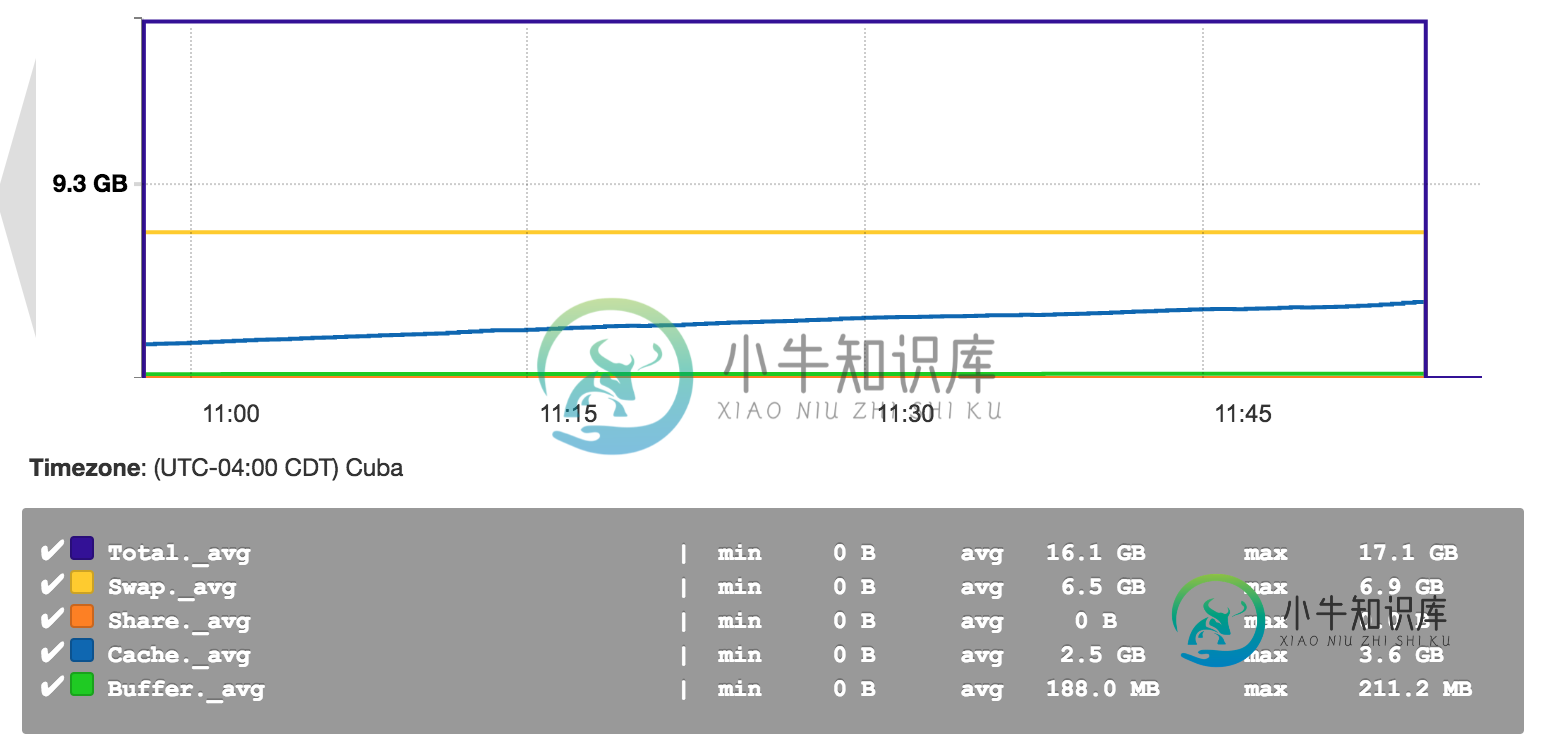 火花集群的Ambari仪表板内存使用说明
火花集群的Ambari仪表板内存使用说明我使用Ambari来监视我的spark群集,我对所有的内存类别都有点困惑;有专业知识的人能解释一下这些术语的含义吗?提前感谢! 以下是Ambari内存使用率缩小的屏幕截图: 基本上,交换、共享、缓存和缓冲区的内存使用代表什么?(我想我完全理解了)
-
Symfony 3,一个应用程序中有2个防火墙
我在symfony 3中遇到了防火墙问题。三天以来,我一直在努力解决这个问题。我已经阅读了文档,并根据它做了所有事情,但应用程序并没有像我预期的那个样工作。 目标:所有页面(登录页面除外)都需要登录用户。如果用户未登录,则应将其重定向到/login页面。这就是全部。 根据这几页: http://symfony.com/doc/current/book/security.html http://sy
-
在火花中读取csv时防止分隔符碰撞
如何捕捉此字段中的而不将其视为CSV分隔符?
-
使用 MLib 的阿帕奇火花中的分类变量
我对Apache Spark的世界比较陌生。我正在尝试使用LinearRegressionWithSGD()来估计一个大规模模型,我希望在不需要创建庞大的设计矩阵的情况下估计固定效果和交互项。 我注意到在决策树中有一个支持分类变量的实现 https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark
-
修复火花结构化流中的检查点[重复]
我在生产中遇到检查点问题,当 spark 无法从_spark_metadata文件夹中找到文件时 已经提出了一个问题,但目前还没有解决方案。 在检查点文件夹中,我看到批次29尚未提交,所以我可以从检查点的、和/或中删除一些内容,以防止火花因缺少文件而失败?
