《万科》专题
-
动态数据库查询可获取超过 100 万的数据 - Java 中的示例
我正在尝试运行一个查询并获取所有项目。似乎没有检索到所有项目,我需要使用start键再次运行查询。 从文件中 对于Query或Scan操作,如果操作没有返回表中所有匹配的项目,DynamoDB可能会返回LastEvalatedKey值。要获取匹配项的完整计数,请从上一个请求中获取LastEvalatedKey值,并在下一个请求中将其用作ExunisiveStartKey值。重复此操作,直到Dyna
-
第 15 章:万人之敌,通过注解给属性注入配置和 Bean 对象
作者:小傅哥 博客:https://bugstack.cn 原文:https://mp.weixin.qq.com/s/GNLA10AimmxUSZ0VoDI_xA 一、前言 写代码,就是从能用到好用的不断折腾! 你听过扰动函数吗?你写过斐波那契(Fibonacci)散列吗?你实现过梅森旋转算法吗?怎么 没听过这些写不了代码吗!不会的,即使没听过你一样可以写的了代码,比如你实现的数据库路由数据总是
-
如果给你500万做创业基金,做一款游戏App,你要怎么打算?
本文向大家介绍如果给你500万做创业基金,做一款游戏App,你要怎么打算?相关面试题,主要包含被问及如果给你500万做创业基金,做一款游戏App,你要怎么打算?时的应答技巧和注意事项,需要的朋友参考一下 做一款像素风游戏。 100万用于剧情设计 100万用于音乐及配音 100万用于关卡设计(出其不意的那种,例如undertale) 50万用于发放薪资。由于是像素风游戏,所以UI成本不高,只需要设计
-
使用Python快速打开一个百万行级别的超大Excel文件的方法
本文向大家介绍使用Python快速打开一个百万行级别的超大Excel文件的方法,包括了使用Python快速打开一个百万行级别的超大Excel文件的方法的使用技巧和注意事项,需要的朋友参考一下 知乎上有同学求助说,当他试图打开一个20M左右的excel文件时,无论是使用pandas的read_excel,还是直接使用xlrd或者openpyxl模块,速度都慢到无法忍受的程度,耗时大约1分钟左右。 真
-
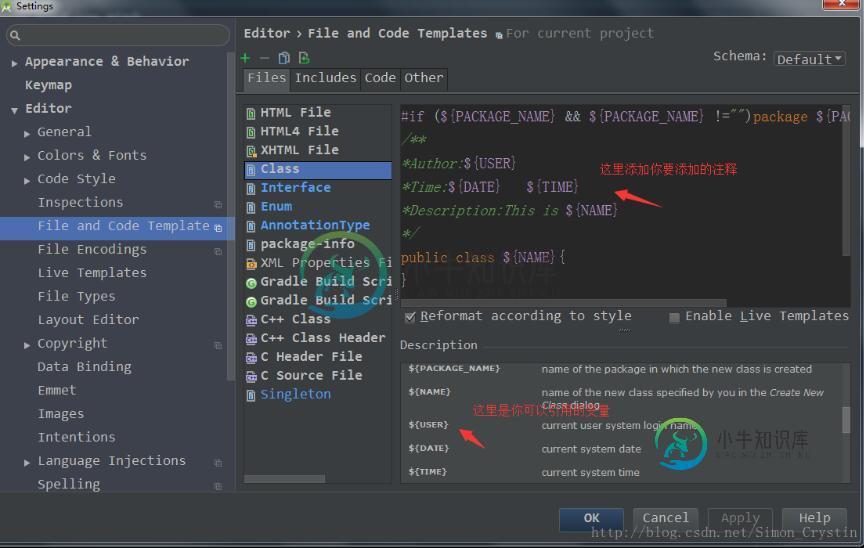 Android Studio自定义万能注释模板与创建类,方法注释模板操作
Android Studio自定义万能注释模板与创建类,方法注释模板操作本文向大家介绍Android Studio自定义万能注释模板与创建类,方法注释模板操作,包括了Android Studio自定义万能注释模板与创建类,方法注释模板操作的使用技巧和注意事项,需要的朋友参考一下 代码的注释是我们平时必须面对的问题,今天我们就来看看如何自定义属于自己的注释模板。提高我们的开发效率。 这里,我们讲解两种自定义模板。 1.新建的类自动生成的注释; 2.自定义注释模板。 新建
-
 mysql优化小技巧之去除重复项实现方法分析【百万级数据】
mysql优化小技巧之去除重复项实现方法分析【百万级数据】本文向大家介绍mysql优化小技巧之去除重复项实现方法分析【百万级数据】,包括了mysql优化小技巧之去除重复项实现方法分析【百万级数据】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql优化小技巧之去除重复项实现方法。分享给大家供大家参考,具体如下: 说到这个去重,脑仁不禁得一疼,尤其是出具量比较大的时候。毕竟咱不是专业的DB,所以嘞,只能自己弄一下适合自己去重方法了。 首先按照
-
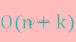 对一千万个整数排序,整数范围在[-1000,1000]间,用什么排序最快?
