《北森》专题
-
R语言随机森林
主要内容:安装R包 - randomForest,语法,示例在随机森林方法中,创建了大量的决策树。每个观察结果都被送入每个决策树。 每个观察结果最常用作最终输出。对所有决策树进行新的观察,并对每个分类模型进行多数投票。 对于在构建树时未使用的情况进行错误估计。 这被称为OOB(Out-of-bag)错误估计,以百分比表示。 R中的软件包用于创建随机林。 安装R包 - randomForest 在R控制台中使用以下命令安装软件包,还必须安装其它依赖软件包(如
-
集成学习应用:随机森林算法
主要内容:决策树和随机森林,算法应用及其实现,总结随机森林(Random Forest,简称RF)是通过集成学习的思想将多棵树集成的一种算法,它的基本单位是决策树模型,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。我们知道,集成学习的实现方法主要分为两大类,即 Bagging 和 boosting 算法,随机森林就是通过【Bagging 算法+决策树算法】实现的。前面已经学习过决策树算法,因此随机森林算法
-
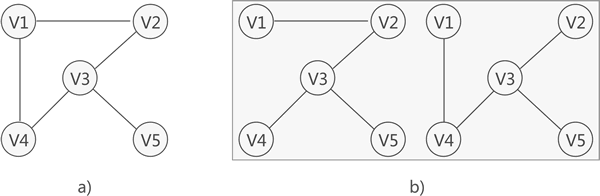 什么是生成树(生成森林)
什么是生成树(生成森林)主要内容:生成森林在学习 连通图的基础上,本节学习什么是 生成树,以及什么是 生成森林。 对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为 生成树 。 图 1 连通图及其对应的生成树 如图 1 所示,图 1a) 是一张连通图,图 1b) 是其对应的 2 种生成树。 连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。 连通图中
-
格森。toJson给出StackOverFlowError,在这种情况下如何获得正确的json?(公共静态类)
我目前有以下课程: 我想用它来创建json。为此,我使用了以下代码: 当我这样做的时候,我得到一个java.lang.StackOverFlowError: 所以,我的问题是:如何让我的 gson 从类 TabInfo 创建 java 对象的有效 json,而不会收到堆栈溢出错误? 顺便说一句。正如你们所看到的,我以前没有问过那么多问题,所以如果你对如何改进我的问题有任何反馈,请告诉我! 编辑1:
-
凯尔·辛普森的OLOO模式与原型设计模式
Kyle Simpson的“OLOO(链接到其他对象的对象)模式”与原型设计模式有什么不同吗?除了通过专门指示“链接”(原型的行为)并澄清这里没有“复制”发生(类的行为)来创造它之外,他的模式究竟引入了什么? 这是凯尔的模式的一个例子,来自他的书《你不知道JS:这个》
-
 元气森林-日常后端开发-一面
元气森林-日常后端开发-一面元气森林-日常后端开发-一面40mins (第一部分:自我介绍,基本情况了解) 自我介绍 会哪些语言?(java)还会别的吗?(python会一点)Go有了解吗? 项目相关(大致业务,简单问了技术栈使用相关情况,此处无八股,用springcloud做过微服务,有没有做过一体的?RPC有没有自己实现过?) (第二部分:八股文提问) (计算机网络) 情景题:比如我们当前在视频,运用计网知识介绍一下流程
-
 图森前端实习一面
图森前端实习一面面试题 自我介绍✅ 项目介绍,两个项目都介绍了一遍✅ 项目拖拽怎么实现的?✅ 讲解群聊和私聊怎么实现的?✅ 讲讲 Websocket?✅ Websock 为什么是长连接的?✅ 说说心跳续约是什么✅ 心跳续约的原理?❌ 怎么判断对方在不在线?❌ 哪一方判断?客户端还是浏览器?❌ 场景题:如果自己不用事件监听实现滚动条自动更新到最新位置,应该怎么做?❌ 说说 rem 与 em 的区别?✅ 有没有根据不
-
 图森未来 10月17日 测试开发工程师 一面 56min
