《找工作啊找工作》专题
-
functools — 操作函数的工具
装饰器 # functools_partial.py import functools def myfunc(a, b=2): "Docstring for myfunc()." print(' called myfunc with:', (a, b)) def show_details(name, f, is_partial=False): "Show deta
-
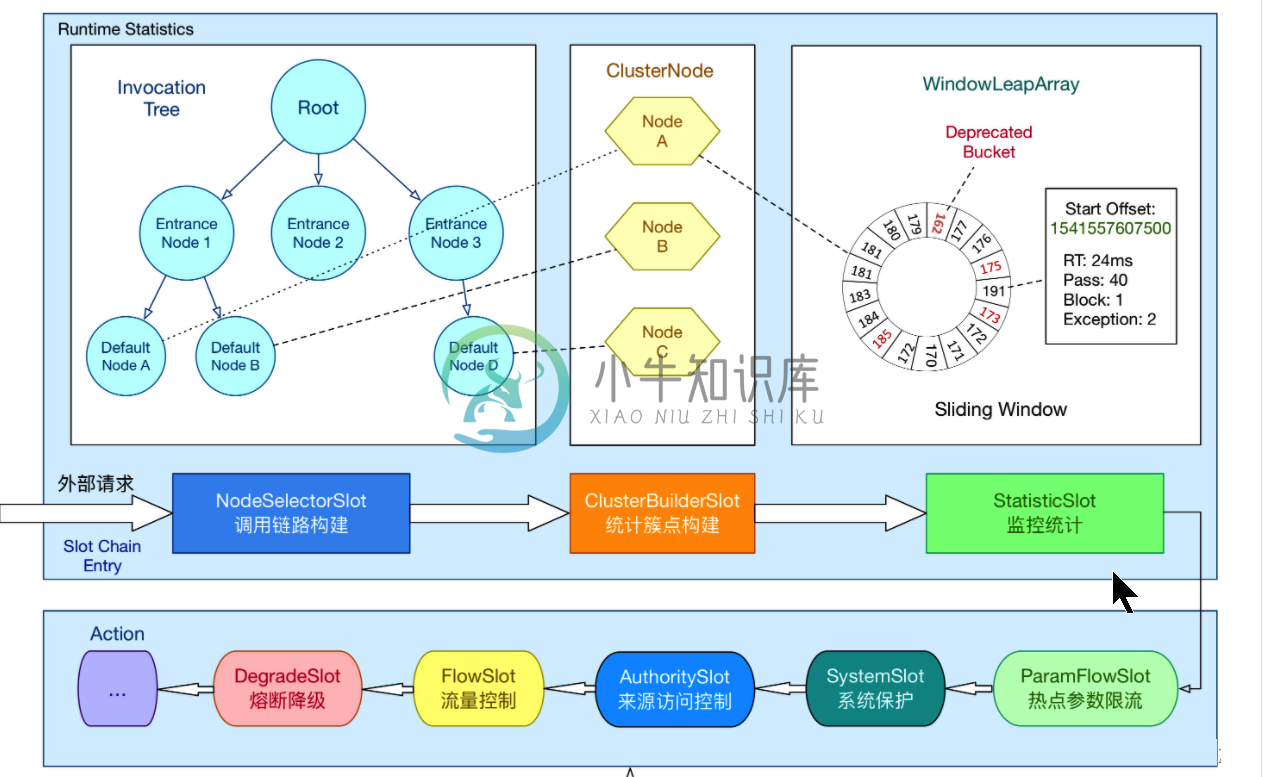 SpringCloud Alibaba之Sentinel工作原理
SpringCloud Alibaba之Sentinel工作原理主要内容:核心介绍,NodeSelectorSlot,ClusterBuilderSlot,StatisticSlot,FlowSlot,DegradeSlot,SystemSlot,ProcessorSlotChain,Context,Entry,Node,StatisticSlot核心介绍 在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用
-
工作在你的项目上
无论是建立一个全新的本地仓库(local repository)或是克隆一个远程仓库(remote repository)到本地计算机,这两者并没有多大的区别。现在在你的计算机上已经拥有了一个 Git 本地仓库了。这也就意味着你可以在这个项目上开始你的工作了,使用任何一个你常用的编辑器来完成对项目文件的修改、创建、删除、移动、拷贝或者是重命名。 概念 文件的状态 一般情况下在 Git 中文件有两种
-
在Maven Central上找到工件的所有直接依赖项
问题内容: 对于Maven Central(或任何其他给定的Nexus存储库)上的工件,我想列出所有直接依赖项。 最初,我考虑过只阅读pom.xml并从依赖项部分收集所有条目。但是我注意到这些条目可能没有版本(由依赖管理提供),或者这些条目可能来自父poms。 我的第二个想法是建立某种人造Maven项目并使用收集相关性。这可能变得复杂。 什么是最直接(也是可靠)的方法? 问题答案: 在Maven插
-
查找员工表MySQL的最高和第二最高薪水
