《政采云》专题
-
AVRO生成了pojo的Kafka Spring云模式注册表
我正在考虑使用模式来验证Kafka主题的数据。我正在结合apache kafka探索spring云模式注册表。 如果我在阅读文档后理解正确。Spring云模式注册表仅支持avro模式!在avro pojos中,需要使用类路径上的. avsc文件生成pojos,并且有一个maven插件可以完成所需的工作。 问题: 如果我的POJO上有这样的自定义验证呢?我不想在我的Kafka消费者中使用avro模式
-
Google云数据流使用什么java运行时?java8或java11
谷歌云数据流是基于ApacheBeam的。beam并不正式支持java11。但是当我在GCP上运行一个数据流作业并检查该作业作为工作线程使用的vm实例时。我发现容器映像是“gcr.io/cloud dataflow/v1beta3/beam-java11-batch:beam-2.23.0”。那么,在运行数据流时,数据流是否使用java11作为java运行时?为什么不使用java8?是否存在bug
-
如何运行Python谷歌云数据流作业与自定义Docker图像?
我想运行一个Python谷歌云数据流作业与自定义Docker图像。 根据文件,这应该是可能的:https://beam.apache.org/documentation/runtime/environments/#testing-自定义图像 为了尝试此功能,我使用此公共repo中的文档中的命令行选项设置了基本wordcount示例管道https://github.com/swartchris8/b
-
使用docker解决google云数据流依赖
我对使用谷歌云数据流并行处理视频感兴趣。我的工作同时使用OpenCV和tensorflow。是否可以只在docker实例中运行worker,而不按照以下说明从源安装所有依赖项: https://cloud.google.com/dataflow/pipelines/dependencies-python 我本以为docker容器会有一个标志,它已经位于google容器引擎中。
-
谷歌云数据流工作者的自定义虚拟机映像
浏览了Google云数据流文档后,我的印象是worker VM运行一个特定的预定义Python 2.7环境,没有任何改变的选项。是否可以为工作人员提供自定义VM映像(使用库、特定应用程序需要的外部命令构建)。可以在Gcloud数据流上运行Python 3吗?
-
谷歌云数据流实例的图像
当我运行Dataflow作业时,它会将我的小程序包(setup.py或requirements.txt)上传到Dataflow实例上运行。 但是数据流实例上实际运行的是什么?我最近收到了一个stacktrace: 但从理论上讲,如果我在做,这意味着我可能没有运行这个Python补丁?你能指出这些作业正在运行的docker图像吗,这样我就可以知道我使用的是哪一版本的Python,并确保我没有在这里找
-
如何从云端恢复中检索自定义对象?
我正在尝试将我的实时数据库调整为一个聊天应用程序的云firestore。存储的对象是我创建的Message类。我希望邮件成为文档。 我的RecyclerView适配器将使用实时数据库这样检索它们: 下面是我如何开始用Firestore重新创建它的。如何在快照侦听器的OneEvent方法中将快照转换回消息?
-
如何将JSON导入云Firestore
