《烽火》专题
-
火花连接:括号问题
我要加入两个rdd。 示例文件1数据: 示例文件2数据: 下面是代码: o/p是k,(v),我想在做进一步处理时去掉值两边的括号。我尝试了一些事情,包括 我还保存了结果: 不幸的是,结果总是以下格式: 我希望他们:
-
(火花偏斜连接)如何在没有内存问题的情况下加入两个具有高度重复密钥的大型Spark RDD?
在前面的问题中,我试图通过避免使用来避免Spark的内存问题。 在这个新问题中,我使用,但试图解决内存问题。 这是我的两个rdd: > < Li > < p > productToCustomerRDD:< br > Size:非常大,可能有数百万个不同的键< br >使用< code>HashPartitioner在键上分区< br >有些键会高度重复,有些则不会。 productToCount
-
两个表连接时的火花性能问题
我有两个大的Hive表,我想用spark.sql将它们连接起来。表格采用snappy格式,在Hive中存储为拼花文件。 我想加入它们并对某些列进行一些聚合,假设计算所有行和一列的平均值(例如 doubleColumn),同时使用两个条件进行过滤(假设在 col1,col2 上)。 注意:我在一台机器上进行测试安装(虽然功能非常强大)。我希望集群中的性能可能会有所不同。 我的第一个尝试是使用spar
-
聚合火花流
我试图从聚合原理的角度来理解火花流。Spark DF 基于迷你批次,计算在特定时间窗口内出现的迷你批次上完成。 假设我们有数据作为- 然后首先对Window_period_1进行计算,然后对Window_period_2进行计算。如果我需要将新的传入数据与历史数据一起使用,比如说Window_priod_new与Window_pperid_1和Window_perid_2的数据之间的分组函数,我该
-
火花加入*无*随机播放
我正在尝试优化我的火花应用工作。 我试图理解这个问题的要点:如何在唯一键上连接数据帧时避免混乱? > 我已经确保必须发生加入操作的键分布在同一分区中(使用我的自定义分区程序)。 我也不能做广播加入,因为我的数据可能会根据情况变大。 在上面提到的问题的答案中,重新分区只优化了连接,但我需要的是无需切换即可连接。在分区内的键的帮助下,我对连接操作很满意。 有可能吗?如果不存在类似的功能,我想实现像jo
-
火花SQL:为什么火花不一直做广播
我在aws s3和emr上使用Spark 2.4进行项目,我有一个左连接,有两个巨大的数据部分。火花执行不稳定,它经常因内存问题而失败。 集群有10台m3.2xlarge类型的机器,每台机器有16个vCore、30 GiB内存、160个SSD GB存储。 我有这样的配置: 左侧连接发生在 150GB 的左侧和大约 30GB 的右侧之间,因此有很多随机播放。我的解决方案是将右侧切得足够小,例如 1G
-
广播加入火花不工作为左外
我有一张小桌子(2k)的记录和一张大桌子(5 mil)的记录。我需要从小表中获取所有数据,只从大表中获取匹配数据,因此我在下面执行了查询
-
什么时候键不能排序排序合并加入火花?
当我读到关于排序合并连接的文章时,它说这是继广播连接之后火花中最首选的一个,但前提是连接键是可排序的。我的问题是什么时候连接键可以不可排序?任何数据类型都可以排序。你能帮我理解一个键可能不可排序的场景吗?
-
火花:如何在所有分区中均匀分配我的记录
