《集度》专题
-
公共集合框架包
网上可能找不到的集合框架(暂时只有区间树的一个扩展) 给定区间范围[1,5],[1,6],[2,10],[6,10],[4,19],[5,20],返回关键值“10”的所有区间范围[2,10],[6,10],[4,19],[5,20]。 红黑树部分使用JDK自带的TreeMap,在此之上进行扩展。 声明:OSCHINA 博客文章版权属于作者,受法律保护。未经作者同意不得转载。 注意:下载时需要SVN客户端!
-
python - temu数据的采集?
怎么用python来采集temu.com的商品数据,有什么反爬措施,怎么破解? 怎么用python来采集temu.com的商品数据,有什么反爬措施,怎么破解?
-
 欢聚集团java面经
欢聚集团java面经自我介绍 线程跟进程的区别 了解Nginx的进程模型吗?location的参数的作用?, ThreadLocal的作用,使用的注意事项(内存泄露) 线程池的几个参数 关闭线程池的方法 volatile关键字的作用 你是怎么样保证mysql跟redis的一致性呢? 先更新数据库,然后再删除缓存的这个策略,这种做法有什么缺点吗? Rocketmq怎么保证消息幂等性? 常用的Linux命令有哪一些? 要
-
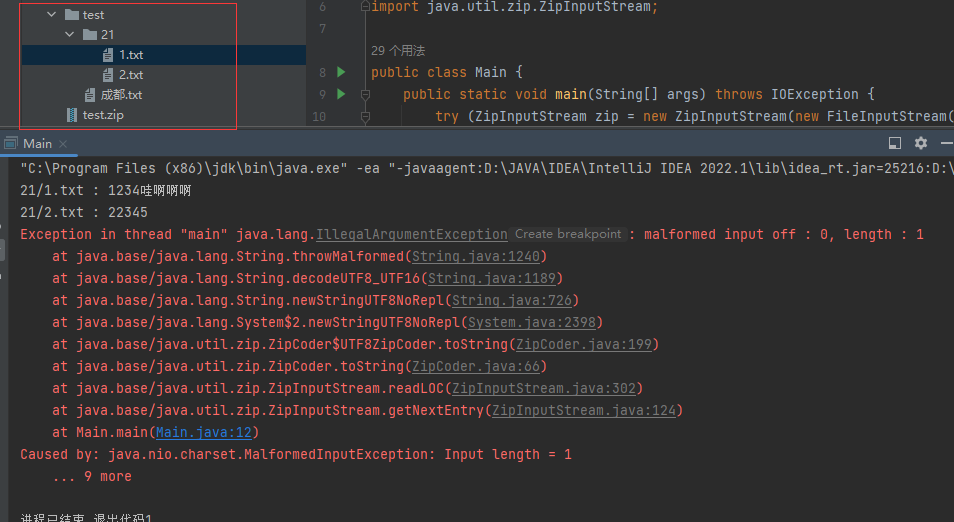 java - ZipInputStream 指定字符集?
java - ZipInputStream 指定字符集?没有用呢,中文的文件、文件夹仍会报错(malformed input off : 1, length : 1)。 这里都有注释的嘛,为什么会这样?
-
如何将嵌套的Scala集合转换为嵌套的Java集合
问题内容: 我在Scala和Java之间遇到编译问题。 我的Java代码需要一个 我的scala代码有一个 我收到编译错误: 似乎scala.collection.JavaConversions不适用于嵌套集合,即使Vector可以隐式转换为Iterable。除了遍历scala集合并手动进行转换之外,我还能做些什么使这些类型起作用? 问题答案: 应该弃用恕我直言。您最好使用来明确说明转换的时间和地
-
在Java集合上进行迭代时从集合中删除项目
问题内容: 我希望能够在迭代过程中从集合中删除多个元素。最初,我希望迭代器足够聪明,以使下面的幼稚解决方案能够正常工作。 但这会引发一个错误。 请注意,就我所知,iterator.remove()无法正常工作,因为我需要一次删除多个内容。还假设不可能确定“即时”删除哪些元素,但是可以编写该方法。在我的特定情况下,要确定要在迭代过程中删除的内容,将占用大量内存和处理时间。由于内存限制,也无法制作副本
-
在Redis中从一系列排序集中创建一个新集合
问题内容: 我有许多排序后的集合用作系统上的二级索引,用户查询可能会碰到其中的一些。 要使用这些索引来使所有30岁以下且得分> 2的用户 但这意味着我已将所有数据从redis复制到我的应用服务器以执行交叉,是否有更有效的方法来执行此操作,而不是通过网络传输所有匹配范围,而是在Rediss中进行交叉? 我想要的是 ZRANGEBYSCORESTORE在其中执行ZRANGEBYSCORE操作并将结果存
-
从spark集群向cassandra集群写入dataframe:分区和性能调优
我有两个集群-1。Cloudera Hadoop-Spark作业在这里运行2。云-卡桑德拉星团,多DC 在编写从spark作业到cassandra集群的dataframe时,我在编写之前在spark中进行了重新分区(repartioncount=10)。见下文: 在我的多租户spark集群中,对于一个有20M记录的spark批加载,以及以下配置,我看到了很多任务失败、资源抢占和动态失败。 PS:我