我目前正在使用Firebase实时数据库。我已经将JSON导入实时数据库,但由于查询的限制,我需要打开Firebase Firestore。 我想将JSON导入Firebase的云Firestore。
-
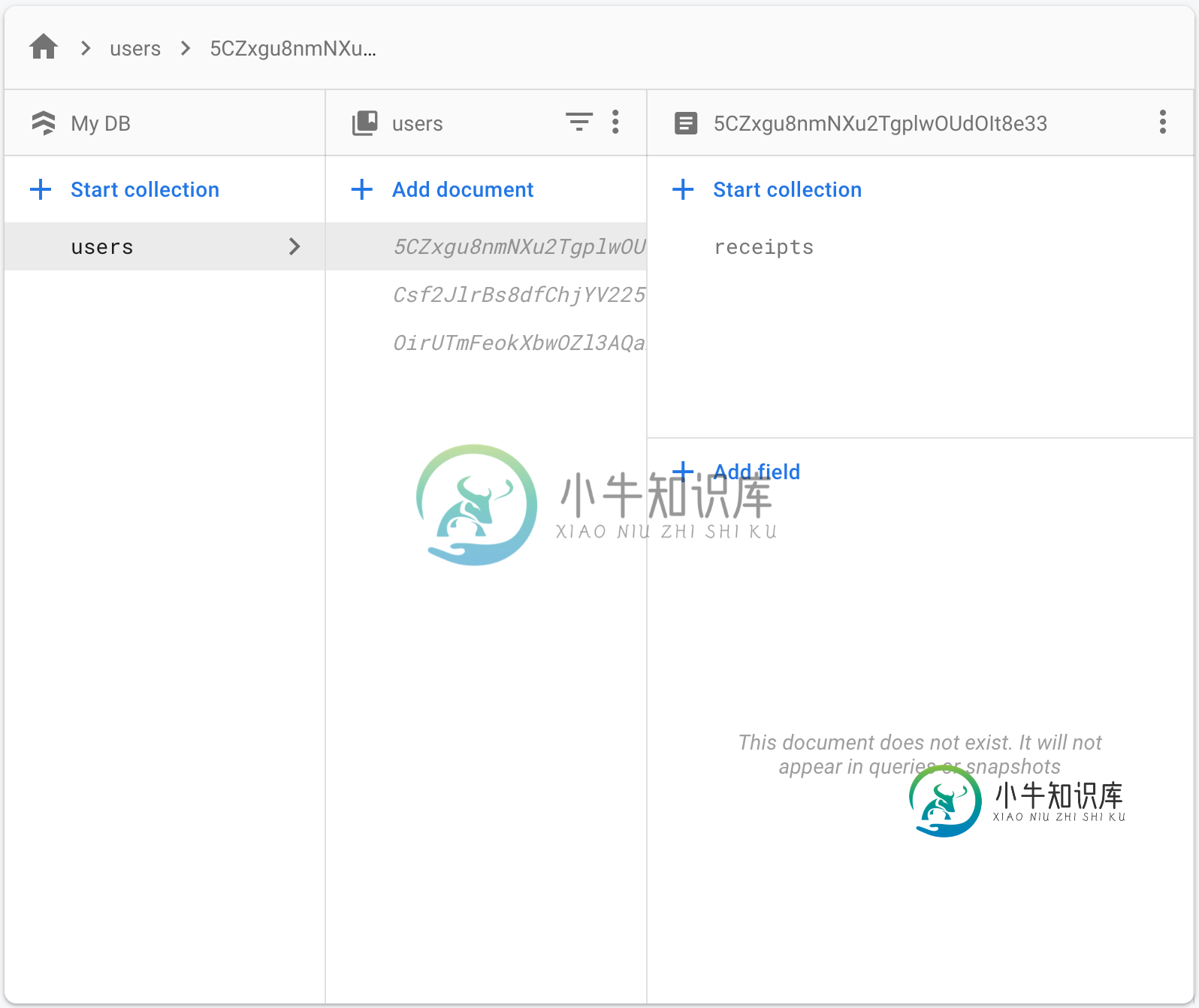 Firestore云函数空集合
Firestore云函数空集合我有一个困扰我好几天的问题。我正在尝试创建一个从Firestore数据库读取的Firebase云函数。 我的Firestore DB如下所示: 问题是我无法像这样列出: 如果我尝试这样做,我会得到空响应,就像我的集合中没有用户一样。 但我尝试直接访问用户它可以工作: 我的完整代码: 有人知道我做错了什么吗?非常感谢。
-
在云Firestore中使用Firebase实时数据库节点密钥作为文档ID
我正在将我的实时数据库迁移到Cloud FiRecovery。理想情况下,我需要保留使用生成的相同实时数据库节点密钥,并将其用作FiRecovery中的文档ID,但这样做安全吗? 我已经阅读了https://firebase.google.com/docs/firestore/best-practices的信息,我仍然不确定这是否安全。我知道Cloud FiRecovery中自动生成的文档ID与实
-
云火:在实时侦听器上,即使没有变化也会收取读取费用?
我想要一些关于实时监听器定价的解释。 在Firestore文档上(https://firebase.google.com/docs/firestore/pricing)声明如下: 如果侦听器断开连接的时间超过30分钟(例如,如果用户脱机),您将被收取阅读费用,就像您发出了一个全新的查询一样。 如果没有任何更改(无论是本地更改还是远程更改),该怎么办。在30分钟后重新连接时,您是否仍会因阅读而收取费
-
云Firestore正在阻止大容量更新同步
(注意:如果我在这里使用关系数据库术语,很抱歉。) 假设我有十个客户端连接到一个数据库。该数据库的持续吞吐量约为每秒1k次更新。显然,对于最终用户来说,每秒向web浏览器发送1k个更新(比如每秒1MB的数据更改)并不是一个好的体验。Firebase是否可以控制客户端在开始限制数据之前可以“接受”的数据量?我理解它可能会批量请求,但我的观点是,谷歌接受数据/更新的速度比浏览器更快(可能是通过弱互联网
-
如何在云形成yaml中配置路由规则?
我正在尝试使用无服务器yaml(使用cloudformation)为静态s3 bucket网站配置此网站路由规则。 我如何翻译成我下面的yaml?
-
Spring云网关上的CORS配置出错
请帮忙。我正在使用Spring Cloud Gateway,我不断收到以下Cors错误: CORS策略阻止从源http://localhost:4200在http://localhost:8084/users/files处访问XMLHttpRequest:对预飞行请求的响应无法通过权限改造检查:请求的资源上不存在“访问控制-允许-源”标头。 这是我的application.yml档案
-
春云库伯内特斯,网关路线映射
我正在学习Spring Bootkubernetes并尝试为我的服务设置Spring Cloud网关。我相信使用Spring Cloud网关,我们不再需要使用功能区来进行负载平衡。所以如果我不使用功能区,那么路由的配置也会改变。我查看了网站以寻求建议,我发现如下:- 在这种情况下,uri具有服务可用的端口的硬编码值。这是推荐的方法吗? 然后还有另一种配置的味道,看起来像这样,不确定url表达式想做