《渤海》专题
-
 海能达Android一、二面面经
海能达Android一、二面面经海能达总共有三轮面试,一轮技术面+一轮HR面+一轮主管面,这里我跟大家分享一下我的技术面和HR面,因为主管面没聊什么,个人觉得海能达的秋招还是比较友好的,面试官不错。 一面|45min 对Java面向对象的理解(重点讲三大特性,哪些可以继承下来) 你知道Java哪些数据类型呢? 接口和抽象类的区别 进程间通信的方式 线程池参数 HashMap的扩容机制,它线程安全吗? ArrayList和Link
-
 海康威视面试
海康威视面试开始面试的才知道投递的是客户端岗位 最开始说的4点面试,等了10分钟,又打电话说有会要开,所以调到了5点,到了5点又迟到了10分钟才开始面试 2022.11.10 面试海康威视 30分钟 1.简单介绍一下项目(这里选择的是网络库的项目) 2.线程池的实现(这里回答的不是很好,有点语无伦次....) 3.智能 指针(刚准备开始八股文吟唱就被打断施法了,让我不要说太深) 4.mysql的索引(这个也就
-
 海雀科技Android开发工程师技术面面经
海雀科技Android开发工程师技术面面经上周参加的学校校招,应该就一轮技术面,要等这周结束才出结果,希望能有个好结果,去不去就另说了,哈哈,步入正题。 技术面 自我介绍 问我实习经历和大学自己写的博客(团队分工,有什么收获,遇到了什么问题,有什么实际的程序产出,怎么进行维护和优化的等等) 先讲述下Java面向对象的思想(三大特性) 继承类和接口的区别 volatile 关键字的作用,和synchronized的区别 HashMap的储存
-
Movie 网站 (类似于IMDB) - 添加海报(Primary)和简介(Gallery)图片
需要分别给人员(Person)和影片(Movie)记录添加一张海报和多张简介图片。让我们从迁移类开始: using FluentMigrator; namespace MovieTutorial.Migrations.DefaultDB { [Migration(20160603205900)] public class DefaultDB_20160603_205900_Pers
-
4.7 海量数据处理
所谓海量数据处理,无非就是基于海量数据上的存储、处理、操作。何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。 那解决办法呢? 针对时间,我们可以采用巧妙的算法搭配合适的数据结构,如Bloom filter/Hash/bit-map/堆/trie树。 针对空间,无非就一个办法:大而化小,分而治之(hash映射)。 二、算法/数据结构基础 1.
-
