《咪咕音乐》专题
-
 录音复盘3
录音复盘3武汉-小米-java 进度:一面后三天约的二面,二面挂 一面(电话面): 1、自我介绍(1min+) 2、项目结合八股,随机应变(24min+) - 锁体系介绍 - 可重入的原理 - AQS了解多少 - 集合体系 - ArrayList的扩容机制 - HashMap的resize - 线程安全的集合 - ConcurrentHashMap的线程安全 - springboot的启动流程 3、实习经历
-
如何用JS静音页面中的所有声音?
问题内容: 如何使用JS静音页面上的所有声音? 这应该使HTML5 和标记以及Flash和好友无效。 问题答案: 规则1:切勿在页面加载后启用音频自动播放。 无论如何,我将使用jQuery显示HTML5: Flash Media Player取决于暴露给JavaScript的自定义API(希望)。 但是您就知道了,遍历媒体,检查/存储播放状态以及静音/取消静音。
-
 Python实现变声器功能(萝莉音御姐音)
Python实现变声器功能(萝莉音御姐音)本文向大家介绍Python实现变声器功能(萝莉音御姐音),包括了Python实现变声器功能(萝莉音御姐音)的使用技巧和注意事项,需要的朋友参考一下 登录百度AL开发平台 在控制台选择语音合成 创建应用 填写应用信息 在应用列表获取(Appid、API Key、Secret Key) 6. 安装pythonsdk 安装使用Python SDK有如下方式: 安装使用Python SDK有如下方式: 如
-
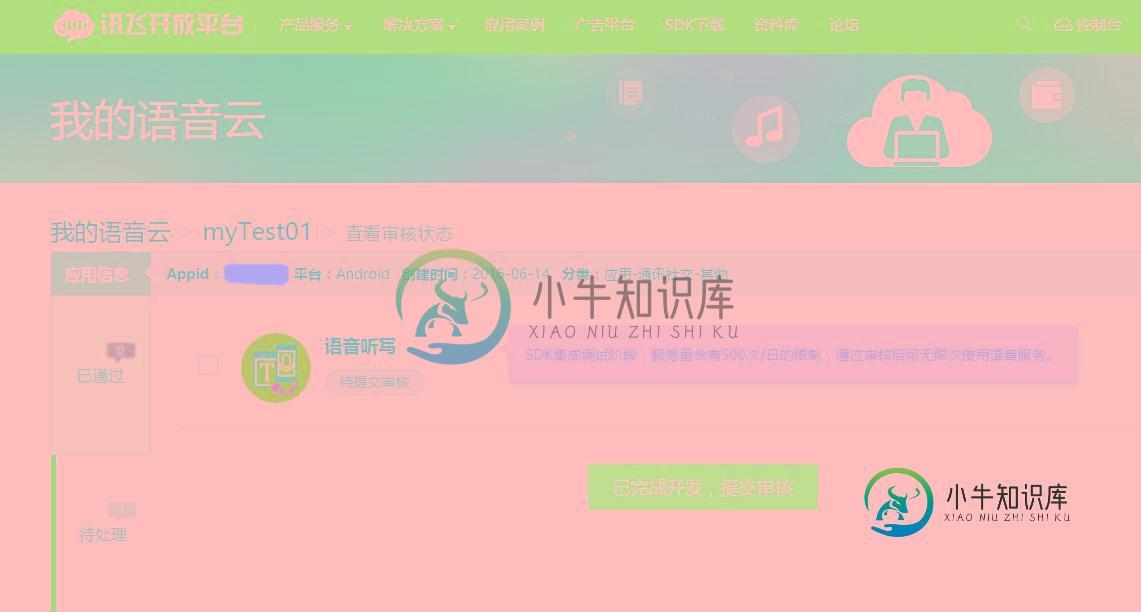 Android基于讯飞语音SDK实现语音识别
Android基于讯飞语音SDK实现语音识别本文向大家介绍Android基于讯飞语音SDK实现语音识别,包括了Android基于讯飞语音SDK实现语音识别的使用技巧和注意事项,需要的朋友参考一下 一、准备工作 1、你需要android手机应用开发基础 2、科大讯飞语音识别SDK android版 3、科大讯飞语音识别开发API文档 4、android手机 关于科大讯飞SDK及API文档,请到科大语音官网下载:http://www.xfyun
-
如何打印辅音比元音多的字符串?
