《求职交流聚集地》专题
-
Spring集成阻塞轮询器,异步下游,流完成信号
我正在尝试配置一个轮询器,该轮询器每X秒查询一个bean,以将列表放入一个通道。该通道有一个下游流,该流将列表拆分并输出到发布/子通道(进一步的异步流)。我如何确保在任何给定的时间,只有在流执行过程中,轮询器必须等待/阻止流完成,直到为下一次轮询做好准备(固定速率/延迟)? ...在上进一步异步流以发送出站消息 有没有使用异步切换的阻塞轮询器示例,以及使用barrier向轮询器线程发送完成流信号的
-
MySQL Connector/J在“流式传输”结果集时是否缓冲行?
根据我的阅读,我认为使用MySQL JDBC驱动程序在MySQL中流式传输< code>ResultSet的方法是这两个命令: 我的问题是,专家能否澄清使用上述代码流式传输ResultSet是否会将一行返回给客户端,然后去服务器获取下一行,依此类推(效率非常低),或者它是否足够智能,可以像一样进行缓冲流式传输?如果它进行缓冲流式传输,如何设置缓冲区大小? 编辑:来自文档: 前向只读结果集与整数获取
-
集群环境下的Spring Integration流式入站信道适配器
我需要在多/集群环境中实现sftp流入站通道适配器。我不应该将文件存储在我的本地目录中,我已经流文件并立即处理它。它在单个实例中工作得很好,但是如果我试图在多个节点中运行poller,就会遇到类似重复处理的问题,第二个节点找不到文件。 我尝试使用propertiesmetadatastore按照https://docs.spring.io/spring-integration/reference/
-
如何动态定义流数据集的模式以写入CSV?
我有一个流数据集,阅读Kafka并试图写到CSV 有没有一种方法可以通过编程模式和结构化流数据集来实现这一点?
-
如何将每个输入流的数据集合并为一个
-
如何在Spring与Java DSL集成流中更改默认通道
我不是很理解,因为我可以更改所有集成流的错误通道。我需要处理像InvalidAccessTokenException这样的异常,它们可以在路由器内部的子流中抛出。 我所尝试的是通过以下方式处理来自默认通道“ErrorChannel”的异常: 此错误由具有以下签名的方法处理: 集成流的配置我解释如下: 可以在任何社交网络服务中启动的异常示例如下: 是否可能将此异常绑定到特定的错误通道?。 以下是日志
-
为集合中有其他类似元素的元素筛选流
我有这个代码: 它的工作是让我获得myObject集合中不止一次出现的对象。 我需要修改这段代码,使它给我的对象不仅在等式上匹配,而且在属性子集上匹配。 因此,如果具有属性,和。我希望过滤器给我满足以下条件的对象:和,还有另一个元素具有相同的值。
-
测试张量流集线器安装:通用句子编码器
我想从这里尝试通用句子编码器链接。 这是我在Ubuntu 18.04和Jupyter笔记本上运行的代码 它一直在运行,什么也没发生。它在下载什么东西吗?我已经等了很长时间了。除了以下内容,它什么也没显示: 我检查了我的tensorflow装置。看起来很好。有什么故障排除建议吗?
-
收集器的合并器功能可以用于顺序流吗?
示例程序: 所以,为了简化这里的问题,没有最终的转换,所以得到的代码非常简单。
-
邮递员-在集合预请求脚本运行之前为单个请求设置变量
我想做一个邮递员集合请求击中相同的APIendpoint作为不同的用户。例如: 登录“user_1” 设置数据 登录“user_2” 获取数据并检查是否正确
-
SELECT查询是否总是以相同顺序返回行?具有聚集索引的表
问题内容: 我的查询是否总是以相同的顺序返回数据库表中的行? 我的表的一列上有一个“聚集索引”。这会改变答案吗? 问题答案: 返回的行的顺序将 不会 总是相同的,除非你明确地与状态,这样的条款。所以不行。 和不; 仅仅因为您的1000个查询返回的顺序相同,所以 不能 保证第1001个查询的顺序相同。
-
默认情况下,SQL Server是否在表的所有列上创建非聚集索引
问题内容: sql server将创建任何默认的非聚集索引吗?我们真的应该将所有FK都作为非聚集索引吗?这里的权衡是什么 问题答案: 否,SQL Server不会自动创建非聚集索引。 除非您的声明另有说明,否则将基于主键自动创建聚簇索引。 是的,我会建议索引外键列,因为这些是最容易被JOIN’d /搜索不要使用,等等。但是,要知道,在低基数的设定值(性别为例)的指标会比较没有用,因为值之间没有足够
-
将POST请求中的数据流存储在GridFS,Express,mongoDB,node.js中
问题内容: 我试图弄清楚如何可以将图像直接发布到GridFS而不先将其作为临时文件存储在服务器上的任何位置。 我正在使用Postman(chrome ext。)发布文件,并且使用以下方法设法将此帖子存储为文件: 当从服务器上的文件创建readStream时,我也能够从readStream直接存储到GridFS。(请参见代码) 我有以下文件,它们侦听POST并基本上将其传递给。 saveFromRe
-
Java 8 Streams——为什么我不能对一个整数流求和?