海本热图图中的离散图例
问题内容: 我用这里的数据,用seaborn和 熊猫。 代码: 从csv文件中可以看到,它包含3个离散值:0、-1和1。我 想要一个离散的图例而不是色条。将0标记为A、-1标记为B和1 作为C.我怎么做? 问题答案: 好吧,要做到这一点肯定不止一种方法。在这种情况下, 由于只需要三种颜色,我会选择自己的颜色创建一个 而不是使用“cubehelix\u palete”生成它们。 如果有足够的颜色来保
-
 JS实现星星海特效
JS实现星星海特效本文向大家介绍JS实现星星海特效,包括了JS实现星星海特效的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了JS实现星星海特效的具体代码,供大家参考,具体内容如下 知识点 1.CSS使用@keyframes自定义动画,使用animation调用自定义动画 2.opacity 透明度。从 0.0 (完全透明)到 1.0(完全不透明) 3.CSS中transform 4.animation
-
扭曲的海螺文件传输
问题内容: 我正在尝试使用扭曲的海螺在python中实现一个非常简单的文件传输客户端。客户端应该简单地以编程方式将一些文件传输到远程ssh / sftp服务器。该功能提供了用户名,密码,文件列表,目标服务器:目录,只需要以跨平台的方式进行身份验证和复制。 我已经阅读了有关Twisted的一些入门资料,并设法制作了自己的SSH客户端,该客户端仅在远程服务器上执行。我很难将其扩展到移动文件。我看了cf
-
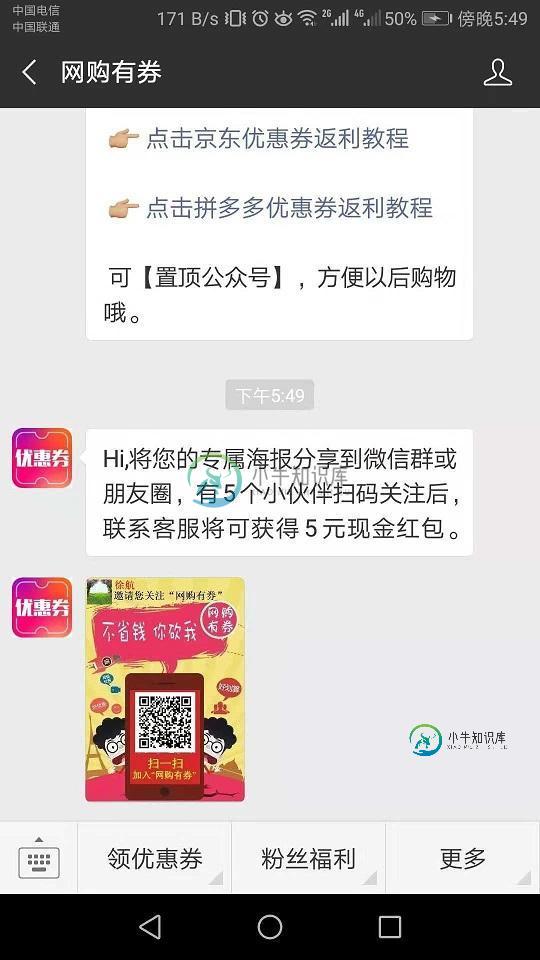 C#生成带二维码的专属微信公众号推广海报实例代码
C#生成带二维码的专属微信公众号推广海报实例代码本文向大家介绍C#生成带二维码的专属微信公众号推广海报实例代码,包括了C#生成带二维码的专属微信公众号推广海报实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 很多微信公众号中需要生成推广海报的功能,粉丝获得专属海报后可以分享到朋友圈或发给朋友,为公众号代言邀请好友即可获取奖励的。海报自带渠道二维码,粉丝长按二维码即可关注微信公众号,从而达到吸粉的目的。 效果如下: 代码实现: 1.获取临时
-
rsync备份海量文件时占用大量内存的解决方法
本文向大家介绍rsync备份海量文件时占用大量内存的解决方法,包括了rsync备份海量文件时占用大量内存的解决方法的使用技巧和注意事项,需要的朋友参考一下 linux发行版中大多都自带rsync,不过版本比较低,一般都是2.6.X 在2.X的版本中,rsync备份时都是先列表再备份(添加或者删除),在处理大量文件时,会耗费比较多的内存。 备份的时候,rsync扫描到的每个文件(目录也一样),在它的