对一千万个整数排序,整数范围在[-1000,1000]间,用什么排序最快?本文向大家介绍对一千万个整数排序,整数范围在[-1000,1000]间,用什么排序最快?相关面试题,主要包含被问及对一千万个整数排序,整数范围在[-1000,1000]间,用什么排序最快?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 在以上的情景下最好使用计数排序,计数排序的基本思想为在排序前先统计这组数中其它数小于这个数的个数,其时间复杂度为,其中n为整数的个数,k为所有数的范围,此场
-
String#indexof:为什么用JDK代码比较1500万个字符串比我的代码快?
答案可能存在于某个地方,但我找不到。我从我正在创建的一个算法中得出这个问题。实质上是,如果s1包含s2,则返回true,忽略希腊语/英语字符差异。例如,字符串“nai,of course”包含字符串“vaxi”。不过,这与我的问题无关。
-
从Postgres DB中包含1000万条记录的表中获取记录的性能改进
我有一个分析表,其中包含1000万记录,为了生产图表,我必须从分析表中获取记录。其他几个表也加入到这个表中,目前正在获取数据但它需要大约10分钟,即使我已经索引了加入的列,并且我在Postgres中使用了物化视图。但仍然性能很低,从物化视图执行选择查询需要5分钟。 请建议我一些技巧,以便在5秒内得到结果。我不想改变数据库存储结构,因为要支持它,需要做很多代码更改。我想知道是否有一些内置的方法可以提
-
需要有关将数百万时间序列数据有效插入Cassandra DB的建议
我想使用Cassandra数据库来存储测试站点的时间序列数据。我正在使用“时间序列数据建模入门”教程中的模式2,但不是将日期存储为日期来限制行大小,而是将其存储为一个<code>int</code>,用于计算自1970年1月1日以来的天数,该值的时间戳是自纪元以来的纳秒数(我们的一些测量设备非常精确,需要精度)。我的值表如下所示: 我创建了一个简单的基准,考虑到使用异步并为批量加载而不是批量准备语
-
如何在Java中列出200万个文件目录而又没有“内存不足”异常
问题内容: 我必须处理要处理的大约200万个xml目录。 我已经解决了使用队列在机器和线程之间分配工作的处理过程,一切正常。 但是现在最大的问题是读取目录中的200万个文件以逐步填充队列的瓶颈。 我尝试使用该方法,但是它给了我一个Java 异常。有任何想法吗? 问题答案: 首先,您是否有可能使用Java 7?那里有一个和和,它们应该在内存限制内起作用。 否则,我唯一想到的方法是使用 始终返回的过滤
-
上千万或上亿的数据,统计其出现次数最多的前N个数据?
本文向大家介绍上千万或上亿的数据,统计其出现次数最多的前N个数据?相关面试题,主要包含被问及上千万或上亿的数据,统计其出现次数最多的前N个数据?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
 使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解
使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解本文向大家介绍使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解,包括了使用Go基于WebSocket构建千万级视频直播弹幕系统的代码详解的使用技巧和注意事项,需要的朋友参考一下 (1)业务复杂度介绍 开门见山,假设一个直播间同时500W人在线,那么1秒钟1000条弹幕,那么弹幕系统的推送频率就是: 500W * 1000条/秒=50亿条/秒 ,想想B站2019跨年晚会那次弹幕系统
-
如何过滤2个包含数百万个相同id项目的巨大列表[重复]
这是我的2个清单上有超过百万的项目。两者都具有相同ID的相同项。ID在字符串中。我只需要一个不一样的ID的项目。我是这样做的。但我确信一定有更好的解决办法,而且具有高度的持久性:- 我尝试使用流,但我做不到。我想用流API应该更好。请建议我有什么改进之处。
-
 【万字面经分享】双非无顶会如何突出重围斩获大厂算法offer
【万字面经分享】双非无顶会如何突出重围斩获大厂算法offerHello 大家好,我是棒棒鸡,秋招已上岸某头部科技公司算法工程师。 24 届毕业的同学们马上也要开始投简历找实习了,不少同学觉得自己现在没有顶会不敢投算法岗,这里我就从去年自己找实习的经历来跟大家分享一下我的一些看法以及一些面经,希望能帮到大家少走弯路,早日拿到自己心仪的 offer。 那先简单介绍一下我的背景: 学历:某双非本(自动化,绩点中上),保研至某双非院校(计科) 本科两届 RoboM