《烽火》专题
-
火花:IllegalArgumentException:“不受支持的类文件主版本55”
运行时遇到错误,我尝试了Pyspark error-Unsupported class file major version 55和Pyspark.topandas():'Unsupported class file major version 55'中提到的解决方案,但没有成功。 完整错误日志:
-
在本地机器上安装火花-. getOrCreate火花会话不完成
我已按照以下指南在本地计算机(Windows 10)上安装spark:https://changhsinlee.com/install-pyspark-windows-jupyter/. 从Anaconda启动笔记本并运行时: 它需要很长时间,而且不会完成(至少在60分钟内)。 在此之前,我收到了错误“java-gage-Process-exited-前…”。阅读此内容后:“https://sta
-
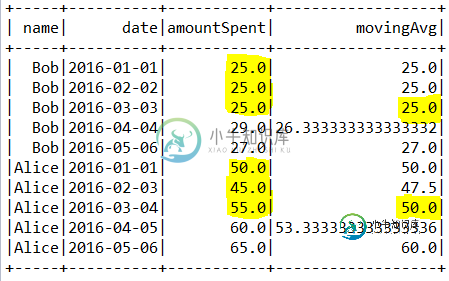 用火花窗函数计算移动平均时丢弃前几个值
用火花窗函数计算移动平均时丢弃前几个值我试图计算按名称分组的列的季度移动平均线,我定义了一个火花窗口函数规范为 我的数据frame如下所示:
-
如何在servlet中处理多文档打开请求火灾
我正在使用servlet,它用于打开文档,如doc、txt、pdf、ppt等。。 我的代码片段如下。 现在,当我试图打开多个文档时,过了一段时间,我会从tomcat服务器上收到断管错误。 我的数据源实现如下。 任何人都可以建议我需要在这个代码中修改什么?
-
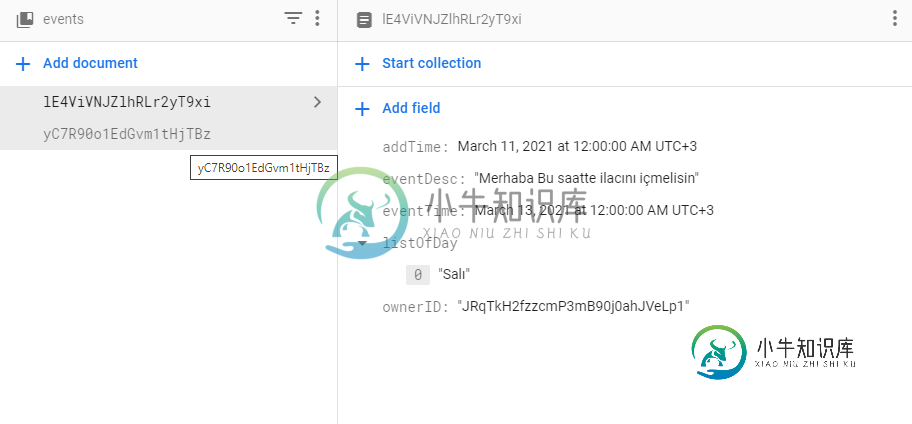 为什么只有1个数据,当我从火基地拉?
为什么只有1个数据,当我从火基地拉?作为未来,我通过查看所有者ID从firebase中提取数据。我没有用小溪。虽然Firebase中有2个数据,但只有一个数据来了,我不明白为什么。 {eventDesc:Merhaba Bu saatte Ilacíníiçmelisin,addtime:Timestamp(秒=1615410000,纳秒=0),listofday:[sal],eventtime:Timestamp(秒=161558
-
 如何优化火花sql并行运行
如何优化火花sql并行运行我是spark新手,有一个简单的spark应用程序,使用spark SQL/hiveContext: 从hive表中选择数据(10亿行) 做一些过滤,聚合,包括row_number窗口函数来选择第一行,分组,计数()和最大()等。 将结果写入HBase(数亿行) 我提交的作业运行它在纱线集群(100个执行者),它很慢,当我在火花UI中查看DAG可视化时,似乎只有蜂巢表扫描任务并行运行,其余的步骤#
-
在Scala火花数据帧DSL API中使用Scal-sql UDF
如何在火花scala数据帧(非文本)api中访问geomesas UDF?即如何转换 如何使sql UDF在scala数据帧DSL中的文本spark sql API中可用?即如何启用而不是此表达式 类似于 如何注册Geomesa UDF,使其不仅适用于sql文本模式<代码>SQLTypes。init(spark.sqlContext)fromhttps://github.com/locationt
-
星星之火中的排序
有一些类似的问题,比如这个和这个,但他们不能给我足够的帮助。下面是我的一段代码。 下面是一段输出。 我想以排序的形式输出。我尝试了
-
如何使用orderby()与降序在火花窗口函数?
我需要一个窗口函数,该函数按一些键(=列名)进行分区,按另一个列名排序,并返回排名前x的行。 这适用于升序: 但当我试图在第4行中将其更改为或时,我得到了一个语法错误。这里的正确语法是什么?
-
火花SQL:选择与算术列值和类型转换?
我将Spark SQL用于数据帧。有没有一种方法可以像在SQL中一样,使用一些算术来执行select语句? 例如,我有以下表格: 现在,我想用SELECT语句创建一个新列,并对现有列执行一些算术运算。例如,我想计算比率。我需要先把价值(或年数)转换成双倍。我试过这句话,但无法解析: 我在“如何在Spark SQL的DataFrame中更改列类型?”中看到了类似的问题,但这不是我想要的。
-
如何分区通过火花中的列并在将数据帧保存在火花scala之前删除相同的列
假设我们有一个列为col1、col2、col3、col4的数据帧。现在,在保存df时,我想使用col2进行分区,并且我将保存的最终df不应该有col2。所以最终的df应该是col1、col3、col4。关于如何实现这一点,有什么建议吗?
-
实时数据库防火墙
-
如何在星火SQL中合并地图列?
我在数据帧中有两个映射类型列。有没有一种方法可以通过使用.withColumn在spark Sql中合并这两个列来创建新的映射列?
-
如何将列表项括在阿帕奇火花中的双引号内
我有一个String变量,其中包含几个用逗号分隔的列名。例如: val temp = "第二列,第三列,第四列" 我有一个Dataframe,我想根据某些列对Dataframe进行分组,其中包括存储在temp变量中的列。例如,我的groupBy语句应该像下面的语句 DF.groupBy(“Col1”、“Col2”、“Col3”、“Col4”) temp变量可以有任何列名。因此,我想创建一个Grou
-
火花中的 Zip 2 列 [重复]
数据帧结构: 预期的数据帧结构: Code_1已尝试: 这也导致错误配对和重复。关于我应该调整什么以获得所需输出的任何建议。 我还尝试在第一条select语句中使用多次爆炸,这将引发错误。 Code_2尝试: 警告和错误: 是的,我问了同样的问题,这个问题被关闭为重复,指向另一个解决方案,这就是我在片段2中尝试的。它也不起作用。任何建议都会很有帮助。