《烽火》专题
-
星火结构化流-如何忽略检查点?
我正在使用微批处理()从Kafka stream读取消息,处理消息并通过将结果写入另一个Kafka主题。该作业(流式查询)被设计为“永远”运行,处理大小为10秒(处理时间)的微批。已设置选项,因为Spark需要检查点。
-
从Kafka消费,使用Kafka方法和火花流给出了不同的结果
我正在尝试使用spark Streaming从Kafka中消耗一些数据。 我创造了2个工作岗位, 一个简单的Kafka作业,它使用:
-
从Kafka倒带偏移火花结构化流
我正在使用spark structured streaming(2.2.1)来消费来自Kafka(0.10)的主题。 我的检查点位置设置在外部HDFS目录上。在某些情况下,我希望重新启动流式应用程序,从一开始就消费数据。然而,即使我从HDFS目录中删除所有检查点数据并重新提交jar,Spark仍然能够找到我上次使用的偏移量并从那里恢复。偏移量还在哪里?我怀疑与Kafka消费者ID有关。但是,我无法
-
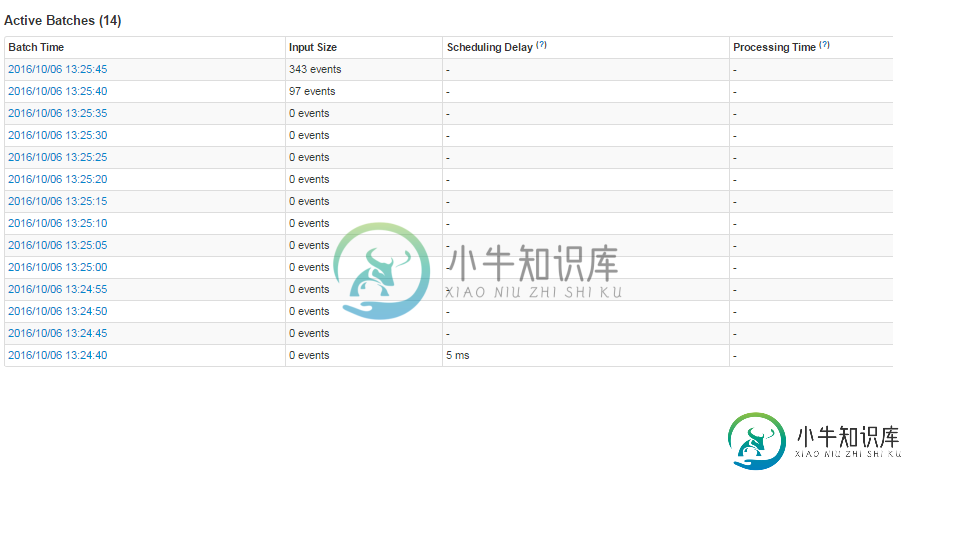 火花流与Kafka-从检查点重新启动
火花流与Kafka-从检查点重新启动我们正在构建一个使用Spark Streaming和Kafka的容错系统,并且正在测试Spark Streaming的检查点,以便在Spark作业因任何原因崩溃时可以重新启动它。下面是我们的spark过程的样子: Spark Streaming每5秒运行一次(幻灯片间隔),从Kafka读取数据 Kafka每秒大约接收80条消息 我们想要实现的是一个设置,在这个设置中,我们可以关闭spark流作业(
-
火花流微配料
如果spark streaming在10秒的批处理间隔中获得50行消息,并且在40.5行消息之后,这10秒就结束了,剩下的时间落入另一个10秒的间隔中,前40.5行的文本是一个RDD被首先处理,在我的用例中,前40行是有意义的,但是下一个。5行没有意义,第二个RDD首先也是这样。5行,我的问题是否有效?。请提供建议如何处理这个问题?。 谢谢比尔。
-
批之间的流数据共享火花
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
防止多个活动批处理火花流
我正在运行一个spark作业,流上下文每60秒运行一次。问题是一批处理时间太长(由于计算和保存RDD和Parquet到云存储),一批无法在1分钟内完成。它结束于下一批继续进入并成为活动的(状态=处理)。过了一段时间,我有10个活动批处理,而第一个已经完成。结果,它明显减慢,没有一批能够完成。是否存在严格限制一次活动批处理的数量为1。 多谢了。
-
Kafka分区是如何在火花流与Kafka共享的?
