《烽火》专题
-
如何通过索引从火花数据帧中删除列,其中列名可以重复?
我有一个火花数据帧,只想删除最后一列。 我试过了 但出现错误:“list”对象没有属性“last”。 我还尝试了: 但这会删除所有与last同名的列。 使用Spark 2.4
-
如何解析CSV字符串到火花数据帧使用scala?
我想将包含字符串记录的RDD转换为Spark数据帧,如下所示。 模式行不在同一个中,而是在另一个变量中: 所以现在我的问题是,我如何使用上面两个,在Spark中创建一个数据帧?我使用的是Spark 2.2版。 我确实搜索并看到了一篇帖子:我可以使用spack-csv将表示为字符串的CSV读取到Apache Spark中吗?然而,这并不是我所需要的,我也无法找到一种方法来修改这段代码以在我的情况下工
-
PySpark火花与库伯内特斯大师会话生成器
我最近看到一个pull请求被合并到Apache/Spark存储库中,该存储库显然为K8s上的PySpark添加了初始Python绑定。我在公关上发表了一条评论,问了一个关于如何在Python Jupyter笔记本中使用spark-on-k8s的问题,并被告知在这里问我的问题。 我的问题是: 有没有办法使用PySpark的主控设置为
-
是否可以在火花中并行地在单个数据帧上运行多个聚合作业?
有没有办法在单个RDD上并行运行多个独立的聚合作业?首选是Python,然后是Scala和Java。 按优先顺序排列的行动过程是- > 在纱线上使用集群模式,提交不同的罐。这可能吗?如果可能,那么pyspark中是否可能? 使用Kafka-在通过kafka流式传输的数据帧上运行不同的火花提交。 我是Spark的新手,我的经验范围是在ETL上运行Spark on Yarn以串行方式进行多个聚合。我在
-
你怎么写一个数据帧/RDD与自定义分隔符(ctrl-A分隔)文件在火花scala?
我正在处理poc,我需要在其中创建数据帧,然后将其保存为ctrl分隔的文件。下面是我创建中间结果的查询 将结果保存在文本文件中 输出: 它将数据保存为逗号分隔,但我需要将其保存为ctrl-A单独我尝试了选项(“分隔符”、“\u0001”),但它似乎不受dataframe/rdd的支持。 有什么帮助的功能吗?
-
使用时间路径的火花写入操作HDFS
我正在尝试从这个Scala代码写入csv文件。我使用HDFS作为临时目录,然后writer.write在现有子文件夹中创建一个新文件。我收到以下错误消息: java.io./tfsdl-ghd-wb/raidnd/Incte_19 如果我选择新建文件或退出文件,也会发生同样的情况,我已经检查了路径是否正确,只想在其中创建一个新文件。 问题是,为了使用基于文件系统的源写入数据,您需要一个临时目录,这
-
基于csv重命名火花数据帧的列名
我有麻烦重命名基于csv的数据帧的标头。 我得到了以下数据帧:df1: 现在我想根据csv文件更改列名(第一行),如下所示: 因此,我期望数据帧如下所示: 有什么想法吗?感谢您的帮助:)
-
 如何在EMR上调整火花作业以在S3上快速写入大量数据
如何在EMR上调整火花作业以在S3上快速写入大量数据我有一个很好的工作,我在两个数据帧之间进行外部连接。第一个数据帧的大小为260 GB,文件格式为文本文件,分为2200个文件,第二个数据帧的大小为2GB。然后,将大约260 GB的数据帧输出写入S3需要很长的时间,因为我在EMR上做了很大的更改,所以我取消了这一操作,之后的2个多小时。 这是我的集群信息。 这是我正在设置的群集配置 我尝试设置内存组件手动也像下面和性能是更好的但同样的事情它是再次采
-
RDD火花。违约Spark数据帧的并行等效
Narrow转换(映射、过滤器等)的SparkSQL数据帧是否有“spark.default.parallelism”等价物? 显然,RDD和DataFrame之间的分区控制是不同的。数据帧具有spark。sql。洗牌用于控制分区的分区(如果我理解正确的话,则为宽转换)和“spark.default.parallelism”将没有效果。 Spark数据帧洗牌如何影响分区 但洗牌与分区有什么关系呢?
