《烽火星空》专题
-
如何安装火焰图生成工具
安装 SystemTap SystemTap 是一个诊断 Linux 系统性能或功能问题的开源软件,为了诊断系统问题或性能,开发者或调试人员只需要写一些脚本,然后通过 SystemTap 提供的命令行接口就可以对正在运行的内核进行诊断调试。 在 CentOS 上的安装方法 首先需要安装当前内核版本对应的开发包和调试包(这一步非常重要并且最为繁琐): # #Installaion: # rpm -i
-
火鸟-插入或更新触发器后
问题内容: 我的数据库中有一个计算,需要在更新触发器之后为“ table1”更新“ field1”。 更新该字段的问题将导致更新后触发器触发并执行冗长的过程并显示错误。 请告知在执行“更新后”触发器之后如何使“ field1”更新,而又不使“更新后”触发器再次执行。 我知道我不能将After触发器与NEW配合使用。 谢谢 问题答案: 可以使用基于上下文变量的自定义锁定机制,以防止重复调用AFTER
-
Service Worker控制器永远不会开火
我想在每次加载页面时向服务人员发送一条消息。 第一次加载页面时,它调用寄存器(),然后侦听navigator.serviceWorker上的“控制器更改”事件,但这永远不会触发。 我如何知道何时可以开始发送邮件给服务人员?
-
Intellij IDEA:火花代码运行导致java.lang.VerifyError
在IntelliJ IDEA中,我试图用spark代码执行一个Java文件,这将产生Java。验证错误。 StackTrace如下所示: 错误执行器:java阶段1.0(TID 2)中任务0.0中出现异常。lang.VerifyError:(class:org/apache/spark/sql/catalyst/expressions/GeneratedClass$SpecificOrdering
-
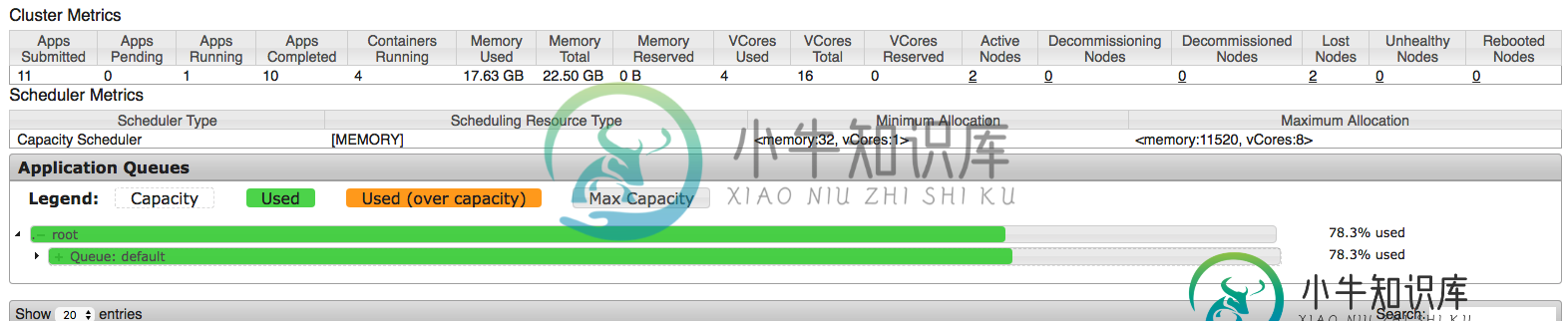 带纱线的火花流应用配置
带纱线的火花流应用配置在配置spark应用程序时,我试图从集群中挤出每一点,但似乎我并没有完全正确地理解每一件事。因此,我正在AWS EMR集群上运行该应用程序,该集群具有1个主节点和2个m3类型的核心节点。xlarge(每个节点15G ram和4个vCPU)。这意味着,默认情况下,每个节点上为纱线调度的应用程序保留11.25 GB。因此,主节点仅由资源管理器(纱线)使用,这意味着剩余的2个核心节点将用于调度应用程序(
-
Azure存储-防火墙和endpoint的使用
我最近在Azure存储中遇到了专用endpoint功能,并试图实现它以从VNet进行安全访问。但是,我在同时使用防火墙、虚拟网络服务endpoint和专用endpoint时遇到了访问问题。 我有两个VNet(VNet1 具有启用了服务endpoint功能的子网的VNet1在存储帐户防火墙中被列入白名单 鉴于上述设置,当我尝试访问位于VNet2下的VM内的此存储帐户Blob容器时,我遇到了授权问题。
-
火花:不支持的类版本错误
我试图在所有节点都安装了Java1.7的集群上使用spark-submit运行java spark作业。 作业失败,返回java.lang.UnsupportedClassVersionError:com/WindLogics/DMF/Wether/MyClass:Unsupported Major.Minor版本51.0。 此外,当主机设置为Local时,作业也可以正常工作。如何进行调试和修复此
