《政采云》专题
-
什么是采矿?
本文向大家介绍什么是采矿?相关面试题,主要包含被问及什么是采矿?时的应答技巧和注意事项,需要的朋友参考一下 回答:**在区块链技术的背景下,挖掘是通过向网络提供工作证明来向大型分布式公共分类账添加交易的过程,即生成的区块是有效的。它还将新硬币添加到生成的块中。术语“采矿”以与比特币的关联而闻名。
-
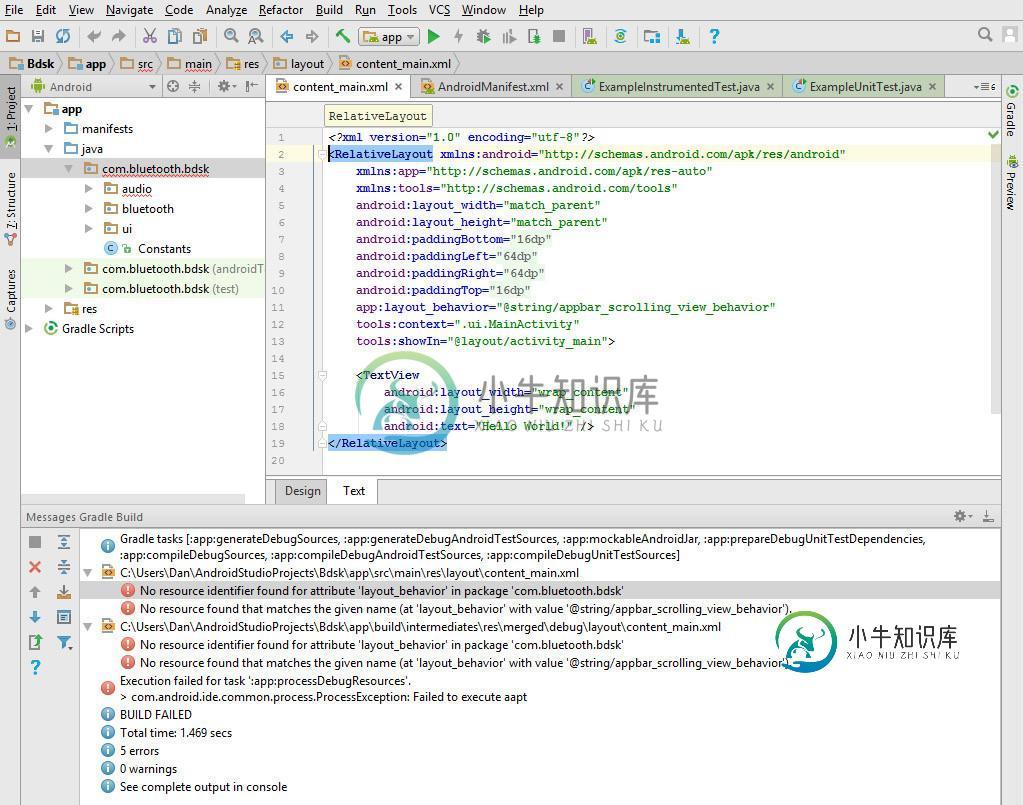 Bdsk采样错误
Bdsk采样错误我在尝试制作Bdsk样例文件时出现了一些错误。作为Android Studio的新手,如果能让我知道如何修复这些错误,我将非常感激。 我根据以下说明使用示例源代码:要使用解决方案代码,使用名称“bdsk”和公司域名“bluetooth.com”创建一个新的Android Studio项目。创建项目后,将BDSK\app\src\main文件夹中的内容替换为Bluetooth Developer S
-
class_weight的采样值
我正在尝试在使用的Scikit学习SVM分类器中使用类权重。 我有四节课。现在对于class_weight,我希望四个类中的每一个都有介于0和1之间的随机值。可以用 但这仅适用于一个类,并且值是离散的,而不仅仅是在 0 和 1 之间采样。 我该如何解决这个问题? 最后但同样重要的是,如果我使用0到1之间或1到10之间的值,这有关系吗(即权重是否被重新调整)? 所有4类的权重总和是否应该总是相同的值
-
FAQ - 采集相关
Open-Falcon数据收集,分为[绘图数据]收集和[报警数据]收集。下面介绍,如何验证两个链路的数据收集是否正常。 如何验证[绘图数据]收集是否正常 数据链路是:agent->transfer->graph->query->dashboard。graph有一个http接口可以验证agent->transfer->graph这条链路,比如graph的http端口是6071,可以这么访问验证: #
-
MCMC采样和M
在解决从平稳分布$$pi$$, 找到对应的马尔科夫链状态转移矩阵P之前,我们还需要先看看马尔科夫链的细致平稳条件。定义如下: 如果非周期马尔科夫链的状态转移矩阵P和概率分布$$pi(x)$$对于所有的i,j满足:$$pi(i)P(i,j) = pi(j)P(j,i)$$ 则称概率分布$$pi(x)$$是状态转移矩阵P的平稳分布。 证明很简单,由细致平稳条件有:$$sumlimits_{i=1}{i
-
采用 JSON 编码
在早期的版本中,有一种降低 logstash 过滤器的 CPU 负载消耗的做法盛行于社区(在当时的 cookbook 上有专门的一节介绍):直接输入预定义好的 JSON 数据,这样就可以省略掉 filter/grok 配置! 这个建议依然有效,不过在当前版本中需要稍微做一点配置变动 —— 因为现在有专门的 codec 设置。 配置示例 社区常见的示例都是用的 Apache 的 customlog。
-
7.标绘/采集
对于外业来说,采集标绘是十分重要的功能。不同的业务类型都需要大量采集点线面信息。外业精灵中提供了简单的标绘采集功能,可以方便用户快速完成外业要素的采集、信息录入。 打点 点击标点按钮,会在屏幕中心(十字丝)位置添加一个点,同时弹出点标记点编辑页面。 标记点编辑页面包括四项内容:标记点预览、基本信息、属性、样式。 基本信息包括该点的名称、存储文
-
IDFA采集设置
