《烽火》专题
-
火花:向csv文件添加列名失败
然后我跑: 然后我得到: IllegalArgumentException:需求失败:列数不匹配。旧列名(1):值新列名(5):startIP,endIP,City,Longitude,Latitude at scala.predef$.require(predef.scala:224)at org.apache.spark.sql.dataset.todf(dataset.scala:376)a
-
在火花中读取csv时防止分隔符碰撞
如何捕捉此字段中的而不将其视为CSV分隔符?
-
自定义分隔符csv读取器火花
我想用Apache Spark读入具有以下结构的文件。 csv太大了,不能使用熊猫,因为读取这个文件需要很长时间。有什么方法类似于 多谢!
-
避免石英失火
我面临着石英和缺火的痛苦问题。 我的应用程序创建允许用户创建CronTrigger和SimpleTrigger作业。 每个作业都可以暂停/恢复(使用Scheduler.pauseJob和Scheduler.resumeJob) 调度程序本身可以设置为待机。 我们希望放弃任何缺火: 当调度程序处于待机状态时 作业暂停时 当应用程序停止时 正如在这篇博文中所解释的http://www.nurkiewi
-
为什么火花提交失败的'spark.yarn.stagingDir'与主纱线和部署模式集群
我在提供spark.yarn时遇到了一个场景。stagingDir(stagingDir)到spark submit(spark提交)开始失败,它没有给出任何关于根本原因的线索,我花了很长时间才弄清楚这是因为spark.yarn(spark.yarn)。stagingDir参数。为什么spark submit在supply此参数? 在此处查看相关问题以获取更多详细信息 失败的命令: 当我移除火花线
-
打开CentOS 7上的防火墙端口[关闭]
那么如何打开端口并使其在重启后存活呢?
-
如何使用Selenium禁用火狐的不可信连接警告?
试图找到一种方法来禁止Firefox在每次连接使用“不受信任”证书时发出警告,使用Selenium。我认为最好的解决方案是设置浏览器首选项之一。
-
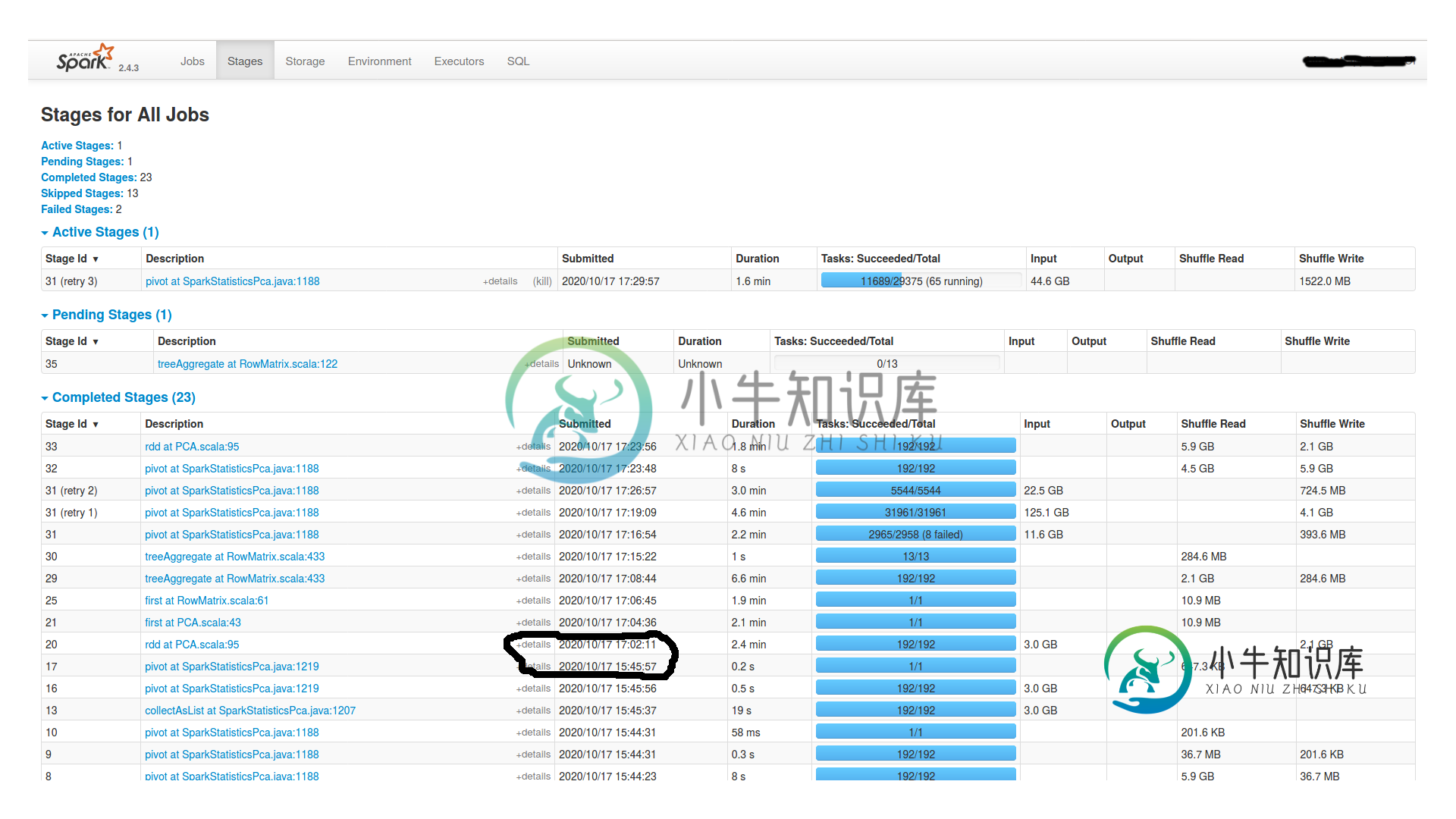 火花工作之间的巨大时间间隔
火花工作之间的巨大时间间隔我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
