《咪咕音乐》专题
-
javascript - 音频处理分割?
目前需要用whsiper做语音转录服务,whisper限制25M的大小,请问该如何做这个事情? 目前的需求是 Android iOS Web 都需要这个功能, 目前有几种方案: 方案1 做一个音频分割服务器,然后在做一个转录服务。前端拿到语音文件之后,把语音文件传给音频分割服务器,分割服务器根据波形进行分割,分割完之后传给转录接口。 问题: 这样做的话是不是会造成语音上传多次导致时间较长的问题,因
-
 javascript - 视频切换音轨?
javascript - 视频切换音轨?视频怎么实现切换音轨,实现这种效果,用了videojs一直报错
-
如何检测断开连接的蓝牙音频设备是当前播放音乐流的设备?
我的audio player应用程序当前正在侦听“ACTION\u ACL\u DISCONNECTED”事件,检查BluetoothDevice的意图。EXTRA_DEVICE,并检查该设备的类以查看它是否是BluetoothClass。装置专业AUDIO\u VIDEO设备。如果是这样,那么我想暂停播放。基本上,当蓝牙耳机或汽车连接断开时暂停。 然而,我发现这对一些实际上以其他方式收听的用户来
-
当恢复音乐播放器时,音乐将恢复,但不是“播放”和“暂停”按钮状态
下面是我使用的代码。通过这个代码,所有活动都播放背景音乐。但是当我使用home按钮返回到这个活动时,音乐正常播放,但是抽屉将不会恢复。这意味着,如果播放了音乐,我通过home按钮返回活动,那么播放按钮将显示,而不是暂停按钮,但我希望,如果在resume上播放了音乐,那么按钮将是暂停,如果不是,则显示播放按钮。 你能告诉我在恢复活动时如何使用“播放”和“暂停”按钮吗?
-
如何在音频均衡器中添加立体声,高音选项?
问题内容: 我正在尝试使用小型音频歌曲均衡器。我想在其中添加 高音,立体声等选项,就像在Poweramp播放器中一样。 Poweramp音乐播放器的图像 我成功实现了5个频段的均衡器,如下所示: 上面的代码只是我的均衡器代码的简短摘要。它不会像 我在此处发布的示例那样起作用。。 我也想在均衡器中添加高音,立体声,单声道效果。 我已经像这样实现了低音增强: 我使用了Inbulilt类来增强低音。 如
-
需要文本到语音和用于Linux的语音识别工具
问题内容: 我正在计划编写一个用于Linux的程序,该程序使用文本进行语音和语音识别。什么是最好的工具/库?我是否应该使用Windows才能使用更好的工具?这些工具需要易于从控制台或C程序调用。 问题答案: 对于语音识别,有各种Sphinx。不同的变体各有优缺点,这里有一个Sphinx版本比较的比较。我相信Sphinx 4是Java,但其他都是C。
-
Android音频FFT使用音频记录检索特定频率幅度
问题内容: 我目前正在尝试使用Android实现一些代码,以检测何时通过手机的麦克风播放了多个特定音频频率范围。我已经使用AudioRecord该类设置了该类: 然后读取音频: 执行FFT是我遇到的困难,因为我在这方面的经验很少。我一直在尝试使用此类: Java和Complex类中的FFT一起使用 然后,我发送以下值: 这很容易让我误解了此类的工作原理,但是返回的值到处都是跳跃的,即使在沉默中也不
-
在JavaScript中删除字符串中的重音符号/变音符号
问题内容: 如何从字符串中删除重音符号?尤其是在IE6中,我有类似以下内容: 但是IE6困扰着我,似乎不喜欢我的正则表达式。 问题答案: 使用ES2015 / ES6 String.Prototype.Normalize(), 这里发生两件事: 根据Unicode规范形式,将组合的字形分解为简单的字形。在中端起来表示为+ 。 现在,使用正则表达式字符类来匹配U + 0300→U + 036F范围,
