《烽火星空》专题
-
执行器核心数和利益或其他-火花
需要进行一些运行时澄清。 在我读到的其他地方的一个线程中,有人说Spark Executor应该只分配一个核心。然而,我想知道这是否真的永远是真的。阅读各种so问题和诸如此类的问题,以及Karau、Wendell等人的著作,可以清楚地看到,有相同或相反的专家指出,在某些情况下,每个执行者应该指定更多的内核,但讨论往往更多的是技术性的,而不是功能性的。也就是说,缺少功能性的例子。 > 我的理解是RD
-
Kinesis流和Kinesis火管更新弹性搜索指标
我们希望使用kinesis stream和firehose来更新aws管理的elasticsearch集群。我们有数百个不同的索引(对应于我们的DB碎片)需要更新。当创建firehose时,它要求我指定我想要更新的特定索引名。这是否意味着我需要为集群中的每个索引创建一个单独的消防水管?或者是否有一种方法来配置firehose,以便它知道基于数据内容使用什么索引。 此外,我们将有大约20个独立的生成
-
JCombobox焦点迷失不开火-为什么会这样?
我的代码中有一个< code>JCombobox。我已经添加了< code>FocusLost事件。但它无论如何也没有被解雇。我已经尝试了很多次,但没有找到解决办法。 但控制台中没有打印任何内容。请告诉我我做错了什么。
-
如何选择我的火花程序的scala版本?
我正在构建我的第一个Spark应用程序,用IDEA开发。 在我的集群中,Spark的版本是2.1.0,Scala的版本是2.11.8。 http://spark.apache.org/downloads.html告诉我:“从2.0版本开始,Spark默认是用Scala 2.11构建的。Scala 2.10用户应该下载Spark源代码包,并使用Scala 2.10支持进行构建”。 所以我的问题是:“
-
在elasticsearch上安装我的插件时,jackson很恼火
我正在为Elasticsearch编写一个自定义插件,这个插件对jackson库有依赖性。当我在Elasticsearch上安装插件时,我得到了这个错误: 线程“main”java.lang.IllegalStateException中的异常:由于jar hell导致:java.lang.IllegalStateException:jar hell导致加载插件AdapterPlugin失败!cla
-
阿帕奇火花 - 无法理解斯卡拉示例
我正在尝试了解这个位置的scala代码。(我来自java背景)。 https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/GroupByTest.scala 我在下面的部分感觉完全迷失了 我知道并行化和平面映射的作用。我不明白arr1是如何初始化的。它是 int 类型
-
Pyspark拆分字符串类型的火花数据框
我正在使用spark(批处理,而不是流)从kafka topic中读取数据来创建spark dataframe。我想使用spark将这个数据帧加载到cassandra。Dataframe是字符串格式,如下所示。 root |-value:string(nullable = true) 我尝试使用','分隔符拆分数据帧记录,并形成新的数据帧,我可以将其数据到cassandra。 创建了如下的火花DF
