《烽火》专题
-
如何在火花中打开 TRACE 日志记录
我注意到在 Spark 中的规则探索器每次催化剂更改计划时都会执行跟踪日志: https://github . com/Apache/spark/blob/78801881 c 405 de 47 f 7 e 53 EEA 3 e 0420 DD 69593 DBD/SQL/catalyst/src/main/Scala/org/Apache/spark/SQL/catalyst/rules/ru
-
修复火花结构化流中的检查点[重复]
我在生产中遇到检查点问题,当 spark 无法从_spark_metadata文件夹中找到文件时 已经提出了一个问题,但目前还没有解决方案。 在检查点文件夹中,我看到批次29尚未提交,所以我可以从检查点的、和/或中删除一些内容,以防止火花因缺少文件而失败?
-
番石榴/火花问题
我的 Spark 版本是 2.2.0,它在本地工作,但在具有相同版本的 EMR 上,它给出了以下异常。
-
JavaServerSocket防火墙
我有一个服务器写在JavaServerSocket。 我有一个客户端,它位于一个公司防火墙之上,除了公共端口之外,它阻止了所有东西。 我已在SMTP端口(#25)上启动服务器。 有防火墙的用户连接到它,到目前为止一切正常。 然后服务器处理ServerSocket.accept()。据我所知,它在一个随机端口上创建一个套接字(每次端口号都不同)。因为防火墙而失败。 我的问题是-如何制作ServerS
-
数组代码点火器从数据库中提取结果
我有一个食物表,在那里我存储分类ID作为coma分开,如下面的图像食物表 我在模型中做了一个方法,它以数组(类别ID)为参数,从参数中获取与数组ID匹配的食物项。 我做了以下查询 下面是上面查询的结果 我得到了重复的结果,我认为这也可能导致性能问题。 以下是当我只有一个类别的食物给我期望的结果时的查询。 请帮帮忙。
-
用于火灾和遗忘模型的Spring Cloud网关过滤器工厂
我正在探索Spring Cloud网关过滤器工厂,它可以接受请求并将SUCCESS超文本传输协议状态返回给调用者。之后,根据过滤器出厂配置将其转发到目的地。 我在Spring doc中没有找到任何解决方案。有没有现有的过滤器工厂来实现这种模式?如果没有,那么有什么建议如何解决这个问题? 注意:我们想要中断Spring Cloud Gateway通信的原因是目标服务器响应时间非常高,呼叫者不能等待那
-
对存储在卡桑德拉数据库上的 JSON 对象进行查询火花
我在cassandra DB上构建了结构来存储操作系统数据的时间序列数据,如服务、进程和其他信息。为了理解如何使用Cassandra来存储JSON数据并通过条件的CQL查询检索数据,我倾向于简化模型。因为在整个模型数据库中,我将拥有比report_object更复杂的类型,如hashMap数组的hashMap,例如:Type
-
火花访问行对象值
