《北森》专题
-
如何使用Lucene ShingleFilter:找不到组织的实现类。阿帕奇。卢森。分析标记属性。抵销属性
代码如下:github链接 错误是: ren:null位于[]:java。lang.IllegalArgumentException:找不到组织的实现类。阿帕奇。卢森。分析标记属性。组织中的偏移属性。阿帕奇。猪后端。hadoop。执行引擎。物理层。物理操作员。getNext(PhysicalOperator.java:338) 在org。阿帕奇。猪后端。hadoop。执行引擎。物理层。关系运算符。
-
卢森。net GetFieldQuery与TermQuery
使用Lucene的标准分析仪。有问题的标题字段未存储、已分析。查询如下: 在Luke中,此查询被正确地重新编写为: 我以为Lucene.net版本是: 但是,没有返回任何结果。 然后我试着: 这一切都如期而至! 这两个查询都是通过:_searcher执行的。搜索([查询对象],[排序对象]) 有人能给我指出正确的方向,看看TermQuery和_解析器之间的区别吗。GetFieldQuery()是什
-
卢森。网络新手查询问题
第一次使用Lucene,所以如果某些术语不正确,我会提前道歉。 我正在修改一个查询,没有得到预期的结果。搜索词用于构建布尔查询,我需要添加一个额外的字段进行搜索。这个名为的字段已经是索引的一部分(通过Lucene的确认),但尚未包含在搜索中。 当前布尔查询如下所示: (是引用字段名称的) 我认为这将是一个扩展标记数组的例子,如下所示: 但是当搜索我知道存在的时,这买回了没有结果,但是我知道存在的的
-
卢森。Net 3.0。3使用词干搜索或搜索最佳匹配
试图让搜索按我需要的方式进行。。。目前,我使用StandardAnalyzer()将数据分析到索引中,然后使用QueryParser()和Query()并执行。。。如果文档中有“可疑”一词,搜索“可疑”,我会在其中找到我的文档,但如果搜索“可疑”,我不会得到任何结果。。。所以我的问题是,我想对我的搜索实现词干分析或更好的查询。。。我知道你会得到SnowBallaAnalyzer用于堵塞,但它在Lu
-
卢森。NET 2.9-多字段QueryParser、增强字段、词干和前缀
我有一个系统,其中搜索查询具有不同boost值的多个字段。它在Lucene上运行。净额2.9。4因为这是一个Umbraco(6.x)网站,这就是Lucene的版本。NET的CMS使用。 我的客户问我是否可以添加词干分析,所以我编写了一个自定义分析器,可以执行标准/小写/停止/PorterStemmer。堵塞过滤器似乎工作正常。 但是现在,当我试图将我的新分析器与MultiFieldQueryPar
-
如何在GridSearchCV(随机森林分类器Scikit)上获得最佳估计器
问题内容: 我正在运行GridSearch CV以优化scikit中分类器的参数。完成后,我想知道哪些参数被选为最佳。 每当这样做时,我都会得到一个,并且无法说出原因,因为它似乎是文档上的合法属性。 产量: 问题答案: 您必须先对数据进行拟合,才能获得最佳的参数组合。
-
通用域名格式。谷歌。格森。流动格式错误的JSON异常
我正在尝试使用改装将图像上载到本地服务器。下面是我的php代码。 但是我得到了这样一个错误:com.google.gson.stream.MalformedJsonException使用JsonReader.setLenient(true)在第1行第1列路径$处接受格式错误的JSON。 然后,我在初始化改装的类中添加了以下代码。 现在我得到以下错误:com.google.gson.JsonSynt
-
随机森林的动态响应变量
我正在尝试创建一个动态ML应用程序,允许用户上传一个数据集,以使用随机林模型预测数据集中的第一列。 我在使用randomforest()函数时遇到了问题,特别是当我试图将响应变量指定为数据集的第一列时。对于下面的示例,我使用iris数据集,并将响应变量Species移动到第一列中。 这是我的尝试: 然而,这不起作用。我得到的错误是: 错误:可变长度不同(针对“物种”找到) 只有当我像这样手动指定响
-
R-随机森林没有正确加载
我在加载随机森林模型并将其应用于带有的栅格时遇到问题。 通常,当我在R会话中创建随机森林模型时,键入其名称并点击回车,我会收到以下打印输出: 当我使用predict将此会话内模型应用于光栅时,我可以进行成功的预测。 当我改为使用readRDS加载保存的随机林模型并键入模型名称时,如下所示: 我收到rf_model中所有信息的完整打印件(即rf_model$call,rf_model$type...