-
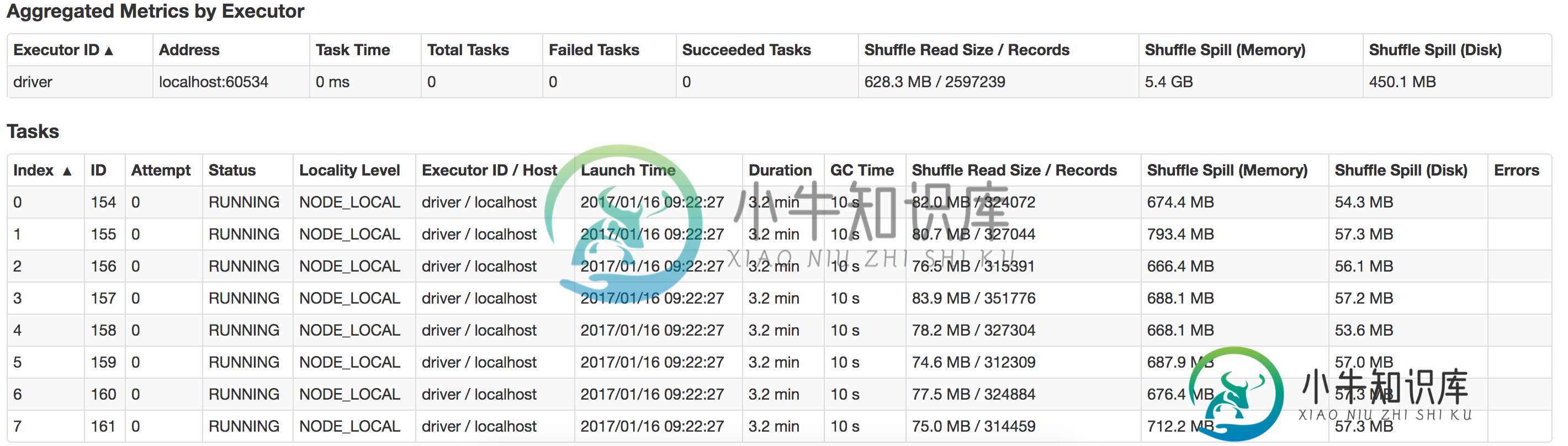 火花驱动程序内存和执行器内存
火花驱动程序内存和执行器内存我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
如何检测Safari、Chrome、IE、火狐和Opera浏览器?
我有FF、Chrome、IE、Opera和Safari的5个插件/扩展。 我如何识别用户浏览器并重定向(一旦一个安装按钮已经被点击)下载相应的插件?
-
火花中的coalesce(Num分区)是否经过洗牌?
我在火花变换函数中有一个简单的问题。 coalesce(numPartitions) - 将 RDD 中的分区数减少到 numPartitions。可用于在筛选大型数据集后更有效地运行操作。 我的问题是 > < Li > < p > coalesce(num partitions)真的会从filterRDD中删除空分区吗? coalesce(numPartitions)是否经历了洗牌?
-
每个分区中对象数量的火花合并
我们开始在团队中尝试spark。在我们减少spark中的工作后,我们希望将结果写入S3,但是我们希望避免收集Spark结果。目前,我们正在为RDD的每个分区写文件,但是这会产生很多小文件。我们希望能够将数据聚合到几个文件中,这些文件按照写入文件的对象数量进行分区。例如,我们的总数据是100万个对象(这是不变的),我们希望生成40万个对象文件,而我们当前的分区生成大约2万个对象文件(这因每个作业而异
-
处理dataskew而不加盐的连接键在火花
我正在尝试将一个100万行数据帧与一个30行数据帧进行内部连接,这两个表都有相同的连接键,spark正在尝试执行排序合并连接,因此我的所有数据最终都在同一个执行器中,例如,Job从未完成 我试着跟随 广播 已重新分区 查询执行计划 分区数的输出 即使我重新分区/广播数据,火花在加入时将所有数据带到一个执行器,数据在一个执行器上会发生倾斜。我还尝试将sortMergeJoinspark.sql.jo
-
 我怎样才能得到一个阵列从火神?
我怎样才能得到一个阵列从火神?我在Firestore有一个项目: 我需要获取数组“Personal”并在列表视图中显示它,我在这里看到一个类似的例子,从Firestore获取一个ArrayList和文档名,我尝试了这个解决方案。。。 Android Studio不显示错误,但试着运行应用程序,结果停止了,有人能帮我吗?
-
火狐路径错误?org.openqa.selenium.sessionNotCreatedException:无法启动浏览器
我已经读过类似的问题,所以,没有答案张贴,此外,我的错误确实似乎是不同的细节。 当我跑的时候 我收到以下错误: 我正在、和上运行,所以我不认为这是一个版本问题。我猜它可能是部分,在那里它正在寻找浏览器。
-
模拟器上未收到基于火堆的消息
我按照 https://stackoverflow.com/a/38626398/565212 中的说明将SNS连接到FCM到Android应用程序。部署到模拟器时,应用将初始化,但不会收到任何消息。同一应用程序在我实际的Nexus 6设备上正常工作并接收消息。为什么会有这种差异?