《烽火星空》专题
-
PowerShell小技巧之添加远程防火墙规则
本文向大家介绍PowerShell小技巧之添加远程防火墙规则,包括了PowerShell小技巧之添加远程防火墙规则的使用技巧和注意事项,需要的朋友参考一下 接着昨天的场景,虽然将Windows Server 2012 Core的默认控制台设置成了PowerShell,还启用了远程桌面,但是对于Core版本的服务器来讲,远程桌面形同鸡肋,所以我想启用PowerShell远程访问,在服务器上以管理员权
-
如何在python中操作火花数据帧?[重复]
有一个spark_df有许多重复如下: 现在我想将这个spark_df转换如下: 我在熊猫身上知道这一点。但是我正在努力学习火花,这样我就可以把它实施到大数据中。如果有人能帮忙,那就太好了。
-
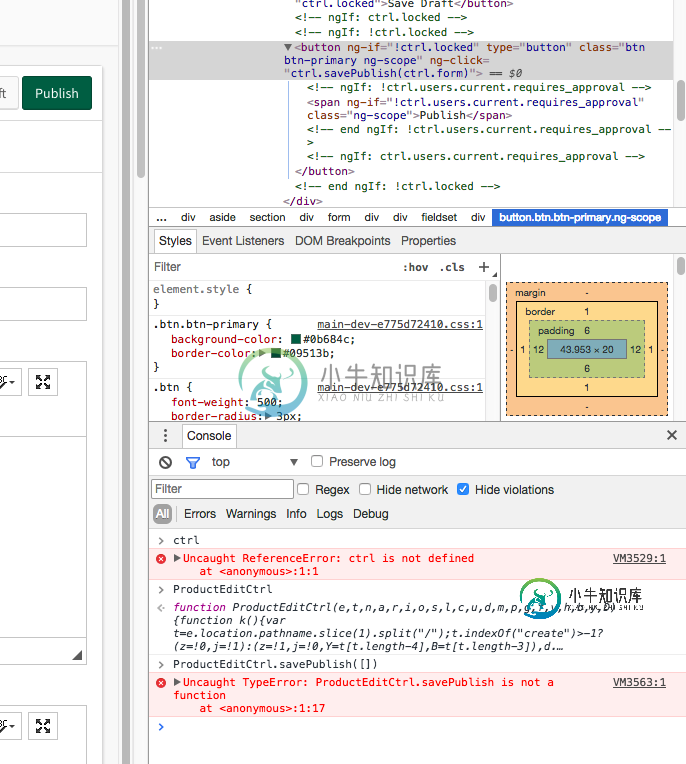 从控制台(Chrome或火狐)访问角控制器
从控制台(Chrome或火狐)访问角控制器我附上了一张我想从Chrome控制台运行的点击操作的图片,并传递了各种值。该按钮在inspect元素的右上角以灰色突出显示。这是我想学习如何访问/使用的函数。 按钮元素位于
-
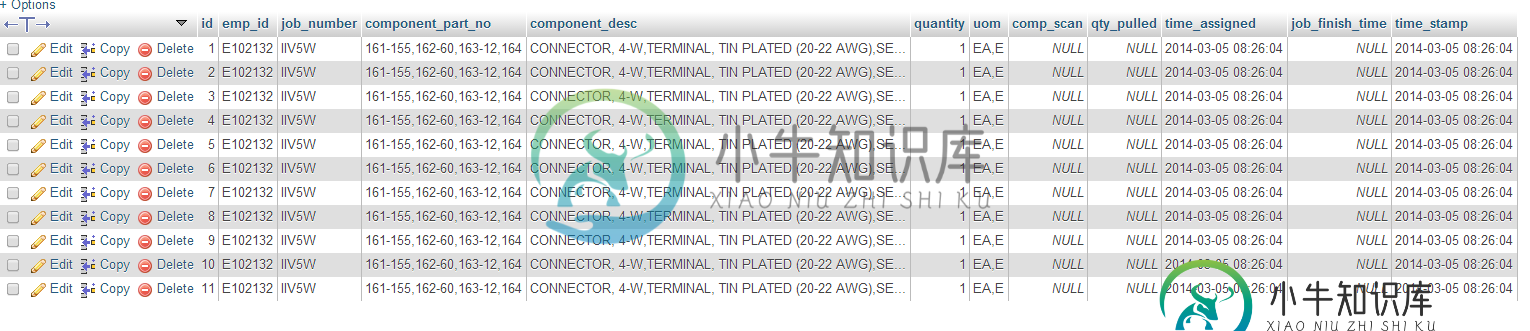 循环问题的代码点火器插入批次
循环问题的代码点火器插入批次我试图插入一个使用AJAX启动控制器的表单。表单是通过搜索另一个数据库生成的,该数据库创建了一个循环(foreach)表。用户将他/她的徽章扫描到输入字段中,然后在tab或blur上,jQuery启动对控制器的AJAX调用,控制器启动模型以插入数据库。它将数据写入数据库,但它循环表的所有行并将其插入数据库的每一行。因此,我将在db中设置10行,每列包含该列的所有10行数据(我假设是从我的内爆中)。
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
如何解码List的byte [] 到数据集 在火花?
