《烽火》专题
-
阿里云Centos配置iptables防火墙教程
本文向大家介绍阿里云Centos配置iptables防火墙教程,包括了阿里云Centos配置iptables防火墙教程的使用技巧和注意事项,需要的朋友参考一下 虽说阿里云推出了云盾服务,但是自己再加一层防火墙总归是更安全些,下面是我在阿里云vps上配置防火墙的过程,目前只配置INPUT。OUTPUT和FORWORD都是ACCEPT的规则 一、检查iptables服务状态 首先检查iptables服
-
详解CentOS7防火墙管理firewalld
本文向大家介绍详解CentOS7防火墙管理firewalld,包括了详解CentOS7防火墙管理firewalld的使用技巧和注意事项,需要的朋友参考一下 学习apache安装的时候需要打开80端口,由于centos 7版本以后默认使用firewalld后,网上关于iptables的设置方法已经不管用了,想着反正iptable也不太熟悉,索性直接搬官方文档,学习firewalld了,好像比ipta
-
无接收器火花蒸汽驱动方法
对于使用kafka的Spark流,我们使用Directstream,这是一种无接收器的方法,并将kafka分区映射到Spark RDD分区。目前,我们有一个应用程序,其中我们使用Kafka直接方法并在RDBMS中维护我们的on偏移, 我们有类似的Kinesis吗?当我阅读火花-Kinesis集成的留档时,感觉检查点有所不同。以下是我遇到的一些问题 使用kinesis流是否将kinesis碎片映射到
-
阿帕奇骆驼quartz2 cron失火
我在Spring Boot和camel-config.xml文件中使用Apache Camel。我创建了一个每秒运行一次的简单路由,并运行一个类方法: 我读了很多试图解决这个问题的书。我听到的是吼声: 发生的事情叫做“失火” 有一个参数允许配置失火说明 根据Apache Camel文档,如果使用的是cron表达式,则不能使用trigger.xxx选项(该选项允许配置失火指令)。 根据Apache
-
云火:在实时侦听器上,即使没有变化也会收取读取费用?
我想要一些关于实时监听器定价的解释。 在Firestore文档上(https://firebase.google.com/docs/firestore/pricing)声明如下: 如果侦听器断开连接的时间超过30分钟(例如,如果用户脱机),您将被收取阅读费用,就像您发出了一个全新的查询一样。 如果没有任何更改(无论是本地更改还是远程更改),该怎么办。在30分钟后重新连接时,您是否仍会因阅读而收取费
-
数据源用完时如何停止火花流
我有一个spark流媒体作业,它每5秒钟读取一次Kafka,对传入的数据进行一些转换,然后写入文件系统。 这实际上不需要是一个流式作业,实际上,我只想每天运行一次,将消息排入文件系统。但我不知道如何停止这项工作。 如果我向streamingContext传递超时。等待终止,它不会停止进程,它所做的只是导致进程在流上迭代时产生错误(请参见下面的错误) 实现我所要做的事情的最佳方式是什么 这是Pyth
-
持续火花流输出
我正在从一个消息应用程序收集数据,我目前正在使用Flume,它每天发送大约5000万条记录 我希望使用Kafka,使用Spark Streaming从Kafka消费并将其持久化到hadoop并使用impala进行查询 我尝试的每种方法都有问题。。 方法1-将RDD另存为parquet,将外部配置单元parquet表指向parquet目录 问题是finalParquet.saveAsParquetF
-
为在纱线模式下运行的每个火花作业配置log4j