我有一个有 30 条记录的 RDD(键/值对:键是时间戳,值是 JPEG 字节数组), 我正在运行 30 个执行器。我想将此 RDD 重新分区为 30 个分区,以便每个分区获得一条记录并分配给一个执行器。 当我使用 30) 时,它会在 30 个分区中重新分区我的 rdd,但有些分区得到 2 条记录,有些得到 1 条记录,有些没有得到任何记录。 在Spark中,有没有什么方法可以将我的记录平均分配到
-
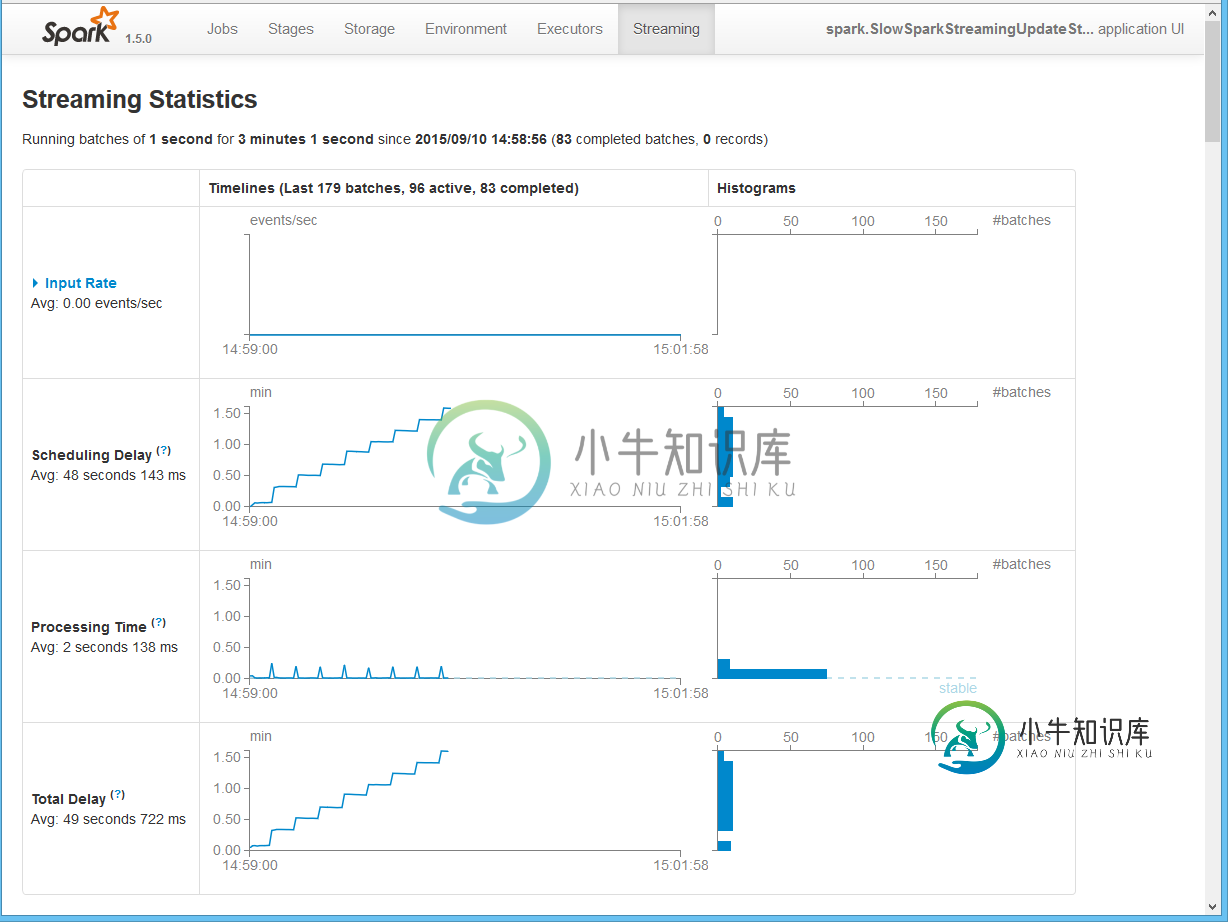 火花流:为什么处理几MB的用户状态的内部处理成本如此之高?
火花流:为什么处理几MB的用户状态的内部处理成本如此之高?根据我们的实验,我们发现当状态变成超过一百万个对象时,有状态的Spark Streaming内部处理成本会花费大量时间。因此,延迟会受到影响,因为我们必须增加批处理间隔以避免不稳定的行为(处理时间 它与我们应用程序的细节无关,因为它可以通过下面的代码复制。 Spark内部处理/基础架构成本到底是什么,需要这么多时间来处理用户状态?除了简单地增加批处理间隔之外,还有什么选项可以减少流转时长吗? 我们
-
火花流:无状态重叠窗口与保持状态
选择无状态滑动窗口操作的一些注意事项是什么(例如,通过updateStateByKey或新mapStateByKey)选择保持状态(例如通过updateStateByKey或新mapStateByKey)时,使用火花流处理连续的有限事件会话流? 例如,考虑以下场景: 一种可穿戴设备跟踪由穿戴者进行的体育锻炼。该装置自动检测何时开始锻炼,并发出信息;在锻炼过程中发出附加信息(如心率);最后,当练习完
-
火花流加入Kafka主题比较
我们需要在Kafka主题上实现连接,同时考虑延迟数据或“不在连接中”,这意味着流中延迟或不在连接中的数据不会被丢弃/丢失,但会被标记为超时, 连接的结果被产生以输出Kafka主题(如果发生超时字段)。 (独立部署中的火花2.1.1,Kafka 10) Kafka在主题:X,Y,...输出主题结果将如下所示: 我发现三个解决方案写在这里,1和2从火花流官方留档,但与我们不相关(数据不在加入Dtsre
-
在完全输出模式下,Spark结构化流是否可以丢弃/控制中间状态?(火花2.4.0)
我有一个场景,我想处理来自kafka主题的数据。我有这个特定的java代码来从kafka主题中读取数据作为流。 我将其转换为 String,定义架构,然后尝试使用水印(用于后期数据)和窗口(用于分组和聚合),最后输出到 kafka sink。 问题 > 我是否正确理解在 kafka 接收器中使用完整输出模式时,中间状态将永远增加,直到我出现内存不足异常? 此外,完整输出模式的理想用例是什么?仅当中
-
不允许火花操作:alter table replace columns
https://docs.databricks.com/spark/latest/spark-sql/language-manual/alter-table-or-view.html#replace-columns
-
火花拼花器读数误差
我在一个Spark项目上工作,这里我有一个文件是在parquet格式,当我试图用java加载这个文件时,它给了我下面的错误。但是,当我用相同的路径在hive中加载相同的文件并编写查询select*from table_name时,它工作得很好,数据也很正常。关于这个问题,请帮助我。 java.io.ioException:无法读取页脚:java.lang.runtimeException:损坏的文