《集度》专题
-
MySQL群集复制配置
我正在尝试在两个MySQL集群之间使用单个复制通道设置复制。我已经看了mysql.com的文档几次了,但似乎不能让它正常工作。 我遇到的问题是,对未配置为主服务器的SQL节点进行的查询不会复制NDBCLUSTER表的任何INSERT、UPDATE或DELETE查询,然而,当我在作为主服务器的SQL节点上插入、更新或删除一行时,它会很好地复制到其他集群。 我知道复制是设置的,因为如果我在主集群中的任
-
 Mandelbrot集缩放和平移
Mandelbrot集缩放和平移我在Java中编码了一个Mandelbrot集分形,并包含了平移和放大分形的能力。唯一的问题是,当我平移图像并试图放大时,它看起来好像试图放大中心并平移一点。平移和缩放不是真正的平移或缩放,而是对分形的重新计算,看起来像是平移或缩放。 这是我的代码。 我能告诉用户在哪里可以让相机更精确地缩放吗? 先谢谢你。 编辑:图片对于任何想知道这个程序将呈现什么。
-
 Matlab中Mandelbrot集的着色
Matlab中Mandelbrot集的着色我制作了一个程序来计算mandelbrot集合中的点。对于不属于mandelbrot集的点,我会记录起点发散到震级大于2的地方所需的迭代次数。基本上,对于mandelbrot集合之外的每一点,我都有一个计数器,可以显示它在1到256的范围内发散的速度。我想做的是根据每个点发散的速度给它一个颜色。例如,在255次迭代中发散的点可能是白色的,发散越快,着色越多。我已经做了一个简单的调整,在20步以上的
-
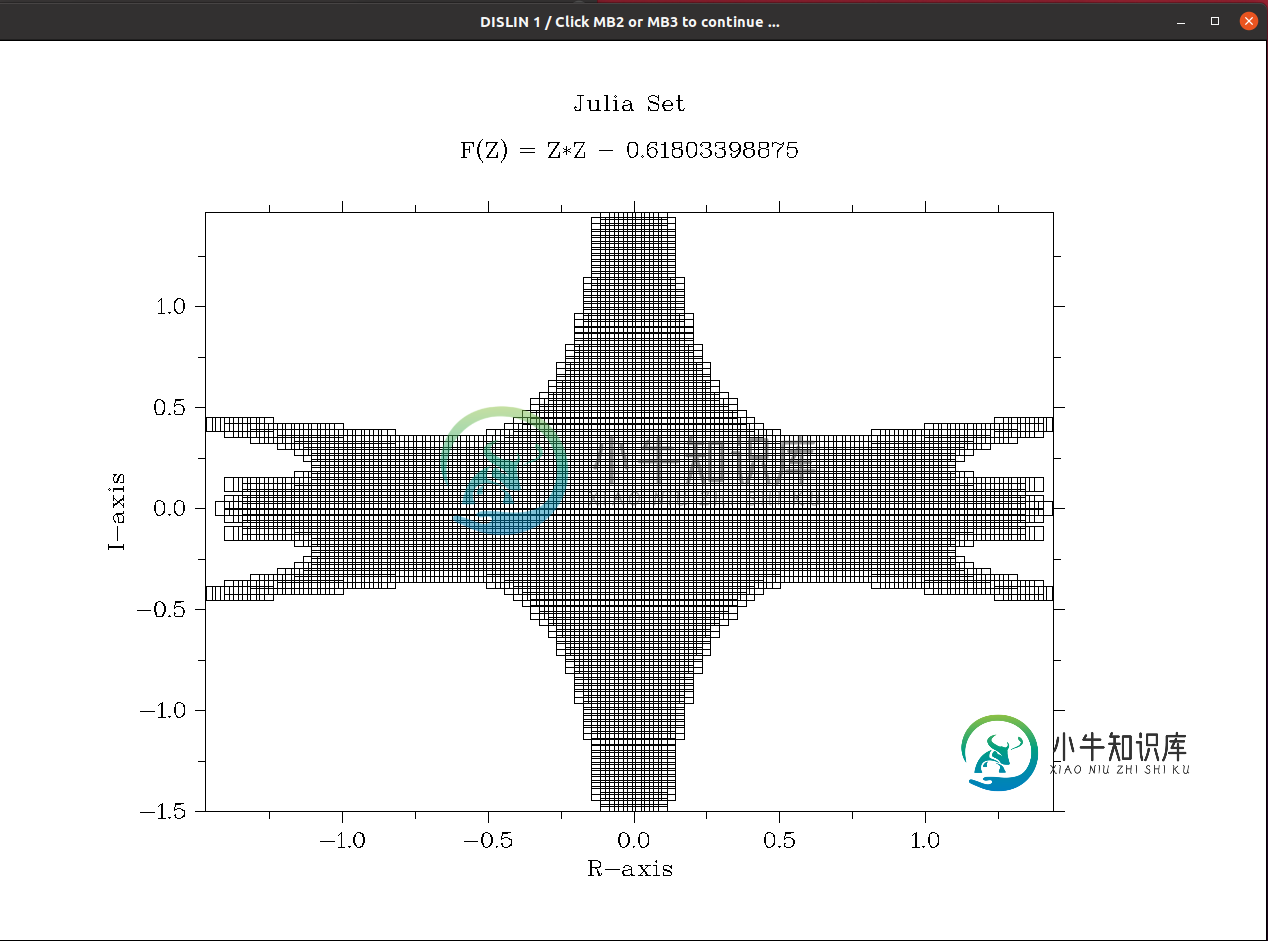 用C(DISLIN)生成Mandlebrot集
用C(DISLIN)生成Mandlebrot集我试图用c生成mandlebrot集,但我得到了一些不正确的输出 . . . 这个代码有什么问题? 这是输出 它只与这里的结果具有对称性: https://en.wikipedia.org/wiki/Julia_set#/media/File:Time_escape_Julia_set_from_coordinate_(phi-2,_0). jpg 能得到一些想法会很棒 K
-
 Mandelbrot集合中的形状
Mandelbrot集合中的形状迷人可爱的Mandelbrot集箍和卷曲是浮点计算不准确的结果吗? 我编写了各种Mandelbrot集实现,例如动态缩放和回放。一些使用定点算法,另一些使用FPU。 我见过这个问题,它表明每一个芽都是数学上光滑的形状,周围有较小的芽。 海马形状等的游行是计算机浮点运算局限性的副作用,而不是实际的曼德布罗特集吗? 海马?由Spektre添加: 我一直想说的是,浮点运算,无论是定点运算还是固定意义运算
-
如何集成rsyslog、AWS ELB
我一直使用php脚本将日志写入rsyslog,然后rsyslog在tcp端口上直接向flume(syslogtcp源)发送消息。 现在,当我迁移到AWS时,我想在rsyslog之间引入一个ELB(弹性负载均衡器)层 这方面的任何帮助都将是巨大的。
-
WebSphere MQ与水槽集成
我正在尝试将 Websphere (IBM) MQ 与 flume 集成。我有几个来自MQ的xml文件 我正在AWS EC2实例上进行此集成,其中也安装了我的Hadoop。以下是我遵循的集成步骤。 创建队列管理器:https://www.ibm.com/support/knowledgecenter/SSFKSJ_7.5.0/com.ibm.mq.con.doc/q015210_.htm ./cr
-
火花流集成水槽
