《量化》专题
-
利用并发对函数进行向量化
问题内容: 对于简单的神经网络,我想将一个函数应用于gonum的所有值。 Gonum有一个用于密集矩阵的方法,但没有用于向量的方法,因此我是手工完成的: 这似乎是并发执行的明显目标,所以我尝试了 这不起作用,也许不是意外的,因为它没有以结尾,因为return语句(完成所有工作)紧随其后。 我的问题是:如何使用并发将函数应用于gonum向量的每个元素? 问题答案: 首先请注意,这种并发计算的尝试假定
-
C ++静态成员变量及其初始化
本文向大家介绍C ++静态成员变量及其初始化,包括了C ++静态成员变量及其初始化的使用技巧和注意事项,需要的朋友参考一下 静态C ++成员变量是使用static关键字定义的。类中的静态成员变量由所有类对象共享,因为在内存中只有它们的一个副本,而与该类的对象数量无关。 如果没有以任何其他方式初始化静态类成员变量,则在创建类的第一个对象时将其初始化为零。 给出了一个演示静态成员变量及其在C ++中的
-
带有jquery的Ajax Google可视化API量规
问题内容: 我正在寻找创建一个通过ajax更新的仪表盘仪表。下面是我的代码。我有ajax代码,但不确定如何更新量规。有什么建议? 阿贾克斯代码… foreach($ obj-> sensor as $ unit){if($ unit-> label ==“ Temp”){echo $ unit-> tempf。“ F”; }} 问题答案: 您也可以使用相同的代码进行更新。您需要创建一个新的数据表实
-
Java-变量可能尚未初始化错误
问题内容: 当我尝试编译时: 我得到这些错误: 在我看来,我在方法的顶部初始化了它们。怎么了 问题答案: 你声明了它们,但没有初始化它们。初始化它们是将它们设置为等于一个值: 因为未初始化变量,但在循环中增加了变量(例如),因此会收到错误消息。 Java原语具有默认值,但如下一位用户所述 当声明为类成员时,它们的默认值为零。局部变量没有默认值
-
实例变量初始化程序的顺序
问题内容: 直观上似乎很清楚,在Java中,实例变量初始化器是按照它们在类声明中出现的顺序执行的。 在我正在使用的JDK中,似乎确实是这种情况。例如,以下内容: 打印(换句话说,y选择的默认值z)。 实际可以保证此顺序吗?我一直在浏览JLS,找不到任何明确的确认。 问题答案: 是的。 se7 JLS在12.5执行部分中介绍了实例变量的初始化顺序: … 4.执行此类的实例初始值设定项和实例变量初始值
-
从PHP中的变量实例化一个类?
问题内容: 我知道这个问题听起来很模糊,因此我将通过一个示例来使其更加清楚: 这就是我要做的。你会怎么做?我当然可以这样使用eval(): 但是我宁愿远离eval()。没有eval(),有没有办法做到这一点? 问题答案: 首先将类名放入变量中: 这通常是您将以Factory模式包装的东西。
-
numpy矢量化弄乱了数据类型(2)
问题内容: 我出现了不想要的行为,即,它更改了进入原始函数的参数的数据类型。我最初的问题是关于一般情况的,我将使用这个新问题来提出更具体的情况。 (为什么要问第二个问题?为了说明问题,我创建 了一个关于更具体案例 的问题-从具体问题到更一般的问题总是比较容易。而且我 单独 创建了这个问题,因为我认为这是有助于保持一般情况以及对一般情况的答复(应该找到),而不会因为考虑解决任何特定问题而受到“污染”
-
速度优化:私有和公共变量-Java
问题内容: 我纯粹是出于问题的速度方面而问这个问题。 在对象是私有或公共(Java)时从对象获取值之间在速度上有什么区别? 我知道我可以测试它,但是如果任何人都知道,它就不会受伤:)预先感谢! 问题答案: 公共和私有访问无非就是在编译时确定您是否有权访问变量。在运行时,它们完全相同。这意味着,如果您可以诱使JVM认为您具有访问权限(通过反射,不安全或修改字节码),则可以。公共和私人只是编译时间信息
-
何时在C#中初始化静态变量?
问题内容: 我想知道静态变量(在类中)何时出现在图片中(初始化)?是在实例构造函数首次调用之后还是在类加载之后?什么时候加载类? 问题答案: 哦,那很复杂。这取决于是否设置了标志,而标志(在C#中)又取决于是否有静态构造函数。更糟的是;在.NET 4中, 我相信 行为发生了变化,使其比以前更加“懒惰”。 坦白说,我不会在此处编写任何特定行为的代码。简单:只要您使用常规代码访问静态字段,它们就会在尝
-
如何在gpu上运行伪量化图形?
