《巨杉数据库》专题
-
如何处理mysqldump创建的巨大行长度
问题内容: 我在cron作业中使用mysqldump备份了超过200万行的数据库。 它会创建一个文本文件,该文件可用于从命令行还原数据日志。 我认为在还原之前编辑转储将是有用的,这是一种 快速 更改值和表或列名的方法-至少要等到我了解更多并对使用ALTER和UPDATE做到这一点充满信心为止。 编辑大型文本文件不会打扰我,但是我惊讶地发现,在数据库的 250兆字节 转储中, 只有大约300行 。每
-
使用bash或python排序巨大的JSON文件
问题内容: 要求 :我有一个.gz格式的Json文件。因此,压缩后的大小约为500 MB。当我提取它时,json文件几乎变成了大约10 GB。提取的JSON文件逐行包含单个JSON对象。我想要的是使用任何bash脚本或python程序基于字段对文件进行排序。 由于文件太大,因此不建议将其加载到内存中。因此,我使用了gzcat和cat bash命令来流式传输JSON数据,然后将它们通过管道传输到jq
-
为什么生锈的docker图像如此巨大
我正在将一个rust应用程序打包到docker映像以部署到我的服务器。我发现rust docker的图像大小超过1GB(比使用java和python的任何其他应用程序都大)。为什么rust docker的形象如此巨大?我检查了该层,发现cargo build命令需要400MB以上的内存。 是否可以缩小rust docker的图像?
-
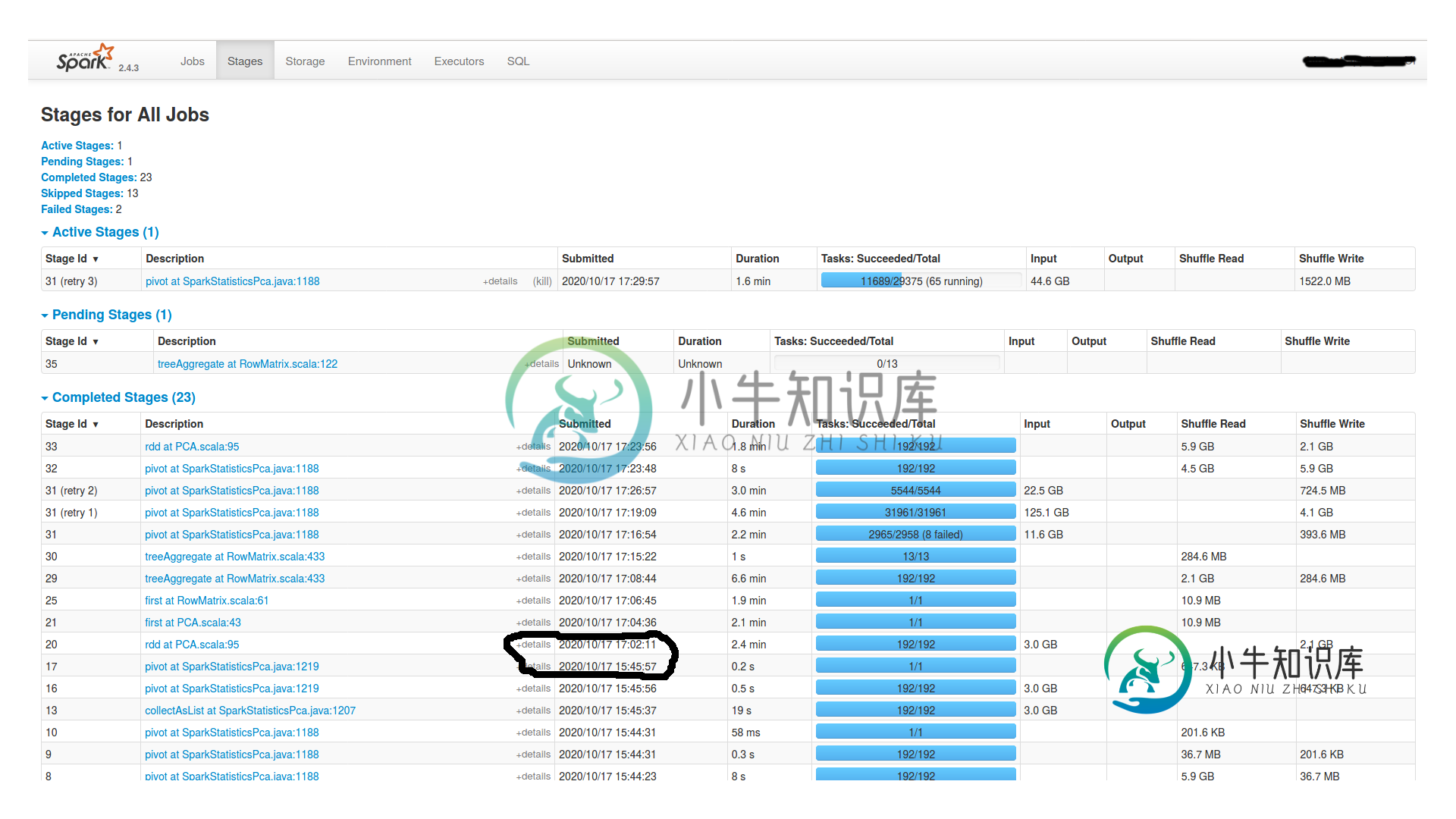 火花工作之间的巨大时间间隔
火花工作之间的巨大时间间隔我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
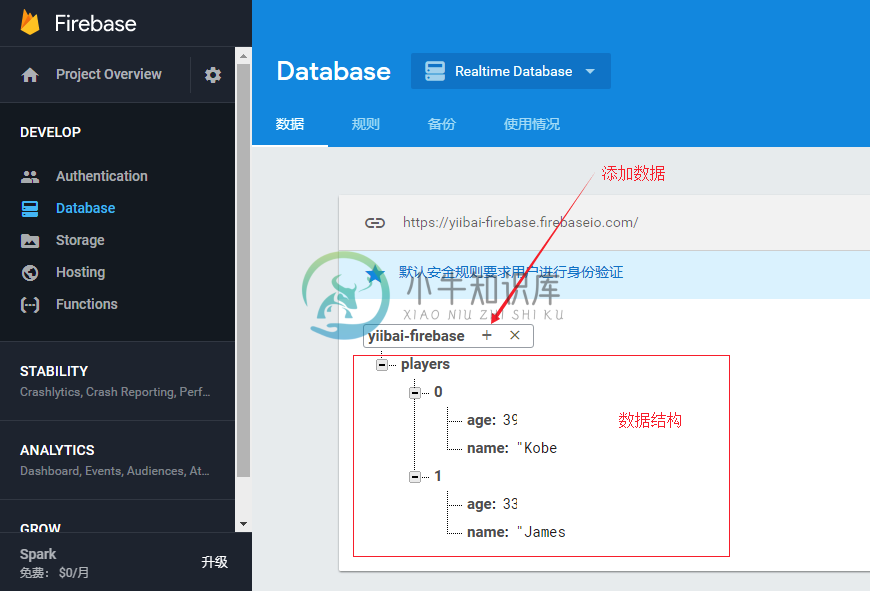 Firebase数据