我遵循火花流水槽集成的指导。但我最终无法获得任何事件。(https://spark.apache.org/docs/latest/streaming-flume-integration.html)谁能帮我分析一下?在烟雾中,我创建了“avro_flume.conf”的文件,如下所示: 在文件中,123.57.54.113是本地主机的ip。 最后,根本没有任何事件。 怎么了?谢谢!
-
SIMD指令集有宏吗?
有没有我们可以用来进行指令集检测的宏? 我知道我们有运行时程序: 但我们是否已经定义了这方面的符号,例如。 如果没有,我们可以创建一个或我们有一个解决办法吗? 在玩反编译器的时候,我发现了一个奇怪的“递归”。但我想ILSpy漏了。 此外,当我查看一个简单的代码时,我注意到以下内容: ASM 正如您所看到的,它不知怎么弄明白了Avx是受支持的,并且不包括分支。这是正常和明确的行为吗?
-
Dropwizard与Testcontainers集成测试
我正在尝试对停靠数据库运行DropWizard的集成测试。 DropWizard 测试容器 我试过的: 我得到由:java.lang.IllegalStateException引起的 将这些链接在一起也不起作用 最后,这是可行的,但据我所知,它在每次测试中都运行新的DropwizardAppRule,这是不好的... 那么,如何将规则链接起来,使PostgreSQLContainer首先启动,并且
-
哈希集和多线程
我在Java 7号工作。 我想知道方法在HashSet对象上是否是线程安全的。 散列集由一个线程初始化。然后我们用不可修改的集合()包装HashSet。初始化后,多个线程只调用方法。 当我阅读Javadoc时,它对我来说是不清楚的。 在HashSet Javadoc上,我们可以阅读 这个类实现Set接口,由一个哈希表(实际上是一个HashMap实例)支持。 ... 请注意,此实现不是同步的。 在H
-
也许是持续集成?
我有一个渴望的需求,但我不完全知道去哪里找。 我使用 BitBucket.org 进行网站的私人开发,我想做的预期效果是这样的: < li >我专门从事功能/和bug/分支工作 < li >每当我将代码拉入我的主机(通过拉请求)时,我都希望有东西触发: < li >我希望将主分支的内容上传到服务器(可能通过FTP?)自动(更好的是:只显示发生的更改) 这是像詹金斯这样的技术可以做的事情吗?(我对C
-
MySQL、c3p0和Apache Felix集成
我将MySQL集成到Apache Felix中。首先,我使用bndtools生成MySQL捆绑包和c3p0捆绑包。然后将它们全部添加到Apache Felix环境中。我为连接池创建了一个类,如下所示: 如果我运行JUnit测试,它工作得很好。但在Apache Felix包上运行时失败,并出现异常消息。Activator类中的用法: 错误消息: 如果我只使用(不使用c3p0),MySQL可以工作:
-
Flink-多源集成测试
我有一个Flink作业,我正在使用这里描述的方法进行集成测试:https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/testing.html#integration-testing 作业从两个源获取输入,这两个源组合在一个中。在测试环境中,我目前使用两个简单的SourceFunction来发出值,但是这不提供对事件发出顺
-
Logstash-Kafka集成不工作
我们希望使用logstash获取日志并将其传递给Kafka。 我们已经为logstash1.5.0beta1和kafka 2.9.2_0.8.1.1编写了以下conf文件 ** ** 运行以下命令后:bin/logstash代理-ftest.conf--logex.log test.conf是我们的conf文件。ex.log是我们为要存储的日志创建的空白文件。 我们得到以下输出 发送logstas