图森未来 10月17日 测试开发工程师 一面 56min自我介绍 C语言和C++的区别 C++里面如何使用C语言? 编译器如何编译C语言和C++语言? extern "C" vector的底层实现及常用函数 vector是线程安全的吗? malloc和new的区别和联系,内存在哪个区? 栈区一般存储什么? 如何减少栈内存的使用?(引用传值,避免深层拷贝的发生) 内联函数是在编译的哪个阶段?有类型的检查,安全的 map存储函数(如何存储?函数指针:地址)
-
 图森未来 10月18日 测试开发工程师 二面 45min
图森未来 10月18日 测试开发工程师 二面 45min自我介绍 为什么选择测开? 研发和测开的岗位区别? 为什么测开的技术要求更高? 对测开的理解 为什么适合测开 未来的规划 测试流程(W模型) 编码之前的局部测试(需求设计,概要设计,接口测试,可行性测试,必要性测试) 编码之前的局部测试和单元测试的区别 接口测试的注意点 if-else系统调用异常值捕获测试(将系统调用使用其他的函数代替,避免系统调用的发生) 登录和未登录状态的fun功能测试 如何
-
组合树 - 随机森林
1 Bagging Bagging采用自助采样法(bootstrap sampling)采样数据。给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时,样本仍可能被选中, 这样,经过m次随机采样操作,我们得到包含m个样本的采样集。 按照此方式,我们可以采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基本学习器,再将这些基本学习
-
结合scikit学习中的随机森林模型
问题内容: 我有两个RandomForestClassifier模型,我想将它们组合成一个元模型。他们都使用相似但不同的数据进行了训练。我怎样才能做到这一点? 我想将所有树木合并成一个500棵树模型 问题答案: 我相信可以通过修改RandomForestClassifier对象的和属性来实现。森林中的每棵树都存储为DecisionTreeClassifier对象,这些树的列表存储在属性中。为了确保
-
C#基于基姆拉尔森算法计算指定日期是星期几的方法
本文向大家介绍C#基于基姆拉尔森算法计算指定日期是星期几的方法,包括了C#基于基姆拉尔森算法计算指定日期是星期几的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#基于基姆拉尔森算法计算指定日期是星期几的方法。分享给大家供大家参考。具体分析如下: 基姆拉尔森计算公式 W= (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400) mod 7 在公式中d表示日期中的日数,
-
Python实现的寻找前5个默尼森数算法示例
本文向大家介绍Python实现的寻找前5个默尼森数算法示例,包括了Python实现的寻找前5个默尼森数算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的寻找前5个默尼森数算法。分享给大家供大家参考,具体如下: 找前5个默尼森数。 若P是素数且M也是素数,并且满足等式M=2**P-1,则称M为默尼森数。例如,P=5,M=2**P-1=31,5和31都是素数,因此31是
-
 python实现H2O中的随机森林算法介绍及其项目实战
python实现H2O中的随机森林算法介绍及其项目实战本文向大家介绍python实现H2O中的随机森林算法介绍及其项目实战,包括了python实现H2O中的随机森林算法介绍及其项目实战的使用技巧和注意事项,需要的朋友参考一下 H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator H2ORandomFore
-
sklearn随机森林可以直接处理分类特征吗?
问题内容: 说我有一个分类特征,颜色,它取值 [‘红色’,’蓝色’,’绿色’,’橙色’], 我想用它来预测随机森林中的事物。如果我对它进行一次热编码(即,将其更改为四个伪变量),如何告诉sklearn四个伪变量实际上是一个变量?具体来说,当sklearn随机选择要在不同节点上使用的功能时,它要么应该同时包括红色,蓝色,绿色和橙色的虚拟对象,要么不应该包含其中任何一个。 我听说没有办法做到这一点,但