《集度》专题
-
连接Redis集群与jedis
由于单个redis实例不符合我的要求,我选择了redis cluster。我用三个节点组成集群,并将数据填充到集群中。当我使用JedisCluster从集群获取数据时,它比单个实例花费更多的时间。那么,将绝地与redis星系团连接起来的正确方式是什么呢。我如何利用连接池将绝地与redis集群连接起来?
-
JpaRepository实现-列表与集
我正在使用JPA构建我的第一个Spring Boot应用程序,并像这样设置了我的数据存储库和服务: 然后是粗制滥造的服务 服务实现的抽象类 最后,一个扩展上述服务类的实际服务类示例: 我写了一些服务层逻辑和控制器,一旦我对第一次迭代感到满意,我就做了一些邮递员测试,这些测试工作顺利。
-
Sikuli与硒电网集成
我已经将Sikuli与Selenium Web驱动程序集成在一起,它在我的本地机器上运行良好。现在我想在远程机器中执行相同的脚本。我的脚本通常是基于sikuli的,即几乎没有任何Web自动化。整个项目是为了自动化在不同远程机器上运行的桌面应用程序。 想想零售商店上运行的POS系统。
-
Spring引导液基集成
尽管我提出了问题https://github.com/spring-projects/spring-boot/issues/662为了提供一个spring boot starter liquibase starter模块,今天我发现已经有了某种集成。 Spring Boot已经包含https://github . com/spring-projects/spring-boot/tree/maste
-
Jooq数组作为集合
我想在java中使用集合而不是数组来序列化postgreSQL数组。例如INT[]、varchar(256)[]到java集合和Collection。 SQL: 创建表array_tests(string_array varchar(256)[]); 我在生成的类中出错:
-
Hibernate 4与JPA的集成
环境:Spring 4,Hibernate 4,JPA 如果调用builderdao.delete(实体),我们会在线程“main”org.springframework.dao.invaliddataaccessapiusageException中得到异常:只读模式(flushmode.manual)中不允许写操作:将会话转换为flushmode.commit/auto或从事务定义中删除“rea
-
Cassandra部署群集失败
命令在rest两个节点上运行,一切正常。当我想跑的时候 nodetool状态 命令时,我得到了这个错误消息
-
比较对象数组集
如果两个集合包含相同的对象,如何进行比较? 当然会打印错误。
-
Rest API的集成测试
我希望获得关于如何为Rest API创建集成测试的不同观点。
-
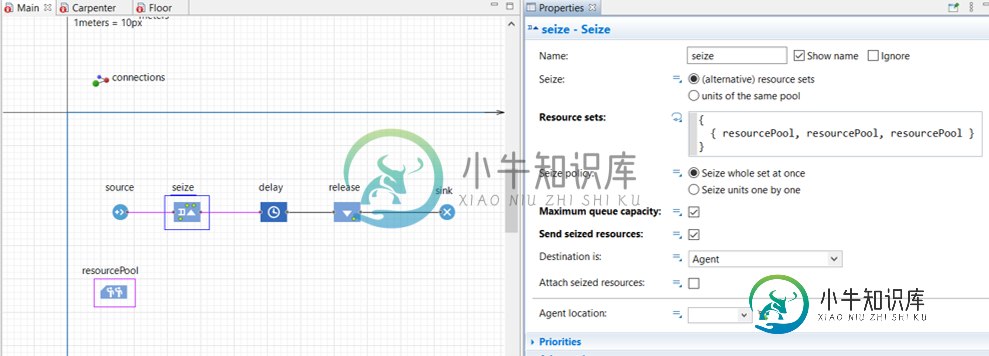 动态资源集分配
动态资源集分配我试图动态地获取给定数量的资源,但我无法理解语法。在资源集动态分配中,每个单元由其所属的资源集的名称表示。在图中,查封块将查封集合“resourcePool”中的3个资源。 我需要为每一个特工抓取特定数量的资源。然后我尝试创建资源池对象的ArrayList,并将其传递到动态分配中,但由于类型不匹配,因此无法工作。 例如,假设我有一个需要4个资源的代理,所以需要的表达式是:{resourcePool
-
集成Spring Security OAuth2和Spring
我正在使用一个Spring Boot+Spring Security OAuth2应用程序,我相信它的灵感来自Dave Syer的示例。应用程序被配置为OAuth2授权服务器,具有使用资源所有者密码凭据流的单个公共客户端。成功的令牌被配置为JWT。 公共Angular客户机向/oauth/token发送一个POST请求,该请求带有包含客户机id和秘密的基本身份验证头(这是让客户机进行身份验证的最简
-
Spring Boot+集成测试+Oauth2
与Oauth2和spring Security集成测试有问题...在将Oauth2配置添加到代码库之前,集成测试工作正常 设置: 具有受保护数据的客户端服务器还包含权限列表,使用Spring Security和OAuth2 提供访问令牌和执行身份验证的身份验证服务器 工作流: null Oauth2配置: 自定义安全逻辑: 还有一个:
-
 德胧集团Java面试
德胧集团Java面试没咋问Java的八股主要问项目相关的八股,简单记一下面经。 MySQL隔离级别,以及对应解决的问题 MySQl如何解决幻读 MySQL 索引的实现 Redis底层数据结构 跳表数据结构 Aop怎么实现,结合项目怎么使用 算法:二叉树公共祖先(要自己建树写测试用例) 有朋友了解这家公司吗?可以去么
-
第二章 集腋成裘
我们准备从小处着手,因此本章介绍 Perl 的元素。 因为我们准备从小处开始,所以我们在随后几章里将逐步从小到大。也就是说,我们将发起一次从零 开始的长征,从 Perl 程序里最小的构件开始,逐步把它们更精细的组件,就象分子是由原子组成的 那样。这样做的缺点是你在卷入细节的洪流之前没有获得必要的全景蓝图。这样做的好处是你能随 着我们的进展理解我们的例子。(当然,如果你是那种从宏观到微观的人,你完全
-
Hadoop 集成 - spark streaming交互
Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下: wget http://d3kbcqa49mib13.clo