我正在纱线客户端模式下运行火花作业。我在unix脚本中使用Spark提交命令运行这些作业。我想为正在运行的每个火花作业创建日志。我尝试使用以下命令获取日志: 但在这里,如果spark作业失败,它将不会在命令状态检查中被捕获,可能是unix检查|$tee命令的状态,无论spark作业成功还是失败,该命令始终是成功的 我尝试使用log4j但没有成功。我想将每个火花作业日志文件存储在本地unix服务器上
-
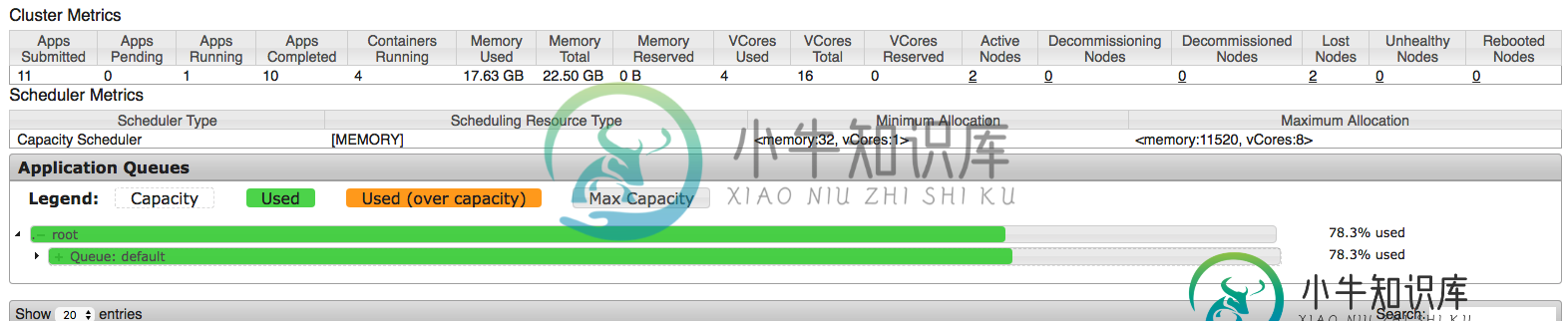 带纱线的火花流应用配置
带纱线的火花流应用配置在配置spark应用程序时,我试图从集群中挤出每一点,但似乎我并没有完全正确地理解每一件事。因此,我正在AWS EMR集群上运行该应用程序,该集群具有1个主节点和2个m3类型的核心节点。xlarge(每个节点15G ram和4个vCPU)。这意味着,默认情况下,每个节点上为纱线调度的应用程序保留11.25 GB。因此,主节点仅由资源管理器(纱线)使用,这意味着剩余的2个核心节点将用于调度应用程序(
-
火花增加纱线模式下的执行器数量
我正在4节点群集上运行Spark over纱线。节点中每台机器的配置为128GB内存,每个节点24核CPU。我使用此命令运行Spark on 但Spark最多只能启动16个执行者。我将纱线中的最大vcore分配设置为80(在我拥有的94芯中)。因此,我的印象是,这将启动19名执行人,但最多只能启动16名执行人。此外,我认为即使这些执行者也没有完全使用分配的vCore。 这些是我的问题 spark为
-
使用Livy提交Spark作业时出错:用户未初始化火花上下文
我对Spark非常陌生,我正在遵循此文档通过Livy提交Spark jobshttps://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-livy-rest-interface 这是我的命令: 文件test4sparkhaha.jar是一个超级简单的Java应用程序,它只包含一个类,只有一个打印“哈哈哈”的主方法,没有别的.
-
火力基地部署;导致“无法在模块外使用导入”[不重复]
注意:这个问题可能看起来像一个重复的问题,但它不是/尝试了所有的修复,但仍然不起作用!(如果你读了这个问题,你会知道为什么) 我有一个Firebase函数项目,我的文件夹结构是这样的, 所以,当我运行这个命令时, 它试图部署,但在控制台中显示了这一点, 显然,这个错误没有帮助,所以我进入firebase-dubug.log寻找问题的确切原因,发现了这个, 所以,我认为这个错误是由于没有把“类型”:
-
配置火花应用参数的最佳开端是什么?
我很困惑我应该使用哪种方法来配置火花应用程序参数。 让我们考虑以下集群配置:10个节点、每个节点16个内核和每个节点64GB RAM(例如https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application.html0 根据上述建议,让我们为每个执行器分配5个
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
CSRF编码点火器3验证
我一直在阅读codeigniter中的crsf保护,但是我似乎找不到一个像样的教程,说明在配置文件中启用csrf后如何继续。 我有一个由控制器函数生成的表单,它提交给另一个函数。 我使用了form helper类,以便自动生成crsf字段。 我在提交功能上有这个验证功能: 但我得到的只是不允许的错误。验证csrf的正确方法是什么?还是我做错了什么?