给定一个整数列表:
-
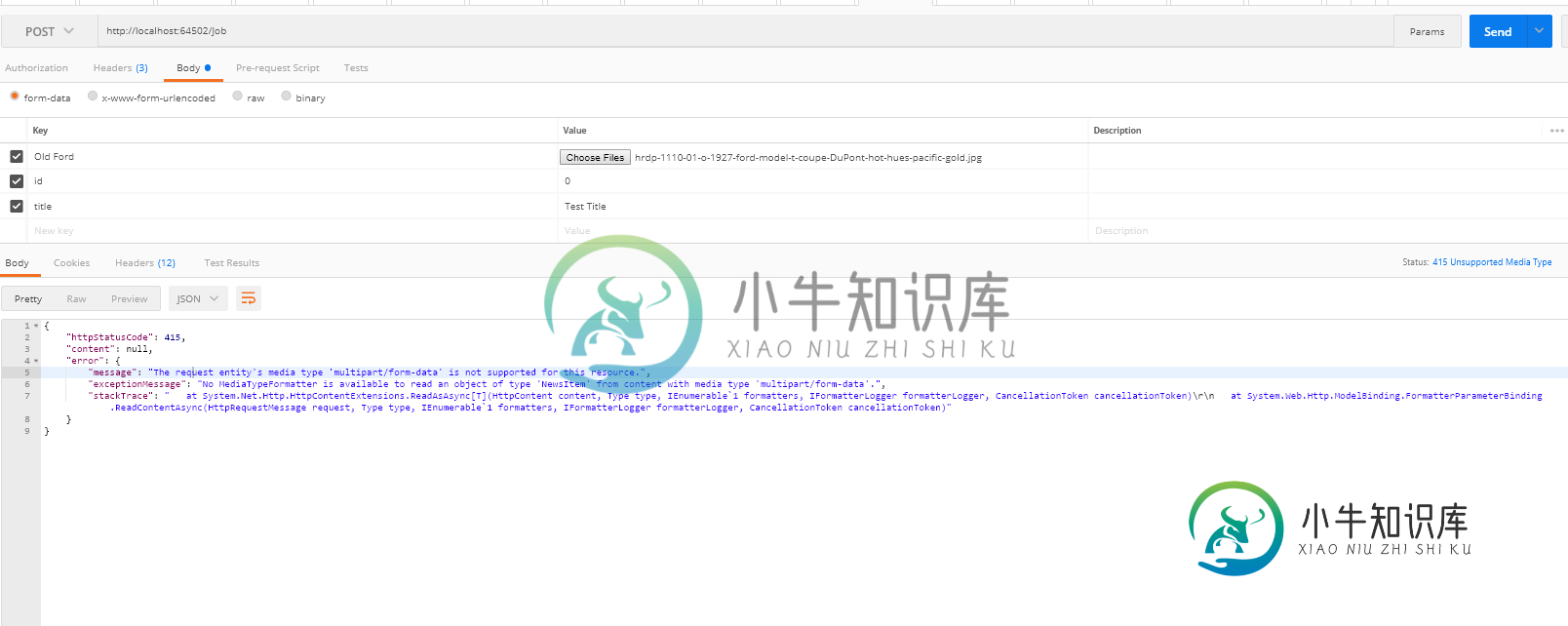 如何在Web API中通过post请求接收流和对象?
如何在Web API中通过post请求接收流和对象?我目前正在使用Web API开发REST Web服务。 现在我试图通过帖子接收流文件和对象。 当我发送它没有JobPosition对象时,我正确地收到了文件,也当我发送JobPosition没有文件时,我正确地收到了JobPosition。 但是当我通过邮递员发送流文件和对象时,我收到了错误。 我将感谢您的帮助,了解这是否可能,如果可能的话,方向将帮助我。 我尝试了所有可能的内容类型组合,但没有成