-
C#实现汉字转拼音或转拼音首字母的方法
本文向大家介绍C#实现汉字转拼音或转拼音首字母的方法,包括了C#实现汉字转拼音或转拼音首字母的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#实现汉字转拼音或转拼音首字母的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的C#程序设计有所帮助。
-
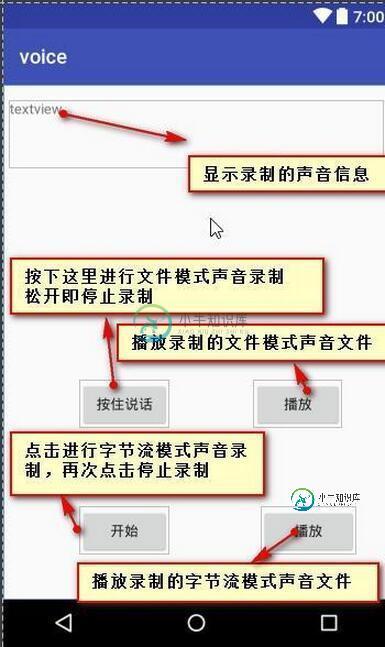 android语音即时通讯之录音、播放功能实现代码
android语音即时通讯之录音、播放功能实现代码本文向大家介绍android语音即时通讯之录音、播放功能实现代码,包括了android语音即时通讯之录音、播放功能实现代码的使用技巧和注意事项,需要的朋友参考一下 在android中,实现录音与语音播放的功能算是比较简单的,但是作为参考,还是很有必要将语音相关的知识做一个简要的记录。 首先,在android中,支持录音支持两种方式。主要包括:字节流模式和文件流模式。用文件流模式进行录音操作比较简单
-
使用WebRTC、Node.js和语音识别引擎的实时语音识别
A.我正在努力实现的目标。 允许在网络浏览器内进行实时语音识别的网络应用程序(像这样)。 B.我目前正在考虑使用的技术来实现A。 JavaScript 节点。js WebRTC 微软语音API或Pocketsphinx。js或其他东西(不能使用Web语音API) C.非常基本的工作流程 Web浏览器建立到节点服务器的连接(服务器充当信令服务器,还提供静态文件) D.问题 将节点。js是否适合实现C
-
我如何在freetts中将输出语音存储到音频文件
问题内容: 我正在尝试将freetts用于一个简单的Java应用程序,但是我遇到了一个问题,谁能告诉我如何在我的程序中将输出的语音(从文本转换为语音)保存为wave文件。我想通过代码做到这一点。 这是示例提供的示例helloworld应用程序 这段代码可以正常工作,我想将输出保存为磁盘上的音频文件。 谢谢普兰尼 问题答案: 我想出了方法,您只需要简单地使用传递文件名和文件类型,样本声明就应该像这样
-
Twilio:取消进入会议时被静音的参与者的静音
https://www.twilio.com/docs/voice/twiml/conference#属性-静音 它起作用了,所有参与者都静音了。现在我想知道如何允许每个用户使用Android上的Twilio语音SDK单独取消静音。 这很奇怪,因为在接收调用时,是即使调用是静音的。然后,当尝试使用取消对调用的静音时,不会发生任何事情,调用仍然是静音的。
-
如何使用谷歌云语音API进行实时语音识别?
我正在努力寻找使用谷歌云语音API进行实时连续语音识别的例子。我的要求是使用麦克风,检测语音,并在用户说话时进行转录。 我知道他们的RESTAPI没有这种支持,所以我研究了grpc示例,包括他们提供的示例。但它们似乎都是用户可以上传音频并检测语音的例子。 我在Java,谷歌grpc也支持java。有人遇到一个很好的例子,展示了如何通过麦克风持续进行这种识别吗?
-
如何进行实时语音识别|谷歌云语音到文本
我正在尝试从扬声器转录音频 我正在将声音从扬声器传送到节点。js文件(https://askubuntu.com/a/850174) 这是我的抄本。js公司 但谷歌云语音到文本在1分钟内对流媒体识别有一个限制。所以我有一个错误“超过了允许的最大流持续时间65秒” 如何将流拆分为以静默为拆分器的块,或拆分为持续30秒的块?