《普通二本》专题
-
 cider二面
cider二面1.看了concurrenthashmap的源码对你有哪些并发编程的帮助呢? 2.java中有哪些锁? 3.乐观锁和悲观锁的区别? 4.如果用mysql来写sql,那这两把锁应该怎么实现? 5.模拟一下mysql的rr场景下的死锁? 6.场景:如果线程1修改某张表中的第一条数据以后还没有提交事务,线程2也想修改同样一张表的第一条数据会发生什么情况? 7.行锁什么时候释放? 8.当前读和快照读有什么
-
通过AJAX发布将文件输入作为FileReader二进制数据发布
问题内容: 我正在尝试将附件上传到通过rest API输入到网页的HTML文件中。API文档指出,该帖子是HTTP请求正文的纯二进制内容,而不是表单文件上载。 我的代码如下: 我需要使用它来处理许多不同的mimeType,因此我没有在上面的代码中声明它。但是,我尝试为.doc文件声明contentType:’application / msword’,还尝试了processData:false和c
-
设置chrome浏览器二进制通过在Python中的chrome驱动程序
我将Selenium与Python Chrome webdriver一起使用。在我的代码中,我使用了: 将webdriver指向webdriver可执行文件。有没有办法将webdriver指向Chrome浏览器二进制文件? https://sites.google.com/a/chromium.org/chromedriver/capabilities他们有以下产品(我想这就是我要找的): 有人举
-
本地通知ANE
AIR Native Extension:实现本地按时通知、声音设置和通知内容。 [Code4App.com]
-
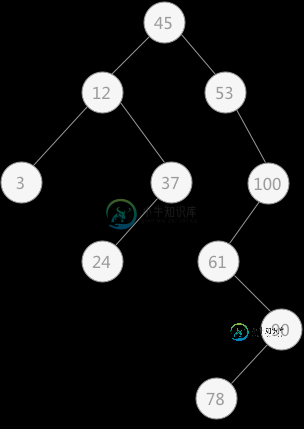 二叉排序树(二叉查找树)
二叉排序树(二叉查找树)主要内容:什么是二叉排序树?,使用二叉排序树查找关键字,二叉排序树中插入关键字,二叉排序树中删除关键字,总结前几节介绍的都是有关静态 查找表的相关知识,从本节开始介绍另外一种查找表—— 动态查找表。 动态查找表中做查找操作时,若查找成功可以对其进行删除;如果查找失败,即表中无该关键字,可以将该关键字插入到表中。 动态查找表的表示方式有多种,本节介绍一种使用树结构表示动态查找表的实现方法—— 二叉排序树(又称为 “二叉查找树”)。 什么是二叉排序树? 二叉排序树要么是空 二叉树,要么具有如下特点:
-
工程规约 - (二) 二方库规约
1.【强制】定义GAV遵从以下规则: GroupID格式:com.{公司/BU }.业务线.[子业务线],最多4级。 说明:{公司/BU}例如:alibaba/taobao/tmall/aliexpress等BU一级;子业务线可选。 正例:com.taobao.jstorm或 com.alibaba.dubbo.register ArtifactID格式:产品线名-模块名。语义不重复不遗漏,先
-
二维二次贝塞尔曲线(QuadraticBezierCurve)
创建一条平滑的二维 二次贝塞尔曲线, 由起点、终点和一个控制点所定义。 代码示例 const curve = new THREE.QuadraticBezierCurve( new THREE.Vector2( -10, 0 ), new THREE.Vector2( 20, 15 ), new THREE.Vector2( 10, 0 ) ); const points = curv
-
第二十四课 阴影贴图(二)
在前面一节中我们学习了 shadow mapping 的基本原理,并且介绍了如何将深度信息渲染到一张纹理上面并最终通过从深度缓存中进行采样而将其渲染到屏幕上面。在这一节中我们将会介绍如何使用这个功能来创建真正的阴影。 我们知道 shadow mapping 是一个二次渲染技术,在第一次渲染过程中场景的渲染是从光源角度出发的。让我们回顾一下在第一次渲染时位置向量的 Z 分量的发生了什么: 传入顶点着
-
java 数据的加密与解密普遍实例代码
本文向大家介绍java 数据的加密与解密普遍实例代码,包括了java 数据的加密与解密普遍实例代码的使用技巧和注意事项,需要的朋友参考一下 这是一个关于密钥查询的jsp文件,接受上级文件的数据并加密处理,放入Map集合中,通过form表单提交到xdoc文件中;不过这种做法是为了满足公司的要求,用到了框架的内容不免显得繁琐;下篇文章会介绍一种简便的不需要搭建太多环境的普遍做法。 希望本篇文章实例
-
Maven for Eclipse1.5。无法在开普勒下安装0插件
我下载了EclipseKepler,并试图从其更新站点安装M2Eclipse。 在选择Maven Integration for Eclipse后,我单击Next并得到以下错误: 缺少需求:针对Eclipse1.5的Maven集成。0.20140606-0033(org.eclipse.m2e.core 1.5.0.20140606-0033)需要“bundle com”。谷歌。番石榴[14.0.
-
OAuth2 JWT授权-Spring SecurityXML配置问题#OAuth2。哈斯考普
我需要将XML配置用于我的Spring Security实现的某些部分。目前我所关心的只是JWT授权,JWT被传递给我。使用Spring Security我确定用户是否被授权访问REST APIendpoint。我不能使用Java配置或@PreAuthorize注释。 仅供参考,当我最初使用@PreAuthorize或类似的方法时:. antMatcher("/学生/**"). access("#
-
 用爱普生热敏打印机C#打印长收据
用爱普生热敏打印机C#打印长收据我有一台爱普生热敏打印机,现在我要打印一些足够长的收据,我使用爱普生提供的代码样本。代码如下所示,现在的问题是,当收据超过一定长度(约30cm)时,打印机会停止并剪切收据,如下图所示。我如何打印长收据没有自动剪切。
-
SCDF指标收集器-包括普罗米修斯指标
我正在使用带Spring靴2的SCDF。x metrics和SCDF metrics collector从我的Spring Boot应用程序收集指标。我真的不理解收集器关于聚合度量(aggregateMetrics)数据的逻辑。 当我获取为我的流收集的指标列表时,我只有以开头的指标,因此我只有平均值。我尝试了所有方法来查看其他指标,就像endpoint公开的指标一样。 我想我误解了指标的聚合方式。
-
爱普生打印机连接失败状态ERR\U CONN
我有一台爱普生打印机,我使用SDK提供的epos2_printer(示例项目)代码与我的应用程序集成。我复制了相同的代码,但似乎从来没有工作过! 然而,当我将示例项目连接到打印机时,同样的情况也会发生。 mPrinter.add馈线(2); 它总是给我例外ERR\u连接打印机。连接内部连接打印机功能。 我做错了什么? 此代码适用于示例应用程序。附注:我已尝试在连接示例应用程序之前连接此应用程序,以
-
当我们不在马普减中使用组合器时?
每个Hadoop开发者都知道合并器是优化mapreduce的关键,但它是可选的。它可以最小化带宽并提高mapreduce作业性能。在这里,我的问题是,hadoop在默认情况下提供了许多功能,如数据局部性问题,但没有将组合器作为默认值。为什么?这意味着在所有情况下合并器都是不可取的?当我们不使用合成器时。如果我将它设为默认值,会有什么问题呢?