《邮储面试》专题
-
 滴滴面试-前端-一面+二面
滴滴面试-前端-一面+二面滴滴基本上面试简单,八股题为主。这里写几个不太常见记得比较清晰的问题吧。 TLS四次握手 node事件循环 fork和vfork Linux和window系统的内存管理区别 虚拟内存介绍 Vue differ原理 Vue.nextTick功能和实现 手写题目 实现一个函数,传入一个Promise的数组,实现数组内的顺序链式调用,我的方法就是遍历+await 手写一个异步相关的输出题,涉及到Prom
-
JS localStorage存储对象,sessionStorage存储数组对象操作示例
本文向大家介绍JS localStorage存储对象,sessionStorage存储数组对象操作示例,包括了JS localStorage存储对象,sessionStorage存储数组对象操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS localStorage存储对象,sessionStorage存储数组对象操作。分享给大家供大家参考,具体如下: 一、前言 最近在用angu
-
为什么没有快速存储类的存储类型属性?
问题内容: 通过Swift编程语言,我惊讶地发现,与结构和枚举不同,类不支持存储的类型属性。 这是其他OO语言的共同特征,因此我认为有充分的理由他们决定不允许它。但是我无法猜测出这个原因是什么,尤其是由于结构(和枚举)拥有它们。 难道仅仅是Swift的早期开发,还没有实现吗?还是在语言设计决策背后有更深层的原因? 顺便说一句,“存储类型属性”是Swift术语。在其他语言中,这些可能称为类变量。示例
-
如何将小端存储模式转为大端存储模式?
本文向大家介绍如何将小端存储模式转为大端存储模式?相关面试题,主要包含被问及如何将小端存储模式转为大端存储模式?时的应答技巧和注意事项,需要的朋友参考一下
-
Azure存储帐户指标仅对经典存储帐户可见
我测试了在新的Azure门户中创建经典存储帐户(manage.windowsazure.com)和“新”存储帐户。将它们设置为类似的,并运行相同的代码来创建和配置队列。但指标仅显示门户中的经典存储帐户(能够在新门户中看到这两个帐户) 我已经像这样设置了ServiceProperties,并且可以在获取服务属性或查看Azure门户时成功地看到保存的这些更改。 当我使用Microsoft Azure
-
Micronaut数据:没有为存储库配置备份存储操作
当我尝试使用inmemory h2数据库和Jpa配置micronaut数据时,出现以下异常 我一直在关注文档 我使用maven作为构建工具从命令行创建了该项目。我有以下几点 我还添加了这样的注释处理器 我的实体类和存储库类完全如指南中所述。当我尝试使用存储库保存时,我得到了这个异常 我已经调查过了。这完全不同,对我的问题没有帮助。 有趣的是,如果我改变micronaut数据注释处理器的顺序,或者我
-
Spring Boot-Azure密钥存储库管理存储库访问机密
同一空间/存储库中机密的逻辑分组 HSM的可能性 日志记录/审核 检索/更改机密的一个位置,许多应用程序可能依赖该位置而不触及应用程序。 我不知道如何在我的Spring Boot应用程序中处理存储库访问。当我使用azure-key-vault spring boot Starter时,我必须设置Applications.Properties中的访问权限,如本教程:如何使用spring boot S
-
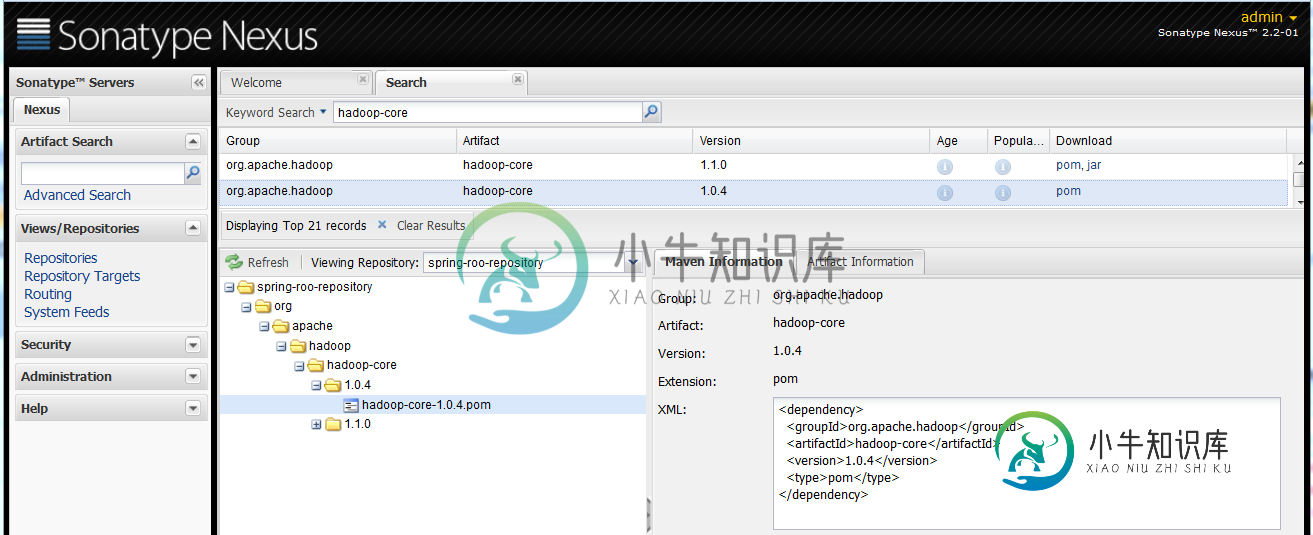 2个maven存储库中存在的工件-存储库冲突