问题内容: 假设您得到以下名为Employee的简单数据库表,该表具有2个列,分别名为Employee ID和Salary: 我想写一个查询,从员工那里选择max(salary)作为max_salary,2nd_max_salary 然后它应该返回 我知道如何找到第二高的薪水 或找到第n个 但我无法弄清楚如何将这2个结果结合起来以获得所需的结果 问题答案: 您可以只运行2个查询作为内部查询以返回2
-
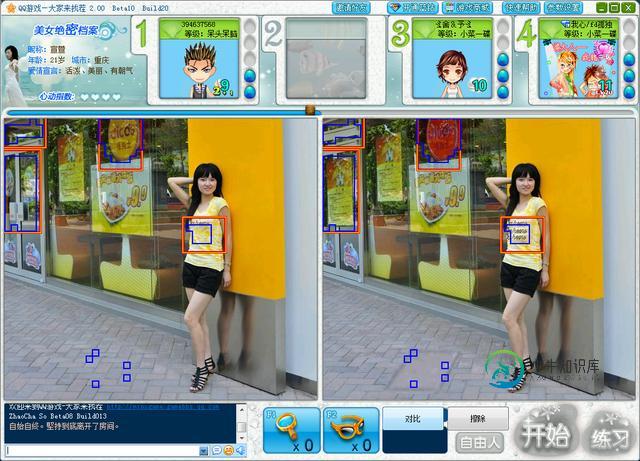 用Python实现QQ游戏大家来找茬辅助工具
用Python实现QQ游戏大家来找茬辅助工具本文向大家介绍用Python实现QQ游戏大家来找茬辅助工具,包括了用Python实现QQ游戏大家来找茬辅助工具的使用技巧和注意事项,需要的朋友参考一下 好久没写技术相关的文章,这次写篇有意思的,关于一个有意思的游戏——QQ找茬,关于一种有意思的语言——Python,关于一个有意思的库——Qt。 这是一个用于QQ大家来找茬(美女找茬)的辅助外挂,开发的原因是看到老爸天天在玩这个游戏,分数是惨不忍睹的
-
 Android studio找不到java。数学工程中的一些方法
Android studio找不到java。数学工程中的一些方法我和科特林在Intellij Idea中实施了一个项目。这是没有错误的工作。这是我的Intellij项目照片,没有错误 longValueExact() Android Studio项目照片: 我打开了java。数学android studio中的BigInteger类,并使用longValueExact()方法: 这意味着我们在Java1.8中有这个类,我们在android studio中添加了
-
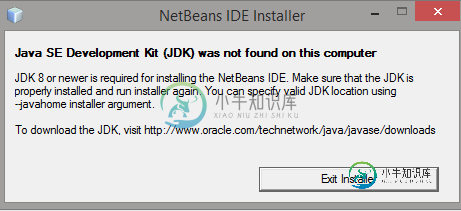 在此计算机上找不到Java SE开发工具包
在此计算机上找不到Java SE开发工具包我在我的PC(windows 8.1)上安装了NetBeans8.1和JDK版本8。我卸载了NetBeans8.1,然后安装了NetBeans8.2。安装后,我运行它,一切工作正常。 在安装NetBeans8.1之后,我卸载了JDK8,然后安装了JDK9。 安装JDK 9后,当我再次尝试运行NetBeans时,它给我的错误是 我已经将JDK9添加到环境路径变量中。
-
JitPack构建失败“错误:找不到构建工件”[重复]
我似乎不明白为什么JitPack无法构建我的库,当我检查构建日志时,我发现了以下错误和警告: 我试图通过遵循这个StackOverflow答案中的建议来解决Java版本错误,但它没有起到任何作用。 我做错了什么?我如何修复它?