问题内容: 我在我的项目中将spark-sql-2.3.1v和kafka与java8一起使用。我正在尝试将主题接收的byte []转换为kafka使用者方面的数据集。 这是详细信息 我有 我定义为 但是消息定义为 我试图定义为 我使用序列化将消息作为byte []发送到kafka主题。 我在Consumer上成功接收到消息字节[]。我正在尝试将其转换为数据集?? 怎么做 ? 出现错误: 线程“主”
-
任务': app: mergeDexDebug'执行失败。火力恢复|颤振
尝试在我的项目中使用FiRecovery。我的项目是一个全新的项目,但在我的设备上运行应用程序时遇到问题而没有收到错误:任务“: app: mergeDexDebug”执行失败。 我的应用程序正在使用AndroidX。我已经添加了我的谷歌服务。json文件,遵循步骤等。 Yaml文件: android/build。格拉德尔: 完全错误: 失败:构建失败,但有例外。 错误:任务:app:mergeD
-
触发一次的火花流追加输出模式
null 触发器是否支持一次追加模式? 这里有一个最小的应用程序来再现这个问题。要旨
-
使用时间路径的火花写入操作HDFS
我正在尝试从这个Scala代码写入csv文件。我使用HDFS作为临时目录,然后writer.write在现有子文件夹中创建一个新文件。我收到以下错误消息: java.io./tfsdl-ghd-wb/raidnd/Incte_19 如果我选择新建文件或退出文件,也会发生同样的情况,我已经检查了路径是否正确,只想在其中创建一个新文件。 问题是,为了使用基于文件系统的源写入数据,您需要一个临时目录,这
-
基于csv重命名火花数据帧的列名
我有麻烦重命名基于csv的数据帧的标头。 我得到了以下数据帧:df1: 现在我想根据csv文件更改列名(第一行),如下所示: 因此,我期望数据帧如下所示: 有什么想法吗?感谢您的帮助:)
-
RDD火花。违约Spark数据帧的并行等效
Narrow转换(映射、过滤器等)的SparkSQL数据帧是否有“spark.default.parallelism”等价物? 显然,RDD和DataFrame之间的分区控制是不同的。数据帧具有spark。sql。洗牌用于控制分区的分区(如果我理解正确的话,则为宽转换)和“spark.default.parallelism”将没有效果。 Spark数据帧洗牌如何影响分区 但洗牌与分区有什么关系呢?
-
从Kafka读取时如何异步制作火花流
我有一个Kafka分区,和一个parkStreaming应用程序。一个服务器有10个内核。当火花流从Kafka收到一条消息时,后续过程将需要5秒钟(这是我的代码)。所以我发现火花流读取Kafka消息很慢,我猜当火花读出一条消息时,它会等到消息被处理,所以读取和处理是同步的。我想知道我可以异步读取火花吗?这样从Kafka读取的数据就不会被后续处理拖动。然后火花会很快消耗来自Kafka的数据。然后我可
-
向Cassandra写入大火花数据帧-性能调整
我在Spark 2.1.0/Cassandra 3.10集群(4台机器*12个内核*256个RAM*2个SSD)上工作,很长一段时间以来,我一直在努力使用Spark Cassandra connector 2.0.1向Cassandra写入特定的大数据帧。 这是我的表的模式 用作主键的散列是256位;列表字段包含多达1MB的某种结构化类型的数据。总共,我需要写几亿行。 目前,我正在使用以下写入方法
-
如何在火花日志中隐藏密钥密码?
在运行spark作业时,可以在事件日志中以纯文本形式看到SSL密钥密码、keystorepassword。你能帮我如何从日志中隐藏这些密码吗? 当我看到下面的内容时,https://issues.apache.org/jira/browse/spark-16796似乎是他们修复了它,使其不受web UI的影响。但我不确定我能用原木修复它 你的帮助真的很感激!! “{”事件“:”SparkListe
-
代码点火器移除索引。来自url的php
我当前的URL看起来像这个 我想删除从这些URL。 mod_rewrite在apache2服务器上启用。在, 我的代码点火器根文件包含, 但它仍然不起作用。我哪里做错了?