我想通过分区迭代一个dataframe,对于每个分区,迭代它的所有行,并创建一个deleteList,它将包含HBase的每一行的delete对象。我将Spark和HBase与Java一起使用,并使用以下代码创建了一个行对象: 但它无法工作,因为我无法正确访问行的值。而df有一个名为“hbase_key”的列。
-
无法解码火力库 JWT
我正在创建一个网络应用程序,我想实现Firebase身份验证,并帮助用户使用谷歌,脸书或推特登录。 用户在我的网站上使用Firebase登录,我在Javascript中收到登录信息。 根据Firebase留档,我没有传递JS中接收到的UID,而是将令牌ID发送到后端服务器,以便它可以验证源并检索用户ID。 我使用PHP-JWT来检查和验证Firebase返回的令牌。但是,标题中的< code>Ke
-
在火狐上按下浏览器的后退按钮后,旋转加载图像
我有这样的div标签 并且脚本将在每次单击“a”标记时运行 每当点击<代码> 谢谢:)
-
加载资源失败:服务器响应的状态为404(找不到)?后置http://localhost:3000/login 404(找不到)?火药反应
登录名%1无法加载资源:服务器在提交表单时以404(未找到)axios firebase react js状态响应。而且这个错误在firebase函数日志上也好心有人帮我...登录%1加载资源失败:服务器响应的状态为404(找不到)请检查在提交
-
Spark java。木卫一。InvalidClassException:org。阿帕奇。火花不安全的类型。UTF8字符串;本地类不兼容
我试图在远程群集上运行Spark应用程序,但遇到序列化错误。Scala和Spark版本是相同的。我被困在这一点上了。 spark shell-群集上的版本: 建筑sbt 堆栈跟踪:
-
无法连接谷歌存储文件使用GSC连接器从火花
我写了一个火花作业在我的本地机器,从谷歌云存储读取文件使用谷歌hadoop连接器,如gs://storage.googleapis.com/https://cloud.google.com/dataproc/docs/connectors/cloud-storage 我已经设置了具有计算引擎和存储权限的服务号。我的火花配置和代码是 我已经设置了环境变量也称为GOOGLE_APPLICATION_C
-
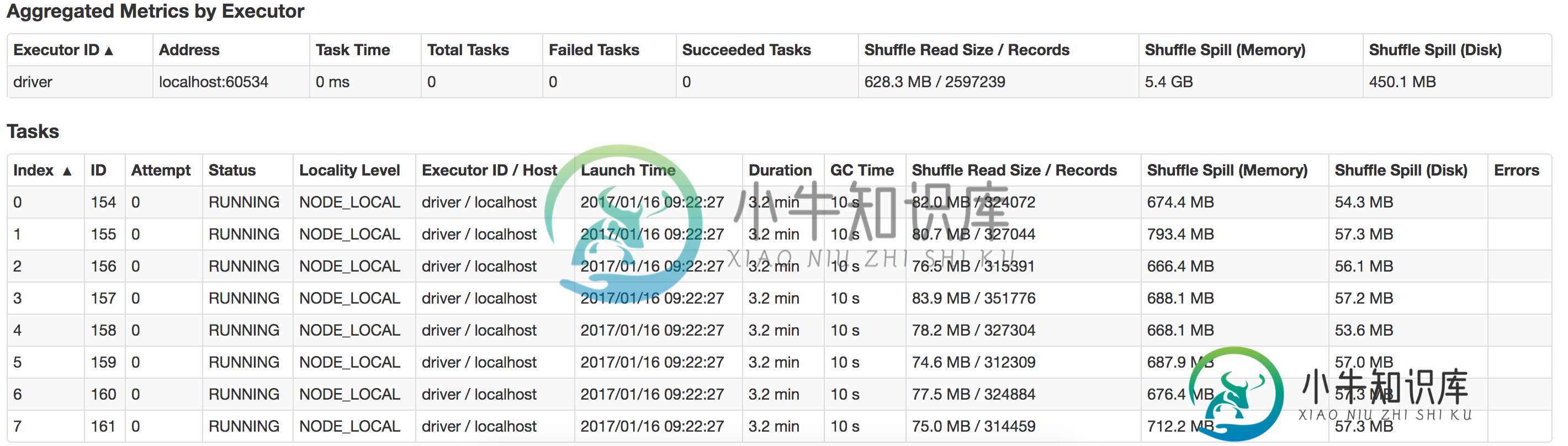 火花驱动程序内存和执行器内存
火花驱动程序内存和执行器内存我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
 闲置的火花工人
闲置的火花工人我已经配置了连接到Cassandra集群的独立spark集群,其中有1个主服务器、1个从服务器和Thrift服务器,该服务器用作Tableau应用程序的JDBC连接器。无论怎样,当我启动任何查询时,从属服务器都会出现在工作者列表中。所有工作负载都由主执行器执行。同样在Thrift web控制台中,我观察到只有一个执行器处于活动状态。 基本上,我希望火花集群的两个执行器上的分布式工作负载能够实现更高