如何更改avast防火墙设置以允许maven下载所需的插件?
null
-
Elasticsearch RestHighLevelClient通过代理在公司防火墙后
我正在尝试从我们的网络访问cloud Elasticsearch安装,这需要使用外部请求的代理。这是我用来传递Elasticsearch凭据和代理设置的代码片段: CredentialsProvider CredentialsProvider=new BasicCredentialsProvider();CredentialsProvider.SetCredentials(AuthScope.An
-
星火从未停止第一批加工
我正在尝试运行我在github上找到的一个应用程序,这个应用程序是:https://github.com/csirt-mu/aida-framework 编辑:我注意到当进程启动时会记录错误。我现在才意识到这一点,因为这个过程不会停止。错误有: 有人能帮我解决这些错误吗?
-
UFW防火墙后的Elasticsearch聚类
-
火花流后立即使用火花RDD过滤器
我正在使用火花流,我从Kafka读取流。阅读此流后,我将其添加到hazelcast地图中。 问题是,我需要在读取Kafka的流之后立即从地图中过滤值。 我正在使用下面的代码来并行化地图值。 但在这个逻辑中,我在另一个逻辑中使用JavaRDD,即JavaInputDStream.foreachRDD,这会导致序列化问题。 第一个问题是,如何通过事件驱动来运行spark作业? 另一方面,我只是想得到一
-
龙目岛不在月蚀火星上工作
我有eclipse版本:“Mars Release(4.5.0)” 我从https://projectlombok.org/download.html下载了最新的龙目岛罐子 我执行: 在此之后,我可以看到lombok.jar在我的eclipse目录和eclipse.ini. 使用:eclipse-clean重新启动eclipse 但龙目岛仍然不适合我。
-
获得空指针异常时,试图添加一列火花数据集在Java
我试图在java中迭代数据集行,然后访问特定的列,找到它作为键存储在JSON文件中的值,并获取它的值。对于所有行,找到的值需要作为新列值存储在该行中。 我看到我从JSON文件中获得的不是空的,但当我尝试将其添加为列时,我在线程“main”组织中得到了 到目前为止,我有: 因此,我主要需要帮助逐行读取数据集,并执行上述后续操作。无法在网上找到太多参考资料。如果可能的话,请告诉我正确的来源。另外,如果