《烽火》专题
-
阿帕奇火花移动平均线
-
更好的蜂巢-火花连接?
我正在回顾一个旧的Spark软件,它必须并行运行许多小的查询和计数()并使用直接的hive-sql。 在过去,该软件通过在shell()上直线运行每个查询来解决“并行化查询的问题”。我不能用现代新鲜的Spark,此刻只有Spark V2.2。下面的片段说明了完整的SQL查询方法。 有一种“Spark方式”可以访问Hive并运行SQL查询,性能(略)更好,而且Spark配置的重用性更好? 没有丢失纯
-
火花2.0.2和2.1.1之间的缓存差异
如何在2.1.1中存档相同的行为? 谢谢你。
-
火药中的独特性质
-
在火花中联合后再次排序蜂巢表
我用这些参数启动火花2.3.1的火花外壳: 然后创建两个带有排序和存储桶的蜂箱表 第一个表名-表1 第二个表名-table2 (表2的代码相同) 我希望当我用另一个df连接这些表时,查询计划中没有不必要的交换步骤 然后我关闭广播使用SortMergeJoin 我拿一些df 但当我在连接前对两个表使用union时 在这种情况下出现了排序和分区(步骤5) 如何在不进行排序和交换的情况下合并两个蜂窝表
-
错误没有找到值火花导入spark.implicits._导入spark.sql
我使用hadoop 2.7.2,hbase 1.4.9,火花2.2.0,scala 2.11.8和java 1.8的hadoop集群是由一个主和两个从。 当我在启动集群后运行spark shell时,它工作正常。我正试图通过以下教程使用scala连接到hbase:[https://www.youtube.com/watch?v=gGwB0kCcdu0][1] . 但当我试图像他那样通过添加那些类似
-
与toDF有关的问题是,值toDF不是组织的成员。阿帕奇。火花rdd。RDD
我附加了错误的代码片段“值toDF不是org.apache.spark.rdd.RDD的成员”。我正在使用scala 2.11.8和火花2.0.0。你能帮我解决API toDF()的这个问题吗? }
-
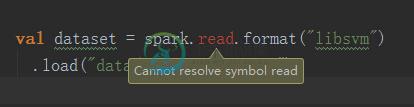 value read不是组织的成员。阿帕奇。火花SparkContext
value read不是组织的成员。阿帕奇。火花SparkContextscala的版本是2.11.8;jdk为1.8;spark是2.0.2 我试图在spark apache的官方网站上运行一个LDA模型的示例,我从以下句子中得到了错误消息: 错误按摩是: 错误:(49,25)读取的值不是组织的成员。阿帕奇。火花SparkContext val dataset=spark。阅读格式(“libsvm”)^ 我不知道怎么解决。
-
火花-从CSV文件中删除标题和拖尾
我正在尝试接收表中的CSV文件,但在此之前,我需要根据头文件和尾文件进行一些验证。 样本数据 现在,在我将数据摄取到表中之前,我需要检查每个拖车记录的记录总数是否为5。 这就是我正在做的正确的事情。 我在想,如果有更好的方法来避免写回文件来创建第二个数据帧。我说的是第五步。 我想从列标题(文件的第二行)最后的数据帧与和?
-
火花数据帧保存AsTable不截断数据从Hive表
我正在使用Spark 2.1.0和Java SparkSession来运行我的SparkSQL。我正在尝试保存一个
-
安装cassandra火花接头
编辑1 当选择正确的scala版本时,它似乎会更进一步,但我不确定下面的输出是否仍然有需要解决的错误:
-
火花广播卡桑德拉连接器
我使用的是datastax提供的spark-cassandra-connector 1.1.0。我注意到了interining问题,我不知道为什么会发生这样的事情:当我广播cassandra connector并试图在执行程序上使用它时,我重复了异常,这表明我的配置无效,无法在0.0.0连接到cassandra。 示例StackTrace:
-
带火花连接器的Cassandra-如何向Cassandra插入项目列表
Java和Scala解决方案都受到欢迎
-
火花流Kafka消费者(Avro)-属性错误:“判决”对象没有属性“分裂”
我正在尝试构建一个Spark流媒体应用程序,该应用程序使用来自Kafka主题的消息,并使用Avro格式的消息,但我在使用合流消息反序列化程序时遇到了一些问题。 按照Spark Python Avro Kafka Deserialiser的说明,我让Kafka消费者正确地反序列化消息,但最终未能运行PythonStreamingDirectKafkaWordCount示例。 代码: 火花提交CLI
-
 如何显示用户数据在导航头从火力恢复数据库在Android Studio
如何显示用户数据在导航头从火力恢复数据库在Android Studio我想显示用户的数据在导航头从文件恢复数据库。我试过这个代码但没用过