《烽火》专题
-
火花:如何使用映射分区和创建/关闭每个分区的连接
所以,我想对我的spark数据帧执行某些操作,将它们写入DB,并在最后创建另一个数据帧。看起来是这样的: 这给我一个错误,因为map分区期望返回的类型,但这里是。我知道这在forEach分区中是可能的,但我也想做映射。单独做会有开销(额外的火花工作)。该怎么办? 谢谢
-
火花之间的区别是什么。罐子和火花。驾驶员类外路径[重复]
我试图运行火花程序,在纱线客户端模式下使用火花提交,并获得类NotFindException。所以我的问题是我应该在哪个参数中传递我的jar(--jars或--drier-class-path)。 Spark=2.0.0 HDP 2.5 Hadoop=2.7.3
-
EMR中可用的纱线容器、火花执行器和节点之间的关系是什么?
假设我有一个包含1个主节点、3个核心节点和5个任务节点的集群。如果我在纱线集群模式下运行spark作业,驱动程序将在主节点上运行(主节点是否也可以运行executor?),每个容器可以有X个执行者。我是否有3个5=8个容器?或者仅仅3个容器,因为只有核心节点可以存储数据? 此外,如果我有两个火花作业同时运行,我是每个节点得到2个独立的容器,每个火花作业1个,还是2个火花作业的执行者每个节点共享1个
-
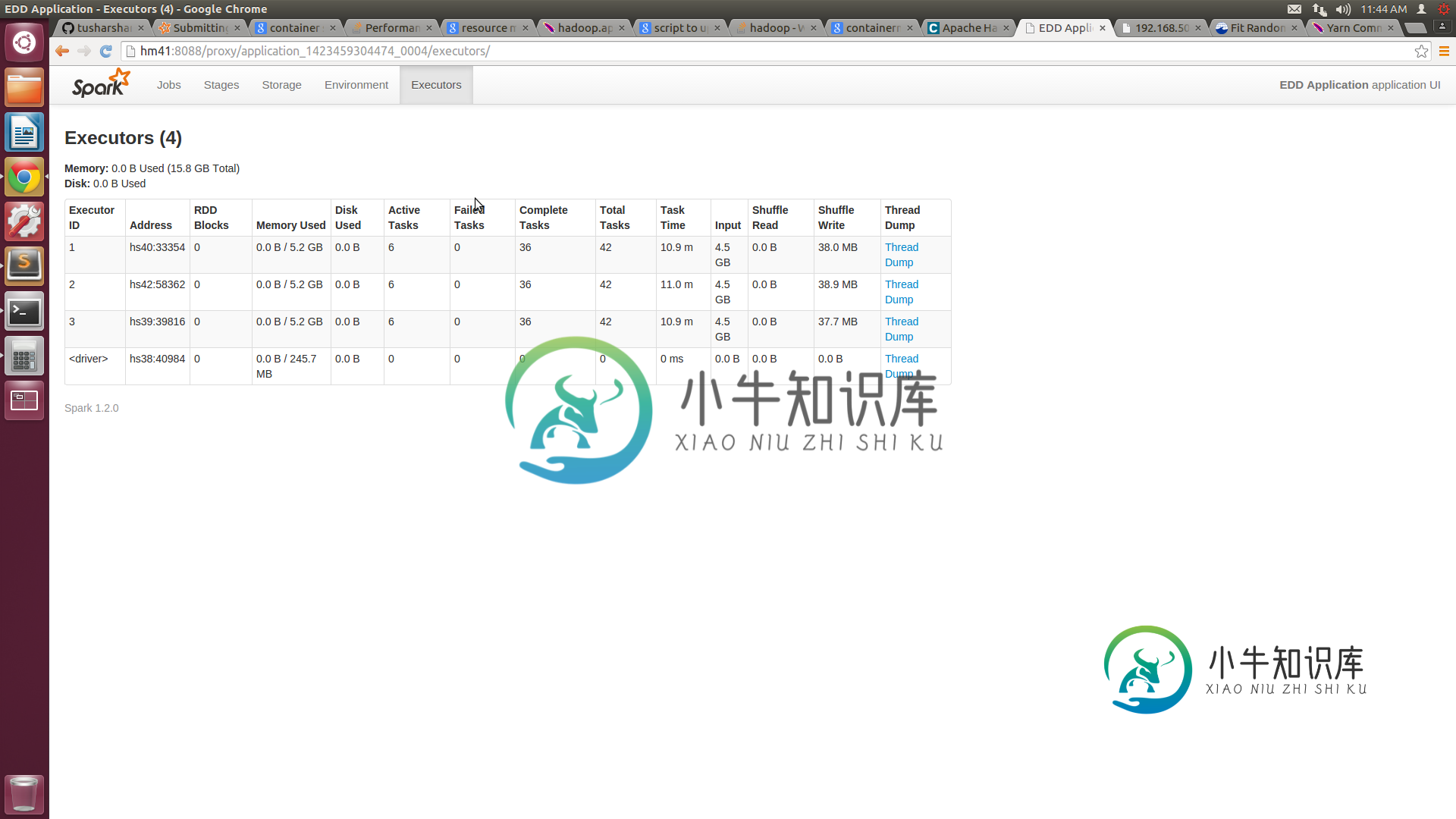 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
CSS android的字体重量:打火机不工作
我知道已经有一些修复方法,但似乎都不起作用。 我想在我的网站上使用“Helvetica Neue”,字号为300。这一切在桌面上看起来都不错,但我一切换到android,似乎就没有浅色字体了。 在这里你可以看到我在jsbin的测试。通用域名格式。请随意编辑,在我的Galaxy S3和Nexus 4上,字体的重量都相同。 正如你所看到的,我也尝试加入roboto并将其设置为light,但这也不起作用
-
Google guava singleton Eventbus多次开火
我使用vaadin spring IOC google guava eventbus。参考资料建议将guava eventbus用作singleton。但当我这样做时,我有以下问题:; > 假设我同时在3个不同的浏览器上运行应用程序,那么我的应用程序有3个不同的实例。 然后,例如,当我按下一个浏览器上的按钮并触发一个事件时,我注意到我的带有@subscribe注释的相关侦听器方法被调用了3次! 这
-
带火基的埃罗
我是新来的。Im尝试连接firebase,在屏幕登录中验证电子邮件和密码。 代码: 错误: 正在执行热重启。。。正在将文件同步到IA Emulator上的设备AOSP。。。在925ms内重新启动应用程序。E/flatter(4428):[ERROR:flatter/lib/ui/ui\u dart\u state.cc(186)]未处理的异常:NoSuchMethodError:类“Firebas
-
Drupal 8:如何修复令人恼火的错误消息“无法安装广告,已存在于活动配置中”?