2个maven存储库中存在的工件-存储库冲突这很可能通过Nexus配置得到解决。 我们使用maven进行hadoop开发。Nexus被配置为所有存储库的镜像,存储库被添加到Nexus公共组中。(参见Nexus中有没有更好的配置存储库的方法?) 我发现hadoop-core工件版本1.0.4显示来自spring-roo-repositoryhttp://spring-roo-repository.springsource.org/releas
-
如何在Java密钥存储库中存储Bouncy Castle PGP密钥?
对于PGP想要使用的签名和加密密钥,我是否可以使用2个JCE、RSA或DSA keypairs?把它们保存在密钥库中,当我想使用这些密钥时,只需按需重建PGP基础结构?
-
Bouncy Castle密钥存储(BKS):java.io.IOException:密钥存储的版本错误
我必须连接到一个基于REST的WebService。 (https://someurl.com/api/lookup/jobfunction/lang/en) 在IE或chrome浏览器中,当我尝试访问这个URL时,我会得到一个证书,我必须信任它并接受它才能继续,然后我必须输入用户名和密码,然后我会得到JSON响应。 同样的事情,我必须为一个android应用程序编程。 > 尝试使用自定义Easy
-
将证书添加到密钥存储区和信任存储区
证书、私钥(客户端)和客户端证书都是pem格式的,我必须将它们添加到信任存储区和密钥存储区中。我该怎么做呢?到目前为止,我在cmd(windows)中有命令: > 要生成PKC(key:客户端私钥,cert:客户端cert,CA:CACERT):openssl pkcs12-inKey key.pem-in cert.pem-export-out keystored.p12-certfile CA
-
在Azure表存储中存储应用程序日志的策略
我要确定一个在Azure表存储中存储日志信息的好策略。我有以下内容: PartitionKey:日志的名称。 ROWKEY:倒置的日期时间刻度, 这里唯一的问题是分区可能会变得非常大(数百万个实体),并且大小会随着时间的推移而增加。 但尽管如此,所执行的查询类型将始终包括(不扫描)和筛选器(小扫描)。 例如(在自然语言中): 如果查询同时在和上完成,那么我理解分区的大小并不重要。
-
如何将spark DataFrame作为CSV存储到Azure Blob存储器中
我正试图从本地Spark集群将Spark DataFrame存储为Azure Blob存储中的CSV 首先,我用Azure Account/Account键设置配置(我不确定什么是正确的配置,所以我已经设置了所有这些) 似乎这个问题已经在数据库论坛上报告了!! 在Azure Blob上存储DataFrame的正确方法是什么?
-
将文件列表从S3存储桶复制到S3存储桶
有没有一种方法可以将文件列表从一个S3存储桶复制到另一个存储桶?两个S3存储桶都在同一个AWS帐户中。我可以使用aws cli命令一次复制一个文件: 然而,我有1000份文件要复制。我不想复制源存储桶中的所有文件,因此无法使用sync命令。有没有一种方法可以用需要复制的文件名列表来调用一个文件,从而自动化这个过程?
-
 对Azure库伯内特斯pods进行线程转储/堆转储
对Azure库伯内特斯pods进行线程转储/堆转储我们正在用java编写的Azure kubernetes上运行我们的kafka流应用程序。我们是库伯内特斯的新手。为了调试一个问题,我们需要对正在运行的pod进行线程转储。 以下是我们进行转储的步骤。 > < li> 使用以下docker文件构建我们的应用程序。 提交包含以下部署yaml文件的映像 apiVersion: apps/v1种类:部署元数据:名称:my-application-v1.0