-
机器学习资料集 Datasets - Ex 3: The iris 鸢尾花资料集
机器学习资料集/ 范例三: The iris dataset http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html 这个范例目的是介绍机器学习范例资料集中的iris 鸢尾花资料集 (一)引入函式库及内建手写数字资料库 #这行是在ipython notebook的介面裏专用,如果在其他介面则可以拿掉
-
详解MongoDB中创建集合与删除集合的操作方法
本文向大家介绍详解MongoDB中创建集合与删除集合的操作方法,包括了详解MongoDB中创建集合与删除集合的操作方法的使用技巧和注意事项,需要的朋友参考一下 创建集合:createCollection() 方法 是用来创建集合. 语法: 基本的 createCollection() 命令语法如下: 在命令中, name 是要创建的集合的名称. Options 是一个文件,用于指定配置的集合 参
-
 Java 通过位运算求一个集合的所有子集方法
Java 通过位运算求一个集合的所有子集方法本文向大家介绍Java 通过位运算求一个集合的所有子集方法,包括了Java 通过位运算求一个集合的所有子集方法的使用技巧和注意事项,需要的朋友参考一下 Java没有自带的求一个集合的所有子集的方法,我们可以通过集合的子集规律来求。 一个集合的所有子集等于2^该集合的长度。比如{c,b,a}的长度为3,这个集合的子集就有8个。 这句话看起来很简单,但同时也隐含着高深的哲理。其实一个集合的所有集合,和
-
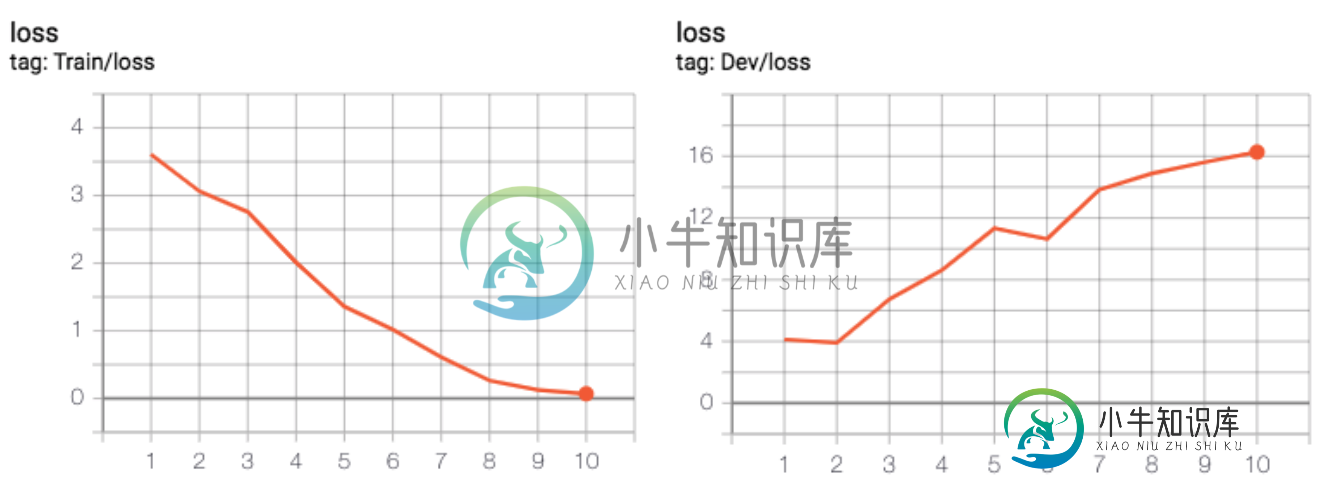 与训练集损失不同,开发集损失总是在增加
与训练集损失不同,开发集损失总是在增加我为文本分类问题设计了一个网络。为此,我使用huggingface transformet的BERT模型,上面有一个线性层进行微调。我的问题是训练集上的损失在减少,这很好,但是当涉及到在开发集上的每个时代之后进行评估时,损失会随着时代而增加。我正在发布我的代码来调查它是否有问题。 下面是训练器文件,我使用它对给定批次进行前向传递,然后相应地反向传播。 最后,以下是我的模型(即分类器)类: 为了可视
-
不一致js反应收集器未侦听收集器。在('collect')上
我正在尝试使用Discord制作一个带有AFK功能的Discord机器人。js。当用户发送消息时,它将检查他们是否是AFK,如果他们做出反应,则发送DM产品以关闭AFK。我正在尝试更新到v12。它在更新之前是有效的,现在它似乎拒绝倾听任何反应。它将对消息做出反应,但无论何时我做出反应,它都不会将其记录在控制台中。 它不会抛出错误,它将在设置反应收集器(我使用的控制台)后运行代码。登录,似乎一切正常
-
LiquiBase-TagDatabase变更集也使用标记更新以前的变更集
我想在changelog文件中使用以下变更集标记数据库,以便将来回滚。当我应用这个变更集时,我在databasechangelog中注意到,前面的变更集也用标记更新了。 changelog文件中的变更集 下面是从databasechangelog表中提取的内容,function51是上一次运行的变更集 有人遇到过吗?我使用的是Liquibase 3.1.1 多谢了。
-
如何决定应从列表集中使用哪个集合?[副本]
我想知道什么时候使用集合和列表。应在此基础上作出决定。例如,当我们处理订单应用程序时,我应该使用什么?列出任意=新阵列列表