-
批之间的流数据共享火花
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
必需:org。阿帕奇。火花sql。一行
我在尝试将spark数据帧的一列从十六进制字符串转换为双精度字符串时遇到了一个问题。我有以下代码: 我无法共享txs数据帧的内容,但以下是元数据: 但当我运行这个程序时,我得到了一个错误: 错误:类型不匹配;找到:MsgRow需要:org.apache.spark.sql.行MsgRow(row.getLong(0),row.getString(1),row.getString(2),hex2in
-
用于火花流的Kafka主题分区
我有一些关于Kafka主题分区->spark流媒体资源利用的用例,我想更清楚地说明这些用例。 我使用spark独立模式,所以我只有“执行者总数”和“执行者内存”的设置。据我所知并根据文档,将并行性引入Spark streaming的方法是使用分区的Kafka主题->RDD将具有与Kafka相同数量的分区,当我使用spark-kafka直接流集成时。 因此,如果我在主题中有一个分区和一个执行器核心,
-
火花流中的状态函数问题
我尝试使用Spark Streaming并希望有一个全局状态对象,可以在每个批处理后更新。据我所知,至少有两种选择适合我:1。使用,其中Spark将在处理每个批处理后自动更新状态2。使用函数,在这里我必须自己调用更新 类型javapairdStream 中的方法updateStateByKey(Function2 ,optional ,optional >)不适用于参数(new function2
-
火花对象不可序列化[重复]
有没有关于为什么整个对象B需要序列化的想法? 关于“对象不可序列化”的异常:
-
多个防火墙(管理员和用户)
我的应用程序需要2个防火墙,一个用于管理员,另一个用于用户。在my security.yml I config中: 我不知道这个配置是否正确。当我从主区域登录时,一切都正常,但当我从管理员登录时,它会将我重定向到主路径,而不是默认的目标路径。我尝试将提供程序更改为自定义提供程序(例如在内存中)以重新检查管理员防火墙,但我仍然通过用户从fos_userbundle提供程序登录。你能帮助我吗?
-
大查询时间火花卡桑德拉
全能的开发者们。我在Spark中运行一些基本的分析,在这里我查询多节点Cassandra。我正在运行的代码以及我正在处理的一些非链接代码是: Spark的版本是1.6.0,Cassandra v3。0.10,连接器也是1.6.0。键空间有,表有5列,实际上只有一行。如您所见,有两个节点(OracleVM中制作的虚拟Macine)。 我的问题是,当我测量从spark到cassandra的查询时间时,
-
Kubernetes-Driver pod上的火花执行失败
我尝试使用Spark2.3本机kubernetes部署特性在kubernetes集群上运行简单的spark代码。 我有一个kubernetes集群在运行。此时,spark代码不读取或写入数据。它创建一个RDD from list并打印出结果,只是为了验证在Spark上运行kubernetes的能力。此外,还复制了kubernetes容器映像中的spark应用程序jar。 2018-03-06 10