《烽火》专题
-
石英作业通常不着火
我在Maven/war项目中使用了quartz 2.2.1和Spring 3.2.5。 我的WAR文件在Apache-Tomcat-7.x下部署良好,日志表明所有quartz作业都已加载。麻烦就从这里开始。 有人能解释一下发生了什么吗?在我看来,根本不应该有任何遗漏的触发器。 多谢了。
-
带有火花流集成错误的kafka
我不能用火花流运行Kafka。以下是我迄今为止采取的步骤: > 将此行添加到- Kafka版本:kafka_2.10-0.10.2.2 Jar文件版本:spark-streaming-kafka-0-8-assembly_2.10-2.2.0。罐子 Python代码: 但我仍然得到以下错误: 我做错了什么?
-
我的防火墙阻止了docker容器与外界的网络连接
对我来说,这是一个非常标准的设置,我有一台运行docker和ufw的ubuntu机器作为我的防火墙。 如果我的防火墙处于启用状态,则 Docker 实例无法连接到外部 下面是 ufw 日志,显示来自 docker 容器的已阻止连接。 我尝试使用ip添加规则。 而且毫无变化依然受阻。 如何使用 ufw 规则允许从容器到外部的所有连接?
-
Kinesis流和Kinesis火管更新弹性搜索指标
我们希望使用kinesis stream和firehose来更新aws管理的elasticsearch集群。我们有数百个不同的索引(对应于我们的DB碎片)需要更新。当创建firehose时,它要求我指定我想要更新的特定索引名。这是否意味着我需要为集群中的每个索引创建一个单独的消防水管?或者是否有一种方法来配置firehose,以便它知道基于数据内容使用什么索引。 此外,我们将有大约20个独立的生成
-
火花读阿夫罗
正在尝试读取avro文件。 无法将运行到Avro架构的数据转换为Spark SQL StructType:[“null”,“string”] 尝试手动创建架构,但现在遇到以下情况: 通用域名格式。databricks。火花阿夫罗。SchemaConverters$CompatibleSchemaException:无法将Avro架构转换为catalyst类型,因为路径处的架构不兼容(avroTyp
-
Debian防火墙阻止Minecraft服务器端口
我怎样才能禁用Debian的保护来允许外部玩家加入我的服务器?
-
云火如何找到包含特定文档ID的子集合的所有文档?
我试图实现一种在Firestore中保持一致性的方法,但我需要一种找到重复数据存在的所有位置的方法。firestore中是否有方法查找其子集合包含具有特定文档ID的文档的所有文档?例如对于以下结构 我将使用什么查询来查找其“朋友”列表包含文档 ID 为 5678 的文档的所有用户 ID?例如,当用户 5678 决定更改他/她的姓名时?
-
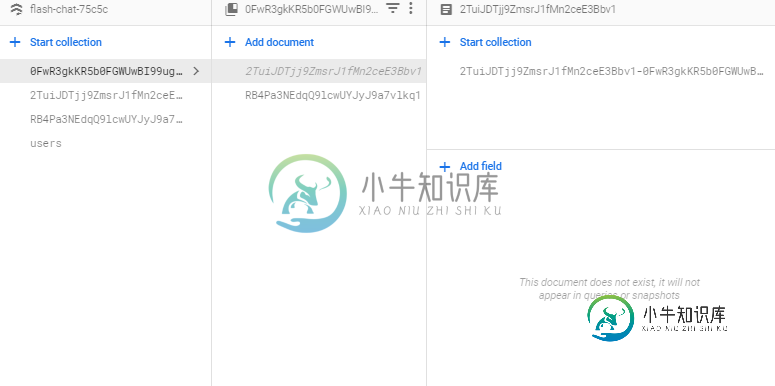 如何比较火库颤振应用中的两个集合?
如何比较火库颤振应用中的两个集合? -
日食火星太慢了。总是忙于扫描类路径
我正在使用eclipse mars 4.5。问题是,它总是忙于扫描类路径,这实际上使eclipse的工作速度太慢。我正在处理多模块OSGI项目,因此工作区中大约有30个项目,eclipse每次都开始扫描所有项目的类路径。
-
火花-我读csv正确吗?
我使用以下方法将csv文件读入Spark: df=spark.read.format(file_type).options(header='true',quote='\"',ignoreleadingwhitespace='true',inferschema='true').load(file_location) 这是正常行为还是读错了? 更新:我将标记问题作为回答,因为下面的提示是有用的。然而,
-
火花分区数据多个文件
我有5个表存储为CSV文件(A.CSV、B.CSV、C.CSV、D.CSV、E.CSV)。每个文件按日期分区。如果文件夹结构如下:
-
火花CSV逃逸不工作
我使用spark-core 2.0.1版和Scala2.11。我有一个简单的代码来读取一个包含\escapes的csv文件。 null 有人面临同样的问题吗?我是不是漏掉了什么? 谢谢
-
火花DF。选择返回带有标题的csv的不正确列
我正在实现Spark数据源API v1的buildScan方法。 我正在尝试读取一个带有标题的。csv文件。 但是buildScan()内部的df.show返回正确的列。 我无法找到列映射到底哪里出错了。
-
 按列进行火花重新分区,每个列的分区数是动态的
按列进行火花重新分区,每个列的分区数是动态的如何根据列中项数的计数来分区DataFrame。假设我们有一个包含100人的DataFrame(列是和),我们希望为一个国家中的每10个人创建一个分区。 如果我们的数据集包含来自中国的80人,来自法国的15人,来自古巴的5人,那么我们需要8个分区用于中国,2个分区用于法国,1个分区用于古巴。 下面是无法工作的代码: null 有什么方法可以动态设置每个列的分区数吗?这将使创建分区数据集变得更加容易
-
如何使用AWS胶水/火花将S3中的CSVs分区和分割转换为分区和分割拼花地板
我如何使用胶水/火花转换成拼花,这也是分区的日期和分裂在n个文件每天?。这些示例不包括分区、拆分或供应(多少节点和多大节点)。每天包含几百GBS。 因为源CSV不一定在正确的分区中(错误的日期),并且大小不一致,所以我希望用正确的分区和更一致的大小写到分区的parquet。