MTJ iOS SDK从V4.6.4版本起,支持采集IDFA。 使用IDFA,理论上需要集成任意一家的广告服务,如果您的App并未使用任何广告,可以采用以下方法通过Appstore审核: 在itunesConnect提交新版本审核时,在Advertising Identifier选项中选择YES,同时勾选子选项,如下图。 a) Serve advertisements within the app
-
采纳和演进
采纳和演进 注意:本书中的 Service Mesh 章节已不再维护,请转到 istio-handbook 中浏览。 没有人会一下子采纳Service Mesh架构的所有组件,或者一次性将所有的应用都改造成Service Mesh的,都是渐渐式采纳,从非核心系统开始改造。采纳Service Mesh就两种路径: 全盘采纳:通常对于新应用来说才会这样做,也叫做Greenfiled项目 渐进式采纳:旧
-
采集单元素
学习采集单个网页元素的属性值或内容。 获取单个元素的单个属性 获取多个元素的单个属性 实战 - 采集IT之家文章页 QueryList有个find()方法,用于采集单个元素,它通过jQuery选择器选择DOM元素,用法同jQuery的find()方法。 获取单个元素的单个属性 如果你有使用过jQuery的经验,就会发现下面的写法与jQuery的写法是一致的。 设置待采集的HTML片段 use QL
-
已采集数据
已采集数据 所有入库成功或失败的数据都被记录在此,用于网址排重,防止重复采集
-
采集器设置
采集器设置 点击任务底部进度条的“采集器设置”进入规则编辑界面 输入采集规则名称和目标网站编码(可自动检测) 页面渲染可自动加载出ajax内容,适用于js脚本较多的页面 自动补全网址可以将网页中的相对地址(不包含域名的网址)转为绝对网址(包含域名) 网址不排重,默认会将采集过的内容页排重处理,不排重适用于更新频繁的动态页面 修改请求头信息以适应需要登录的、手机浏览的等界面 起始页网址 添加需要采集
-
Ingest采集实例
SRS启动后,自动启动Ingest开始采集file/stream/device,并将流推送到SRS。详细规则参考:Ingest,本文列出了具体的部署的实例。 假设服务器的IP是:192.168.1.170 第一步,获取SRS。详细参考GIT获取代码 git clone https://github.com/ossrs/srs cd srs/trunk 或者使用git更新已有代码: git p
-
Python中的邮政编码列表
问题内容: 我正在尝试学习如何“压缩”列表。为此,我有一个程序,在某个特定位置执行以下操作: 这给了我三个列表,,,和,每一个,比方说,大小为20。 现在,我这样做: 但是,当我这样做时: 我得到20,这不是我期望的。我预计三个。我认为我做的事情根本上是错误的。 问题答案: 将三个包含20个元素的列表放在一起时,结果将包含20个元素。每个元素都是一个三元组。 你自己看: 要找出每个元组包含多少个元
-
詹金斯内容安全政策
问题内容: 我对Jenkins内容安全政策感到困惑。 我有一个通过Jenkins Clover插件显示的html页面。该html页面使用嵌入式样式,例如: div元素可视化进度条。使用默认的Jenkins CSP配置会导致以下结果: Progressbar_FAIL 我想要的结果如下所示: Progressbar_WORKS 我试图放宽CSP规则,添加具有不同级别(自我,不安全内联等)的参数(脚本