-
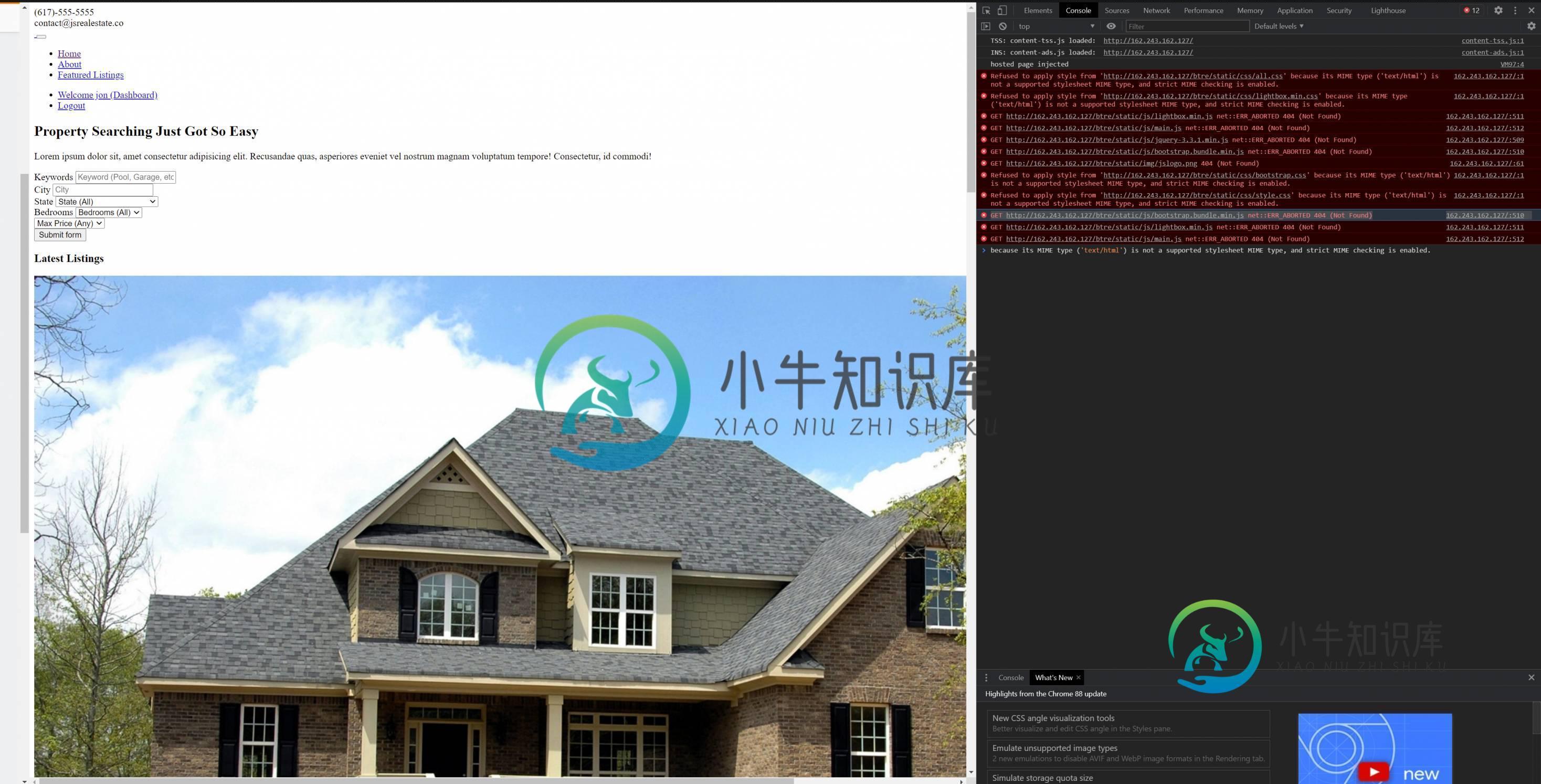 Nginx数字海洋部署中加载静态文件时出现问题
Nginx数字海洋部署中加载静态文件时出现问题Django初学者在这里... 在最终部署到数字海洋液滴时加载静态文件时遇到问题 我用的是Nginx和Gunicorn。 我遵循了Traversy Media的教程,但我无法通过我的Digital Ocean ipv4在浏览器中显示静态文件。检查后,它会抛出这些多个错误。 这是我的nginx设置 这是我的枪角设置 我曾多次尝试在终端中运行collectstatic,但它不起任何作用。。表示它有“0
-
 找不到:/media/404 77 Django制作-ASGI数字海洋
找不到:/media/404 77 Django制作-ASGI数字海洋我尝试了所有方法,但我的文件夹配置文件图片仍然没有出现。他们在网页上看起来像这样。 我在生产我的Django 2.1应用程序,使用数字海洋运行ASGI服务器(因为我使用)。 我的文件夹位于我的根文件夹中(与
-
缺少Django Grappelli样式[数字海洋设置]
我部署了一个安装了Django admin的数字海洋水滴。当我安装Django Grappelli并尝试加载管理员时,Django Grappelli中的css和js文件丢失,导致页面显示纯HTML。当我检查元素时,所有必需的图形文件都丢失了,代码为404。 有什么想法吗?? 以下是我的ettings.py供参考: 这是我的NGINX配置: NGINX错误日志:
-
如何替换大海捞针的第N个外观?(蟒蛇)
问题内容: 我正在尝试替换大海捞针中的第N个外观。我只想通过re.sub()来做到这一点,但是似乎无法提出一个合适的正则表达式来解决这个问题。我正在尝试适应:http : //docstore.mik.ua/orelly/perl/cookbook/ch06_06.htm,但是我认为跨多行失败。 我当前的方法是一种迭代方法,该方法从每次突变后的开始就查找每次出现的位置。这是非常低效的,我想获得一些
-
在文件中写入海量数据的最快方法
问题内容: 我试图创建一个随机的实数,整数,字母数字,字母字符串,然后写入文件,直到文件大小达到 10MB 为止。 代码如下。 大约需要 225.953125秒 才能完成。如何提高此程序的速度?请提供一些代码见解? 问题答案: 观察到的“缓慢”的两个主要原因: 您的while循环很慢,大约有一百万次迭代。 您没有正确使用I / O缓冲。不要进行太多系统调用。目前,您正在拨打约一百万次。 首先在Py