《烽火》专题
-
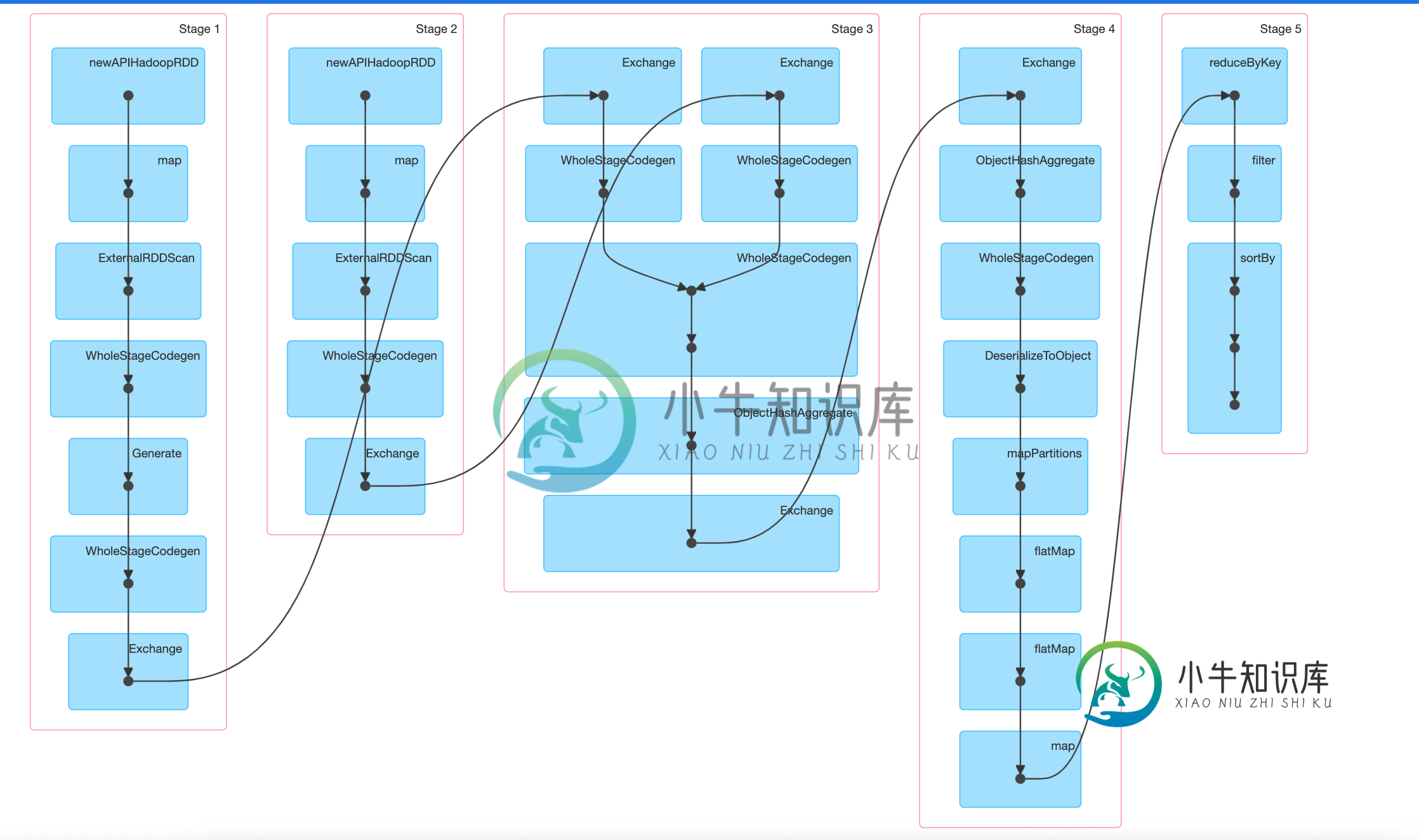 连接后在各阶段之间卡住的火花作业
连接后在各阶段之间卡住的火花作业我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘
-
执行器核心数和利益或其他-火花
需要进行一些运行时澄清。 在我读到的其他地方的一个线程中,有人说Spark Executor应该只分配一个核心。然而,我想知道这是否真的永远是真的。阅读各种so问题和诸如此类的问题,以及Karau、Wendell等人的著作,可以清楚地看到,有相同或相反的专家指出,在某些情况下,每个执行者应该指定更多的内核,但讨论往往更多的是技术性的,而不是功能性的。也就是说,缺少功能性的例子。 > 我的理解是RD
-
如果否,如何处理火花RDD分区。执行者数
我想了解火花流中的一个基本的东西。我有50个Kafka主题分区和5个执行者的数字,我正在使用DirectAPI所以没有。的RDD分区将为50个。这个分区将如何在5个执行器上处理?将在每个执行器上一次触发进程1个分区,或者如果执行器有足够的内存和内核,它将在每个执行器上并行处理超过1个分区。
-
火花中的任务是什么?Spark worker如何执行jar文件?