我是Drupal编程新手,但我遇到了一些问题。每次我卸载一个模块并希望再次安装它时。 我得到这个错误消息: 无法安装播发、核心。实体\窗体\显示。节点。广告默认,核心。实体\视图\显示。节点。广告默认,核心。实体\视图\显示。节点。广告挑逗者,场上。领域节点。广告身体,节点。类型活动配置中已存在播发。 我已经做了什么? 与drush缓存清除/缓存重建没有结果 在Drupal自缓存清除没有结果 甚至
-
HDInsight集群中的UTF-8文本有火花结果编码错误'ascii'编解码器无法在位置编码字符:序数不在范围内(128)
在Linux上使用spark在HDInsight集群中使用希伯来字符UTF-8 TSV文件时,我发现编码错误,有什么建议吗? 这是我的pyspark笔记本代码: 错误: 'ascii'编解码器不能编码位置6-11的字符:序数不在范围内(128)Traceback(最近的调用最后): UnicodeEncodeError:'ascii'编解码器不能编码位置6-11的字符:序数不在范围内(128) 希
-
火猴TEdit大写
我对Android中Firemonkey TEdit大写字母有问题。 代码: 在Win32中它可以工作,但在Android中它不工作。
-
装载pdo_火鸟。动态链接库
我想运行PHP扩展,能够连接到火鸟数据库。在php.ini有启用的行扩展名=pdo_firebird.dll,文件存在于其他扩展名 /ext目录中。每次我重启Apache(和PHP),我都看不到phpinfo()中加载的扩展。为什么啊?我在Windows 8上运行Apache 2.2和PHP 5.4。
-
无法获取提供程序com。谷歌。火基。供应商。FirebaseInitProvider
我正在测试新的崩溃工具:https://firebase.google.com/docs/crash/ 完成步骤后,应用程序启动,它崩溃了,说:
-
代码点火器,Restful API
我用的是Phil Sturgeon的 KEYS如何工作?有一个名为KEYS的表定义如下: 在名为KEYS的类中有如下方法: 由于这个软件包并没有很好的文档记录,而且我是API新手,所以上面的工作原理是什么?例如,我是否生成一个密钥并将其永久插入数据库。为什么会有删除方法? 从我的阅读资料来看,这听起来像是我为应用程序生成了一个初始的X-API-KEY,然后当客户端使用资源时,我会使用KEYS类将X
-
`火花。调试。MaxToString字段`
Spark v2.4 <代码>火花。sql。调试。此处定义了MaxToString字段https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala 不知何故,它变成了在https://github.com/apache/spark
-
Intellij IDEA:火花代码运行导致java.lang.VerifyError
在IntelliJ IDEA中,我试图用spark代码执行一个Java文件,这将产生Java。验证错误。 StackTrace如下所示: 错误执行器:java阶段1.0(TID 2)中任务0.0中出现异常。lang.VerifyError:(class:org/apache/spark/sql/catalyst/expressions/GeneratedClass$SpecificOrdering