-
 硒网络驱动程序打开火狐,然后死亡
硒网络驱动程序打开火狐,然后死亡我有一个超级简单的测试脚本(如下)来开始使用WebDriver。当我运行测试(C#-Visual Studio 2015)时,它会打开一个Firefox浏览器,然后什么也不做。 有几个帖子讨论了以下问题,我也得到了: OpenQA. Selenium.在45000毫秒内启动套接字失败。试图连接到以下地址:127.0.0.1:7055。 但是那些关于这个问题的帖子很旧了,也有一个主要的不同——他们的
-
无法在火狐浏览器中导航特定的URL。
无法在firefox浏览器中导航特定URL。我编写了以下示例代码: 我得到的错误是: 组织。openqa。硒。火狐。NotConnectedException:45000毫秒后无法连接到端口7055上的主机127.0.0.1。Firefox控制台输出:dons。xpi调试正在更新{“id”:“的XPIState”sp@avast.com“,”syncGUID“{0652d9a4-3656-4279
-
火花读取来自 SAS 国际移民组织的 JDBC
我正在尝试使用火花 JDBC 从 SAS IOM 读取数据。问题是SAS JDBC驱动程序有点奇怪,所以我需要创建自己的方言: 然而,这还不够。SAS区分了列标签(=人类可读的名称)和列名称(=您在SQL查询中使用的名称),但似乎Spark在模式发现中使用列标签而不是名称,请参阅下面的JdbcUtils摘录: https://github.com/apache/spark/blob/master/
-
如何设置java版本路径火狐在运行时
请任何人帮助我在运行时设置java版本路径。 我在不同的目录中安装了两个java版本。但我需要使用Java7编译代码来使用java6版本执行应用程序。 我需要为firefox浏览器设置Java6路径,有人能帮我吗 提前谢谢
-
火花流:无状态重叠窗口与保持状态
选择无状态滑动窗口操作的一些注意事项是什么(例如,通过updateStateByKey或新mapStateByKey)选择保持状态(例如通过updateStateByKey或新mapStateByKey)时,使用火花流处理连续的有限事件会话流? 例如,考虑以下场景: 一种可穿戴设备跟踪由穿戴者进行的体育锻炼。该装置自动检测何时开始锻炼,并发出信息;在锻炼过程中发出附加信息(如心率);最后,当练习完
-
 从基于火源的数据库读取数据失败
从基于火源的数据库读取数据失败我正在读取火基数据库的数据。以下是存储在数据库中的数据的快照。 在以“8SS...”开头的快照字符串中,是用户的 uid。以下是用于从 firebase 数据库中检索数据的代码。 用户类包含getter和setters。 错误是只有结论。 如何评估 从值事件中读取时的错误是什么? 我尝试使用这个: 然后调用<code>ref。addListenerForSingleValueEvent()但仍然没
-
火力库实时数据库断开连接() 一致性
我有一个几乎功能齐全的实时数据库存在系统,如这里所述,但我遇到了一些问题。似乎即使在不久前断开连接后,人们仍然保持在线状态。我不知道为什么,但我暂时向未经身份验证的请求开放了我的安全规则,但无济于事。这可能是由于此处描述的错误。 如果问题是梯子,那么避免这个问题的正确JavaScript实现是什么?每 60 分钟重新创建一次“断开连接”侦听器是一个好的解决方案吗?作为参考,我使用的代码如下所示:
-
将字符串列转换为向量列火花数据
我有一个Spark dataframe,如下所示: 在此数据Frame中,features列是一个稀疏向量。在我的脚本,我必须保存这个DF文件在磁盘上。这样做时,features列被保存为文本列:示例。如您所料,在Spark中再次导入时,该列将保持字符串。如何将列转换回(稀疏)向量格式?
-
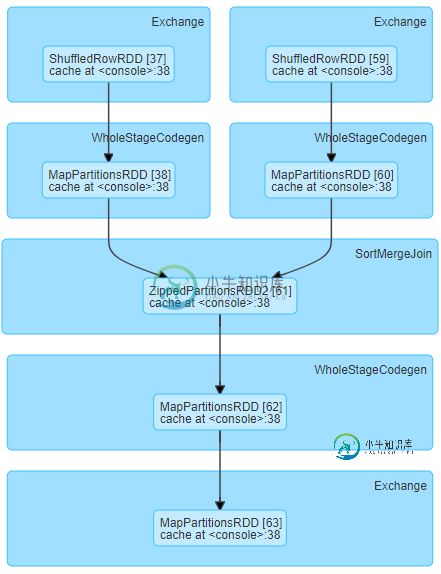 火花洗牌读取小数据需要大量时间
火花洗牌读取小数据需要大量时间我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间 一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。 这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组
-
优化数据流池大小以提高点火性能
我正在使用ignite2.6,其中有数据流节点,从kafka消耗数据并放入Ignite缓存。服务器平均负载较高,吞吐量降低。 我已经尝试为缓存中定义的索引内联设置索引大小,这样可以提供良好的性能,但也增加了服务器内存利用率和较高的平均负载。请说明在这种情况下增加datastreamer线程池大小会产生什么影响。