《烽火》专题
-
火花Scala编程为不可序列化的对象和功能
当我运行Spark Scala程序时,有一个“Task not serializable”异常 Spark RDD是不可串行化类型(java类) 调用的函数来自不可序列化的类(java类,再次) 我的代码是这样的 我注意到我可以用 但对于RDD中的对象类,我仍然会遇到这个例外。我会以另一种方式,也会以另一种方式,也就是第二部分,因为我不想创建大量PredicateClass的对象。 你能帮我吗?我
-
带序列化的Scala反射(过火花)-符号不可序列化
首先,我使用的是scala 2.10.4,上面的例子是在Spark 1.6中运行的(尽管我怀疑Spark与此有关,但这只是一个序列化问题)。 所以我的问题是:假设我有一个trait,它由两个类实现,比如说和。现在,我有一个泛型特征,它由一组类扩展,其中一个类位于的子类型之上,例如(这里我保留了Spark对RDD的概念,但一旦序列化,它实际上可能是另一个类;不管实际情况如何,它都只是一个结果): 现
-
火花阿夫罗到镶木地板
我有一个avro格式的数据流(json编码),需要存储为镶木地板文件。我只能这样做, 把df写成拼花地板。 这里的模式是从json中推断出来的。但是我已经有了avsc文件,我不希望spark从json中推断出模式。 以上述方式,parquet文件将模式信息存储为StructType,而不是avro.record.type。是否也有存储avro模式信息的方法。 火花 - 1.4.1
-
火花:阿夫罗与镶木地板的表现
现在Spark 2.4已经内置了对Avro格式的支持,我正在考虑将数据湖中某些数据集的格式从Parquet更改为Avro,这些数据集通常是针对整行而不是特定列聚合进行查询/联接的。 然而,数据之上的大部分工作都是通过Spark完成的,据我所知,Spark的内存缓存和计算是在列格式的数据上完成的。在这方面,Parquet是否提供了性能提升,而Avro是否会招致某种数据“转换”损失?在这方面,我还需要
-
组织。阿帕奇。火花SparkException:任务不可序列化。斯卡拉火花
将现有应用程序从Spark 1.6移动到Spark 2.2*(最终)会导致错误“org.apache.spark.SparkExctive:任务不可序列化”。我过于简化了我的代码,以演示同样的错误。代码查询拼花文件以返回以下数据类型:“org.apache.spark.sql.数据集[org.apache.spark.sql.行]”我应用一个函数来提取字符串和整数,返回字符串。一个固有的问题与Sp
-
如何在火花日志中隐藏密钥密码?
在运行spark作业时,可以在事件日志中以纯文本形式看到SSL密钥密码、keystorepassword。你能帮我如何从日志中隐藏这些密码吗? 当我看到下面的内容时,https://issues.apache.org/jira/browse/spark-16796似乎是他们修复了它,使其不受web UI的影响。但我不确定我能用原木修复它 你的帮助真的很感激!! “{”事件“:”SparkListe
-
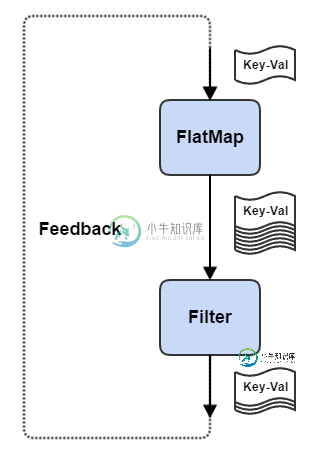 火花流:如何将输出反馈到输入
火花流:如何将输出反馈到输入更新:为了迭代支持,我不得不转向Flink流。不过还是会和Kafka试试看!
-
使用--files或Spark.files将配置文件从驱动程序复制到执行程序时,火花kubernetes-fileNotFoundException
我们正在将Spark工作负载从Cloudera迁移到Kubernetes。 出于演示目的,我们希望在集群模式下使用spark-submit在minikube集群中运行一个spark作业。 我想使用spark.file conf将一个类型安全配置文件传递给我的执行程序(我也尝试了--files)。配置文件已在生成时复制到/opt/spark/conf目录下的spark docker映像中。 然而,当
-
Firebase火力恢复读取计数?
Firebase Firestore的成本基于读取操作的数量。如果我下载一个包含不止一个子文档的高级文档(比如下载一个在Firebase实时数据库中包含不止一个子节点的父节点)。)那么会被认为是单读还是多读呢?我在文档中没有找到任何关于这一点的内容。请解释一下?
-
火库安全规则运营费
我最近考虑了我的Firebase服务的各种安全问题,并面临一个与Firebase定价相关的有趣问题。问题很简单,如下所示: > 如果实时数据库的一组安全规则在安全规则的验证过程中读取其自身(rtdb)中的一些数据,则此类用于验证目的的服务器读取是否受rtdb计费的任何部分的约束?例如,如果一行规则需要匹配的rtdb的json树中的“角色”数据,那么这种验证是否不受rtdb的下载费定价($1/GB)
-
在防火墙后使用Jaspersoft Studio中的webservices
我在Jaspersoft工作室工作。我正在尝试使用来自Jasper Studio的webservice。我在公司防火墙后面工作。我尝试使用的webservice是HTTPS。我收到SSL证书错误。有没有人可以建议我如何在Jaspersoft Studio中忽略SSL认证并使用https webservice。 JasperReports Server CP 5.1.0 JasperSoft stu
-
Kubernetes-Driver pod上的火花执行失败
我尝试使用Spark2.3本机kubernetes部署特性在kubernetes集群上运行简单的spark代码。 我有一个kubernetes集群在运行。此时,spark代码不读取或写入数据。它创建一个RDD from list并打印出结果,只是为了验证在Spark上运行kubernetes的能力。此外,还复制了kubernetes容器映像中的spark应用程序jar。 2018-03-06 10
-
如何发送一个工作在库伯内特斯的火花。无法实例化外部计划程序
2019-03-13 18:26:57错误sparkcontext:91-初始化sparkcontext时出错。org.apache.spark.sparkexception:无法在org.apache.spark.sparkcontext$.org$apache$spark$sparkcontext$$createTaskscheduler(Sparkcontext.scala:2794)...
-
Windows群集上的火花程序失败,错误CreateProcess error=5,访问被拒绝
我试图在我的Windows10笔记本电脑上的Spark V2.0.0集群上执行一个程序。端口31080上有一个主节点,端口32080上有一个从节点。集群使用独立管理器,并使用JDK1.8,从服务器有一个自定义工作目录。 当通过spark-submit或Eclipse>Run程序提交程序时,我会得到以下错误,执行器进入一个循环(创建了一个新的执行器,并且连续失败)。请引导。 请求删除执行人0
-
防火墙背后的Apache背后的Tomcat:AJP忽略X-Forwarded-Proto
防火墙:终止https,添加“x-forwarded-proto:https”,通过http转发到Apache Apache:通过ajp转发到Tomcat Tomcat:通过ajp-connector接收请求 我们已经将RemoteIpValve添加到Tomcat的server.xml中: 如果我们跳过Apache,直接从防火墙转到使用常规HTTP连接器的Tomcat,它就可以工作。在这种情况下,