《求职交流聚集地》专题
-
隐藏聚合物元素
我试图在某一元素条件下隐藏几个聚合物元素。我知道有几种可能性。在我的opinon中,最简单的方法是引入一个新的CSS类 并将其添加到聚合物元素的类列表中 但这对元素没有影响。元素仍然可见。对elment检查器的查看显示,添加了该类: 其中parent-elem是父元素的名称。 谁能解释一下为什么元素不会被隐藏? 谢谢。 问候你,梅森曼
-
带条件的mongotemplate聚合
我有一个集合,其中的文档如下所示:
-
查找聚合性能差
我有两个收藏品 员额:
-
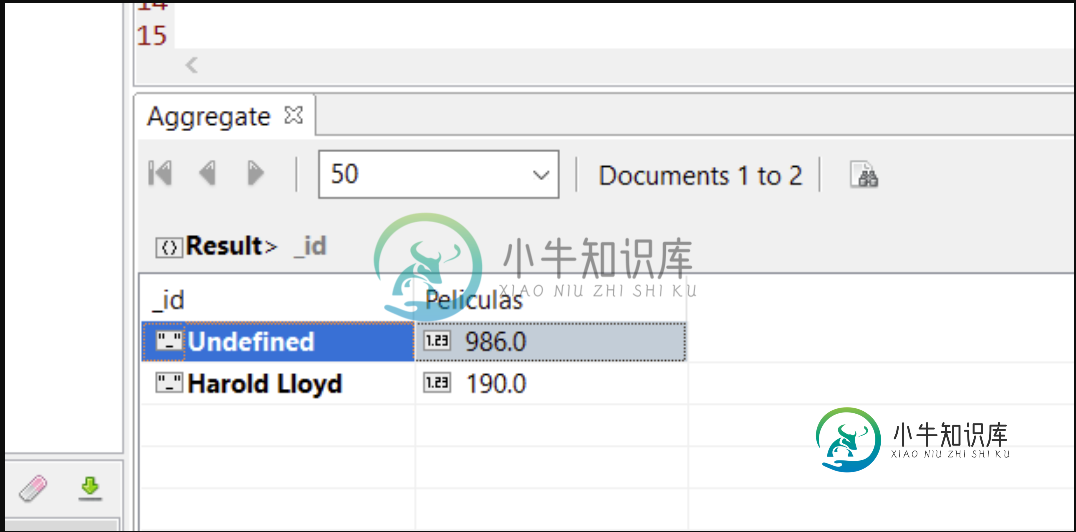 使用mongodb筛选聚合
使用mongodb筛选聚合我需要筛选此查询,以便不显示值为的文档。当前,我的代码显示以下结果: 我需要一些过滤器,使消失,以便它显示我作为第一个值:。 我以前执行过以下操作:
-
Elasticsearch术语聚合排序
我们目前正在开发一个多语言文档CMS。因此,我们有翻译成不同语言的文件。 对于使用Elasticsearch进行搜索,我们目前使用每种语言(德语、英语、法语……)一个索引,其中同一文档的所有翻译共享相同的ID。 当用户搜索特定术语时,我们希望在所有语言中搜索,但只返回不同ID的列表。据我所知,只有使用以下术语聚合才能做到这一点: 这很好,但是作为弹性搜索文档https://www.elastic.
-
聚合 DTO 中的字段
我有一些架构/模式问题。假设我有一个有两个类的域模型。我使用代码优先和存储库模式。(为了使示例更简单,我只使用字段,而不使用属性) 我还有PersonDto和PetDto类,唯一不同的是,PersonDto中的Pets字段是一个简单的List。我使用Automapper将模型类转换为dto。接下来通过REST Api将Dto发送给客户端。现在,如果在某个视图中,我需要为每个人显示其姓名、姓氏和宠物
-
Cassandra聚类密钥顺序
所以我有一张表,它看起来像这样: 我们依赖该表根据进行分页来正确排序。 问题是:当从cassandra返回结果时,看起来它们是根据ASCII值而不是逻辑的A-Z排序进行排序的。-对于观看它的人来说,这在程序上是有意义的,但在逻辑上是不合理的。 是否有一个选项来改变当前聚类顺序的方法? -或者另一种逻辑排序的方法?
-
28 聚合函数 MIN、MAX
MySQL 的常见的聚合函数有 AVG、COUNT、SUM、MIN、MAX,上一小节介绍了 AVG、COUNT、SUM 三种聚合函数,本小节介绍如何使用 MIN、MAX 两种聚合函数,另外再介绍一下如何在 GROUP BY 中使用聚合函数。 1.MIN函数取最小值 以 teacher 表为例,先查所有 teacher 信息: SELECT * FROM teacher; 查询结果如下图: 可以使
-
8.3.1 理解 K-Means 聚类
目标 在本章中,我们将理解K均值聚类的概念,它是如何工作的等等。 理论基础 我们将用一个常用的例子来讲解这个问题。 T恤大小问题 考虑一家正在向市场推出新款T恤的公司。显然,他们将不得不制造不同大小的模型来满足各种身材的人。因此,公司提供了一个人的身高和体重的数据,并将其绘制在一张图上。 公司不能制作所有尺码的T恤。相反,他们把人们分为小,中,大三种尺寸,只制造出适合所有人的三种尺寸。这种把人分成
-
谱聚类(spectral clustering)原理
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。 乍一看,这个算法原理的确简单,但是要完全理解这个算法的话,需要对图论
-
DBSCAN密度聚类算法
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。 通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。 2. DBSCAN密度定义 在上一节我们定性描述了密度聚类
-
BIRCH聚类算法原理
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),名字实在是太长了,不过没关系,其实只要明白它是用层次方法来聚类和规约数据就可以了。刚才提到了,BIRCH只需要单遍扫描数据集就能进行聚类,那它是怎么做到的呢? BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个数结构类
-
事件聚合器(Event Aggregator)
当您的事件需要附加到更多侦听器或需要观察应用程序的某些功能并等待数据更新时,应使用事件聚合器。 Aurelia事件聚合器有三种方法。 publish方法将触发事件,并可供多个订阅者使用。 对于订阅事件,我们可以使用subscribe方法。 最后,我们可以使用dispose方法分离订阅者。 以下示例演示了这一点。 我们的视图将为三个功能中的每一个提供三个按钮。 app.html <template>
-
聚合器模块(Aggregator Module)
在本章中,我们将研究Drupal中的Aggregator Module 。 聚合器模块从其他网站获取内容,但不生成任何源。 它也被称为饲料阅读器。 它收集并显示来自其他网站和博客的文本和图像。 以下是启用聚合器模块的步骤。 Step 1 - 单击菜单栏中的Modules 。 Step 2 - 显示不同模块的列表。 启用Aggregator模块,然后单击Save Configuration ,如以下
-
 网聚宝开发指南
网聚宝开发指南开发流程统一化文档叙述了网聚宝的技术部同学在开发过程中遇到的一些必要关键步骤。请在开发时参照此文档进行操作,如遇到文档中未阐明的问题,可以对此文档进行必要的补充,集思广义会促使这个文档愈来愈全面,最终形成不断更新的网聚宝开发手册。