我从这里下载了一个量化的mobilenet,这个图包含训练期间的假量化节点,以模拟测试时的输出。我想收集这个网络最后一个逐点卷积层的输出。 量化冻结模型包含额外的fc、softmax等层,对我的应用程序没有用。 我有以下代码用于加载图形。 然后使用ses运行。run(),但是我观察到卷积层的输出没有像在移动设备上运行时那样被量化(8位)。 在pc上运行代码时,如何生成与移动设备上相同的输出。 tf
-
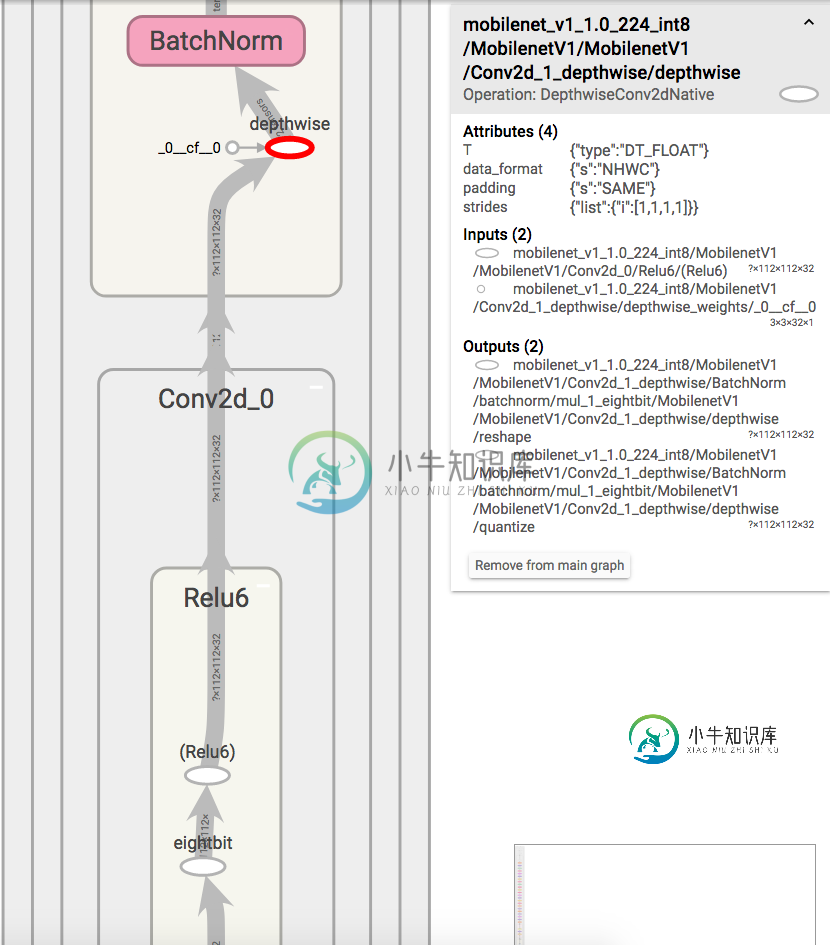 量化TensorFlow MobileNet模型中的浮点运算
量化TensorFlow MobileNet模型中的浮点运算正如您在TensorFlow中实现的量化MobileNet模型的屏幕截图中看到的那样,仍然有一些浮动操作。量化是通过graph_transform工具在TensorFlow中完成的。 图像中的红色椭圆在右侧大小文本框中有其描述。“depthwise”是一个“depthwiseConv2Native”操作,需要“DT_FLOAT”输入。 尽管较低的Relu6执行8位量化操作,但结果必须经过“(Rel
-
如何将PReLU合并到量化模型中?
我试图量化一个使用的模型。用替换是不可能的,因为它会严重影响网络性能,甚至毫无用处。 据我所知,在Pytorch中不支持量化。因此,我尝试手动重写这个模块,并使用以绕过此限制。 这就是我到目前为止提出的问题: 对于替换: 基本上,我读取了现有prelu模块的学习参数,并在一个新模块中自己运行计算。该模块似乎在某种意义上工作,它没有失败整个应用程序。 然而,为了评估我的实现是否真的正确并产生与原始模
-
在FPGA/pure python上运行量化tensorflow模型
我有一个在keras中训练的模型,这是一个在MNIST数据集上训练的简单模型。 我试图做的是重写这个模型并在FPGA设备上运行。为了做到这一点,我想充分了解量化模型是如何工作的。 首先,我用训练后的量化将这个模型转换为。tflite格式和UINT8精度(https://www.tensorflow.org/lite/performance/post_training_quantization).
-
全量化tensorflow lite模型的输入图像
我已经训练了一个简单的CNN模型在Ciafer-10上使用假量化(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/quantize)。然后我用toco生成了一个. tflite文件。现在我想使用一个python解释器来测试tflite模型。 因为我用了tf。形象在训练期间,按图像标准化减去平均值并除以方
-
TensorFlow-批量归一化在回归中失败?
我用TensorFlow来解决一个多目标回归问题。具体地说,在具有逐像素标记的卷积网络中,输入为图像,标签为“热图”,其中每个像素具有浮点值。更具体地说,每个像素的地面真值标记的下界为零,虽然技术上没有上界,但通常不会大于1e-2。 在不进行批量归一化的情况下,该网络能够给出合理的热图预测。通过批量归一化,网络需要很长时间才能获得合理的损耗值,而它所做的最好的工作就是使每个像素都成为平均值。这是使