-
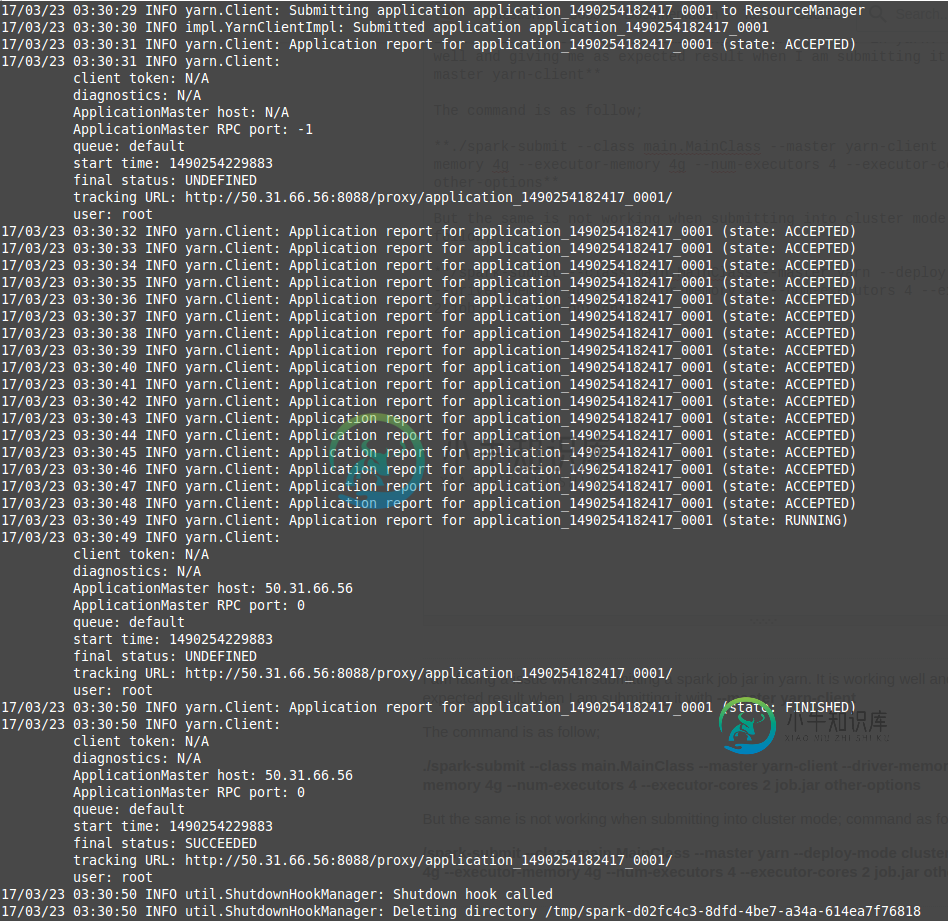 Spark作业对纱线客户端正常工作,但对纱线簇完全不工作
Spark作业对纱线客户端正常工作,但对纱线簇完全不工作我正面临一个问题,当提交一个火花作业罐子在纱。当我用-master yarn-client提交它时,它工作得很好,并给出了我预期的结果 命令如下所示; ./spark-submit--类main.mainclass--主纱--客户端--驱动程序--内存4G--执行器--内存4G--num-执行器4--执行器-核心2 job.jar其他--选项
-
Python USB Serial在空闲状态下工作,但在作为文件运行时不工作
我目前正试图用Python通过通用串行总线写入我的一个Arduino Nano。然而,我发现(使用完全相同的代码),当我将代码键入IDLE时,代码工作得很好,但是当我将其保存到一个文件并试图从那里运行时,由于某种原因,Arduino永远不会收到数据。我检查了两个位置,都使用了正确的Python版本(2.7.9)(不幸的是,由于我正在使用的其他库,我不能使用Python 3)。 我使用的代码是: 当
-
Python-使用熊猫对同一工作簿的多个工作表进行pd.read_excel()
问题内容: 我有一个较大的电子表格文件(.xlsx),正在使用python pandas处理。碰巧我需要那个大文件中两个标签中的数据。选项卡中的一个包含大量数据,另一个仅包含几个正方形单元格。 当我在任何工作表上使用pd.read_excel()时,在我看来整个文件都已加载(不仅仅是我感兴趣的工作表)。因此,当我两次使用该方法(每张纸一次)时,我实际上不得不使整个工作簿被读两次(即使我们仅使用指定
-
工作者、工作者实例和执行者之间的关系是什么?
null
-
服务工作者可以做哪些web工作者做不到的事情?
服务工作者可以做哪些web工作者做不到的事情?或者反之亦然? 看来web工作者是服务工作者功能的一个子集。这是正确的吗?
-
带有服务工作者(pwa)的angular应用程序未按预期工作
与服务人员一起进行脱机工作,从https://angular.io/guide/service-worker-config 应用程序脱机工作正常唯一的问题是,如果我使用应用程序脱机工作正常,但缓存中的文件在服务器上的文件更新时从不更新。如果我使用“installMode”:“lazy”`应用程序无法脱机工作。 以下是。 还尝试了,但仍然缓存未在更改时更新的文件