-
在火花scalaGroupByKey($"coll")和GroupBy($"coll")之间的区别
当我使用DF的列名作为参数时,与使用和有什么根本区别? 哪一个是省时的,每一个的确切含义是什么?当我通过一些例子时,请有人详细解释一下,但这是令人困惑的。
-
火花2。x数据帧或数据集?[副本]
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
火花createDataFrame()不使用Seq RDD
CreateDataFrame接受2个参数,一个rdd和模式。 我的图式是这样的 <代码>val schemas=结构类型(Seq(StructField(“number”,IntegerType,false),StructField(“notation”,StringType,false))) 在一种情况下,我能够从RDD创建数据帧,如下所示: 在以下其他情况下。。我不能 data2不能成为Da
-
 Cassandra火花连接器读取性能
Cassandra火花连接器读取性能我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码: 所有3个参数都是表上键的一部分: 主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generat
-
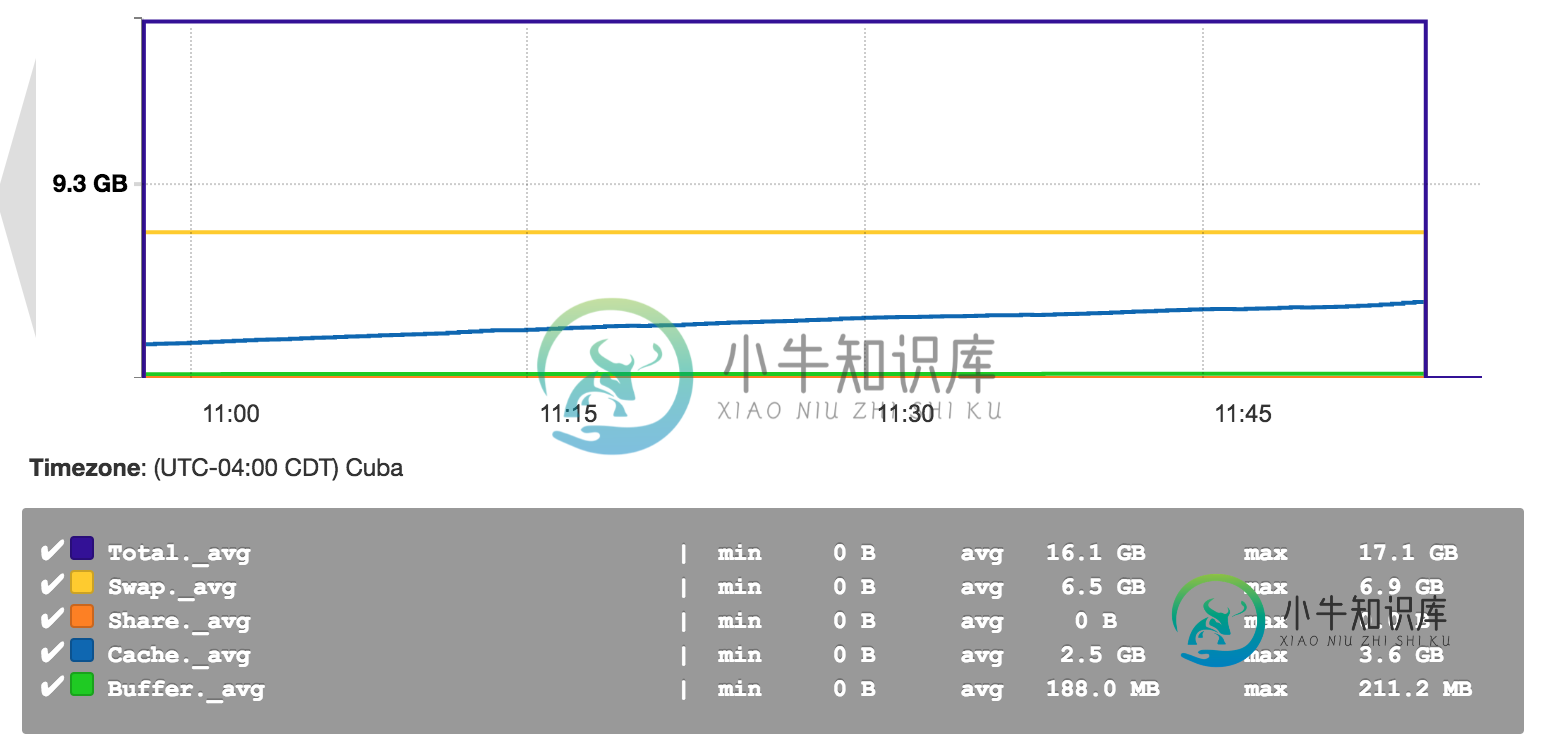 火花集群的Ambari仪表板内存使用说明
火花集群的Ambari仪表板内存使用说明我使用Ambari来监视我的spark群集,我对所有的内存类别都有点困惑;有专业知识的人能解释一下这些术语的含义吗?提前感谢! 以下是Ambari内存使用率缩小的屏幕截图: 基本上,交换、共享、缓存和缓冲区的内存使用代表什么?(我想我完全理解了)
-
火花内存不足错误
我的spark程序在小数据集上运行良好。(大约400GB)但是当我将其扩展到大型数据集时。我开始得到错误