在阅读了http://spark.apache.org/docs/0.8.0/cluster-overview.html上的一些文档之后,我得到了一些我想澄清的问题。 以Spark为例:
-
火花加载CSV文件作为数据帧?
我想在spark中读取一个CSV,将其转换为DataFrame,并使用将其存储在HDFS中 在Apache Spark中将CSV文件加载为DataFrame的正确命令是什么?
-
 docker中的火花,为驱动程序/执行程序设置内存
docker中的火花,为驱动程序/执行程序设置内存我在一个单独的Docker中运行spark-master和spark-worker。 我能看见他们在跑 PS-EF grep火花根3477 3441 0 1 05?00:04:17/usr/lib/jvm/java-1.8-openjdk/jre/bin/java-cp/usr/local/spark/conf/:/usr/local/spark/jars/*-xmx1g org.apache.s
-
火狐浏览器打开后一秒关闭,忽略场景
我的控制台: RG.OpenQA.Selenium.Remote.UnreachableBrowserException:无法启动新会话。可能的原因是远程服务器地址无效或浏览器启动失败。生成信息:版本:“3.4.0”,修订版:“Unknown”,时间:“Unknown”系统信息:主机:“WS00MU016”,IP:“”,OS.Name:“Windows 10”,OS.ARCH:“AMD64”,OS
-
火花运行错误java.lang.NoClassDefFoundError: org/codehaus/jackson/annotate/JsonClass
自从有人提到Spark-jackson冲突问题以来,我使用mvn版本重建了Spark:使用最新版本-Dincludes=org。科德豪斯。jackson:jackson core asl mvn版本:使用最新版本-Dincludes=org。科德豪斯。jackson:jackson mapper asl 因此,JAR已更新为1.9。但我仍然有错误
-
每周特定日期的火灾报警
我正在制作一个应用程序,让用户选择几天,并在这些天的特定时间启动警报。 让我们以我的问题为例,我希望我的闹钟在每周五12:30触发,问题是它从来没有触发过闹钟,即使我在同一天,这是我的代码
-
通过边界防火墙从本地服务器使用gsutil连接到谷歌云存储
我试图使用gsutil从本地linux服务器连接到谷歌云平台存储(桶)。我们有一个边界防火墙,需要打开才能连接到云存储。防火墙团队正在询问带有端口的目的地详细信息。 例如:通过gs实用程序,如果我想下载或上传文件,我使用命令gsutil cp test。txt gs://testbucket 谢谢,Sahayam。J
-
火花映射变换
我是新的火花,请帮助我这一点。
-
火星探测车的简单例子
机器人从坐标(0,0)开始,同时指向北方。 用户输入=字符串,例如lrlllfrrrfrf。这里L=左点,R=右点,F=向前移动一个单位 输出=(5,6)=机器人的最终坐标 我使用Java Scanner类从用户那里获取输入。但输出是空白的。以下是我的完整代码: 我做错了什么?请帮点忙。
-
获取火存储参考数据
我刚开始使用firebase作为我的Flatter应用程序的后端,我有一个问题:如何将两个文档链接在一起,同时获取这两个数据。例如,我有一个用户集合和一个帖子集合。我如何链接这两个文档,当我获取帖子数据时,我也会在相同的响应中获取用户数据
-
解析日期并在火灾数据存储上应用查询
我在fire data store中有以下集合,希望在获取集合之前对集合应用以下查询。 什么是最正确的过滤这些在Javaadroid.
-
 StorageException已发生。对象的位置不存在。存储型火库
StorageException已发生。对象的位置不存在。存储型火库更新,存储FireBase中的映像