Firebase数据Firebase数据是JSON对象格式的数据。 如果从Firebase信息中心打开应用,则可以通过单击+号手动添加数据。 这里将演示如何创建一个简单的数据结构。请参考下图。 在上一章中,我们将Firebase连接到了应用程序。 现在,可以将Firebase记录输出到控制台。 Firebase记录输出如下 - 可以创建一个引用参考的集合。 在控制台中看到以下结果。
-
数据流
严格的单向数据流是 Redux 架构的设计核心。 这意味着应用中所有的数据都遵循相同的生命周期,这样可以让应用变得更加可预测且容易理解。同时也鼓励做数据范式化,这样可以避免使用多个且独立的无法相互引用的重复数据。 如果这些理由还不足以令你信服,读一下 动机 和 Flux 案例,这里面有更加详细的单向数据流优势分析。虽然 Redux 不是严格意义上的 Flux,但它们有共同的设计思想。 Redux
-
数据 API
获取或设置离线仓库中的数据的 API。 getItem localforage.getItem('somekey').then(function(value) { // 当离线仓库中的值被载入时,此处代码运行 console.log(value); }).catch(function(err) { // 当出错时,此处代码运行 console.log(er
-
数据 Mock
安装 Mpx 提供了对请求响应数据进行拦截的 mock 插件,可通过如下命令进行安装: npm i @mpxjs/mock 使用说明 新建 mock 文件目录及文件(例如:src/mock/index.js ): // src/mock/index.js import mock from "@mpxjs/mock"; mock([ { url: "http://api.example.