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。
-
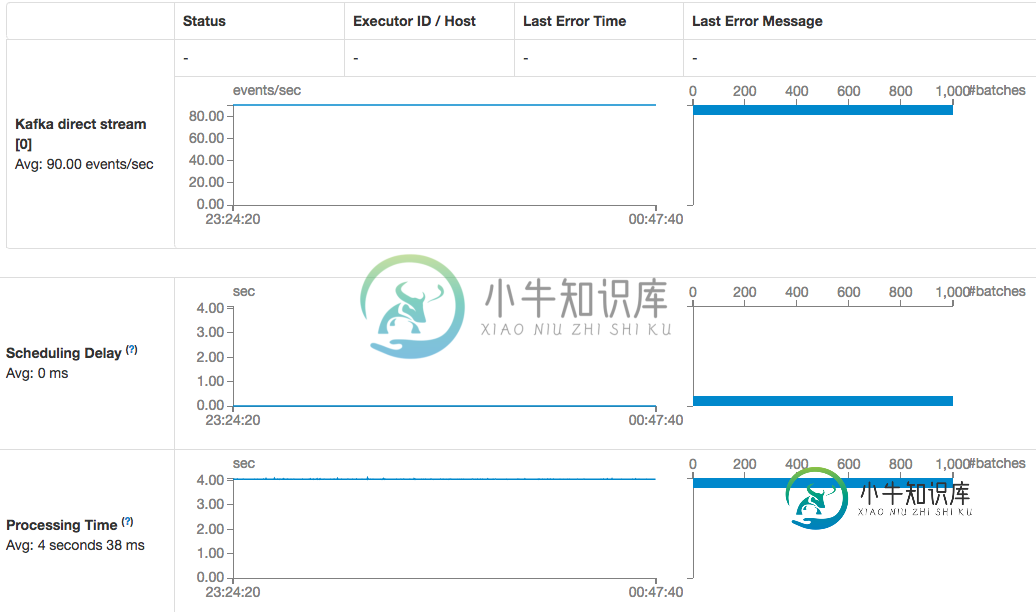 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
火花流从Kafka源返回到检查点或重绕
当streaming Spark DStreams作为来自Kafka源的消费者时,可以检查Spark上下文,因此当应用程序崩溃(或受到的影响)时,应用程序可以从上下文检查点恢复。但如果应用程序“意外地部署了错误的逻辑”,您可能想要倒回到最后一个主题+分区+偏移量,以重播某个Kafka主题的分区偏移量位置的事件,这些位置在“错误逻辑”之前正常工作。当检查点生效时,流式应用程序如何被重绕到最后的“好点
-
用于kafka主题再处理的火花流批处理间隔
当前设置:Spark流作业处理timeseries数据的Kafka主题。大约每秒就有不同传感器的新数据进来。另外,批处理间隔为1秒。通过,有状态数据被计算为一个新流。一旦这个有状态的数据穿过一个treshold,就会生成一个关于Kafka主题的事件。当该值后来降至treshhold以下时,再次触发该主题的事件。 问题:我该如何避免这种情况?最好不要切换框架。在我看来,我正在寻找一个真正的流式(一个
-
火花流调优每个批处理大小不工作的记录数?
创建了具有3个分区的主题 创建StreamingContext时将批处理持续时间设置为10秒 以纱线模式运行,有2个执行程序(3个分区共4个内核) 现在我如何测试它是否起作用。 我有一个制作人,一次发送60000条消息到这个主题。当我检查spark UI时,我得到以下信息:
-
镶木地板文件大小,消防软管与火花
我通过两种方法生成拼花地板文件:动弹消防软管和火花作业。它们都被写入S3上相同的分区结构中。两组数据都可以使用相同的Athena表定义进行查询。两者都使用gzip压缩。 然而,我注意到Spark生成的拼花地板文件大约是Firehose生成的拼花地板文件的3倍大。有什么理由会这样吗?在使用Pyarrow加载模式和元数据时,我确实注意到了一些差异: 模式差异可能是罪魁祸首吗?还有别的原因吗? 这两个特
-
火花拼花地板大小不均
由于,我检查了一个spark作业的输出拼花文件,该作业总是会发出声音。我在Cloudera 5.13.1上使用了 我注意到拼花地板排的大小是不均匀的。第一排和最后一排的人很多。剩下的真的很小。。。 拼花地板工具的缩短输出,: 这是已知的臭虫吗?如何在Spark中设置拼花地板块大小(行组大小)? 编辑: Spark应用程序的作用是:它读取一个大的AVRO文件,然后通过两个分区键(使用
-
必需:org。阿帕奇。火花sql。一行
我在尝试将spark数据帧的一列从十六进制字符串转换为双精度字符串时遇到了一个问题。我有以下代码: 我无法共享txs数据帧的内容,但以下是元数据: 但当我运行这个程序时,我得到了一个错误: 错误:类型不匹配;找到:MsgRow需要:org.apache.spark.sql.行MsgRow(row.getLong(0),row.getString(1),row.getString(2),hex2in