-
独立栅格层中的随机森林类概率
我正在使用randomForest包对不同预测值的光栅堆栈进行分类。分类工作正常,但我还想检索类概率。对于我的代码,我只得到一个具有第一个类概率的RasterLayer,但我希望得到一个具有一个层中每个类的类概率的RasterStack。
-
具有随机森林的图像分类(光栅堆栈)(package ranger)
我正在使用R软件包ranger对随机森林进行拟合,以对光栅图像进行分类。预测函数会产生错误,下面我将提供一个可重复的示例。 给出的错误是 v[单元格,]中的错误 虽然我真实数据的错误是 p[-naind,]中有错误 我唯一想到的是,除了感兴趣的预测之外,ranger.prediction对象还包括几个元素。无论如何,游侠如何被用来预测栅格堆栈?
-
随机森林变量选择
我有一个随机森林,目前建立在100个不同的变量之上。我希望能够只选择“最重要”的变量来构建我的随机森林,以尝试提高性能,但我不知道从哪里开始,除了从rf$重要性中获得重要性。 我的数据只是由数字变量组成,这些变量都经过了缩放。 以下是我的射频代码:
-
可变和随机森林的等级
考虑一个数据集训练: 二元结果变量z和三个水平的分类预测因子a:1、2、3。 现在考虑一个数据集测试: 当我运行以下代码时: 我收到以下错误消息: 我假设这是因为测试数据集中的变量a没有三个级别。我该如何解决这个问题?
-
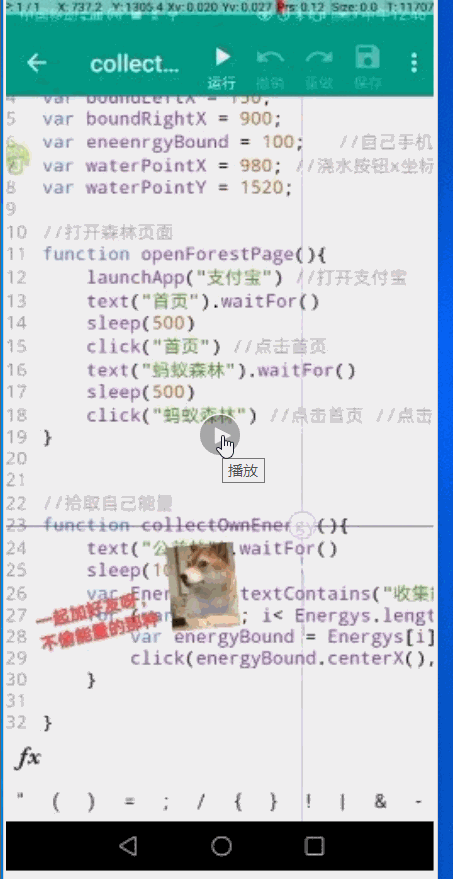 autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法
autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法本文向大家介绍autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法,包括了autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法的使用技巧和注意事项,需要的朋友参考一下 1、简介 定时 实现对蚂蚁森林能量的自动拾取,以及帮指定好友浇水 2、开发环境搭建 语言: javaScript 开发工具:vcCode. auto.js 1)、手机安装 auto.js 我们编写的脚本就是在这个上面
-
R:以栅格为响应和解释变量的随机森林
我想用随机森林方法创建火灾发生概率图。我的响应变量是一个光栅,其中包含每个网格单元的年平均燃烧面积。我的解释变量是多个光栅(温度、海拔、土地利用和人口密度)。是否可以使用光栅作为响应变量,以及基本代码线的外观如何?我找不到这方面的任何信息。 到目前为止,我的代码也是如此,但我得到了一个错误:as中的错误。数据框架默认值(数据):无法将“结构(“RasterStack”,package=“raste