-
数据类
数据类是一种非常强大的类,它可以让你避免创建Java中的用于保存状态但又操作非常简单的POJO的模版代码。它们通常只提供了用于访问它们属性的简单的getter和setter。定义一个新的数据类非常简单: data class Forecast(val date: Date, val temperature: Float, val details: String)
-
数据流
有时,您希望发送非常巨量的数据到客户端,远远超过您可以保存在内存中的量。 在您实时地产生这些数据时,如何才能直接把他发送给客户端,而不需要在文件 系统中中转呢? 答案是生成器和 Direct Response。 基本使用 下面是一个简单的视图函数,这一视图函数实时生成大量的 CSV 数据, 这一技巧使用了一个内部函数,这一函数使用生成器来生成数据,并且 稍后激发这个生成器函数时,把返回值传递给一个
-
5.8. 数据
5.8. 数据 5.8.1. new()分配 Go 有两个分配原语,new() 和 make() 。它们做法不同,也用作不同类型上。有点乱但规则简单。我们先谈谈 new() 。它是个内部函数,本质上和其它语言的同类一样:new(T)分配一块清零的存储空间给类型 T 的新项并返回其地址,一个类型 *T 的值。 用 Go 的术语,它返回一个类型 T 的新分配的零值。 因为 new() 返回的内存清零,
-
Mock 数据
Mock 数据是前端开发过程中必不可少的一环,是分离前后端开发的关键链路。通过预先跟服务器端约定好的接口,模拟请求数据甚至逻辑,能够让前端开发独立自主,不会被服务端的开发所阻塞。 使用 umi 的 mock 功能 umi 里约定 mock 文件夹下的文件或者 page(s) 文件夹下的 _mock 文件即 mock 文件,文件导出接口定义,支持基于 require 动态分析的实时刷新,支持 ES6
-
数据源
Spark SQL支持通过SchemaRDD接口操作各种数据源。一个SchemaRDD能够作为一个一般的RDD被操作,也可以被注册为一个临时的表。注册一个SchemaRDD为一个表就 可以允许你在其数据上运行SQL查询。这节描述了加载数据为SchemaRDD的多种方法。 RDDs parquet文件 JSON数据集 Hive表
-
Benchmark 数据
测试代码 测试环境&条件 3 台 16C 20G 内存的 docker 容器作为 server node (3 副本) 2 ~ 8 台 8C docker 容器 作为 client 24 个 raft 复制组,平均每台 server node 上各自有 8 个 leader 负责读写请求,不开启 follower 读 压测目标为 JRaft 中的 RheaKV 模块,只压测 put、get 两个接
-
SEO数据
SEO数据页涵盖 [搜索引擎的收录情况] 以及 [网页的Alexa排名变化] 1.搜索引擎收录 www.owecn.com 页数及PR数据 显示搜索引擎对域名的收录数据,帮助您更好的做好搜索引擎收录,点击“+”号能查到每一天的收录情况 2.www.owecn.com 的 Alexa 排名变化 1)Alexa排名是指网站的世界排名,主要分为综合排名和分类排名 2)Alexa提供了包括综合排名、到