输入20个字符串的数组。制作一个程序,打印出辅音多于元音的字符串,其中字母“r”至少重复3次。 我相信问题出在我的 if 循环中,但不知何故我不明白为什么它不能正常工作。它会打印我输入的每个字符串。 这是我写的代码:
-
C#语音合成器-“系统上未安装语音”
我试着用将文本转换为语音,但不起作用。 我正在使用64位Windows7和VisualStudio2010(我想是用.NETFramework 4.0吧?) 该方案: 发生在第
-
如何在iOS语音API上检测语音启动
我有一个在XCode/目标C开发的iOS应用程序。它使用iOS语音应用编程接口来处理连续语音识别。它正在工作,但是我想在语音开始时将麦克风图标变成红色,我还想检测语音何时结束。 我实现了接口SFSpeechRecognitionTaskDelegate,该接口提供了onDetectedSpeechStart和speechRecognitionTask:Did假想Transcription:的回调,
-
Twilio视频连接静音可编程语音通话?
null 提前感谢您的任何帮助:)
-
不一致js bot,临时静音命令不静音
如前所述。我正在尝试为我的Discord机器人创建一个临时静音命令。我遇到的问题是,它创建了一个静音的角色,但即使我更改了烫发,用户仍然可以编写消息。除此之外,我还收到了以下弃用警告: (节点:15956)弃用警告:集合#查找:改为传递函数
-
语音识别将单词拆分为音素级别
我正在考虑为我的母语开发语音识别软件,我正在考虑为此使用CMUSphinx-4。有一个CMU字典文件,其中包含英语单词,这些单词通过原始单词的拆分映射到其音位边界。例如,已放弃=
-
录制/保存语音识别意图中的音频
我想保存/录制Google识别服务用于语音转文本操作的音频(使用识别意图或语音识别器)。 我经历了很多想法: > 使用了媒体录制器:不工作。这破坏了语音识别。mic只允许一次操作 在执行语音到文本API复制临时音频文件之前,尝试查找识别服务在何处保存该文件,但未成功 我几乎绝望了,但我只是注意到Google Keep应用程序正在做我需要做的事情!我使用logcat调试了一点keep应用程序,该应用
-
音频:改变字节数组中样本的音量
我正在使用这个方法将WAV文件读到字节数组(如下所示)。现在我已经将它存储在字节数组中,我想改变声音的音量。 编辑:根据要求提供音频格式的一些信息:
-
Android音频流正弦音发生器异常行为
第一次海报在这里。我通常喜欢自己找到答案(无论是通过研究还是反复试验),但我在这里被难住了。 我正在努力做:我正在建立一个简单的android音频合成器。现在,我只是在实时播放正弦音调,在用户界面中有一个滑块,可以随着用户的调整而改变音调的频率。 我是如何构建它的:基本上,我有两个线程--一个工作线程和一个输出线程。工作线程只是在每次调用其tick()方法时用正弦波数据填充缓冲区。一旦缓冲区被填满
-
java - 如何获取音频文件的音调信息?
想获取 mp3 或者 wav 文件的音调信息, 那个可以量化的音调 输入一段音频 输出量化的音调, 跟随着时间, 1 秒一个, 3,3,9,2,10,13.....
-
getusermedia - 如何优化实时音频播放以消除声音断续与音量波动?
一边说一边播放(比如实时听到自己唱的歌),使用如下代码实现,即使带着耳机,声音也是断断续续,时大时小,有没有方法解决呢?