《求职交流聚集地》专题
-
MongoDB聚合功能浅析
本文向大家介绍MongoDB聚合功能浅析,包括了MongoDB聚合功能浅析的使用技巧和注意事项,需要的朋友参考一下 MongoDB数据库功能强大!除了基本的查询功能之外,还提供了强大的聚合功能。这里简单介绍一下count、distinct和group。 1.count: 2.distinct: distinct用来找出给定键的所有不同的值。使用时也必须指定集合和键。
-
聚合计数逻辑值
您好,朋友,我对mongodb聚合不友好,我想要的是,我有一个对象数组,其中包含每个问题的主题分数,我使用的是节点js,所以我想要的是,如果可能的话,使用mongo查询进行完整计算,包括主题名称及其总分和尝试次数,不尝试我的Json数组如下 在对象中,一个字段用于正确标记主题不同,我希望输出如下 我正在尝试聚合,但尚未完成我已尝试此查询 任何人都知道如何实现这种类型的输出。而如果用另一种方式来实现
-
Mongoose中的聚合结果
我有一个数据库,里面有澳大利亚800家不同的酒吧、俱乐部和餐馆。 我想为我的网站建立一个链接列表,统计不同郊区和主要类别的不同场馆的数量。 像这样: 餐厅,伯恩山(15家) 餐厅,道斯角(6家) 俱乐部,悉尼(138家) 我可以通过首先获得所有场馆来艰难地完成这项任务。然后运行一个场地。distinct('details.location.Suburban')获得所有独特的郊区。 从这里,我可以运
-
MongoDB聚合查询组By
假设我有一个MongoDB集合,其中包含以下信息: 我想计算按州分组的订单总价的总和,其中项目为“苹果”,颜色为“红色”。我的问题是: 但是,我希望能够将我的结果cust\u id包含在\u id中,它是一个数组/映射/一些结构,其中包含构成我的合计的所有客户id的列表。因此,我希望我的输出包含 是否有办法处理此mongo聚合/查询?或者是一种更好的方式来构造此查询,以便我可以按州分组计算红苹果的
-
环回上的MongoDB聚合
问题内容: 如何获得Loopback PersistedModel的总和? 似乎没有有关如何实现该目标的文档。 如果可能的话,我想避免不得不查找所有行并将其汇总到Node.js中。 更新 从https://github.com/strongloop/loopback/issues/890尝试示例 我有一个错误 如何获取集合的句柄以在MongoDB集合上手动运行聚合查询? 问题答案: 最终设法使其工
-
SQL查询聚合/级联
问题内容: 我有一个这样的表: SQL查询应如何汇总以下结果: 问题答案: 注意:STUFF函数只是从返回的字符串中删除前导/。
-
如何聚合布尔列
问题内容: 我如何聚合这样的一些元组 与OR函数并返回下表? 问题答案: 只需执行一次,使用即可返回T(如果有),否则返回F。
-
Elasticsearch嵌套动态聚合
我试图在c#中运行聚合查询(使用nest 5),但我不知道我得到了多少聚合作为输入以及聚合类型是什么。 例如,一个查询是:{"aggs":{"type_count":{"术语":{"field":"type"}}}} 其他查询将是:{“aggs”:{“type\u count”:{“terms”:{“field”:“type”}},“salary\u count”:{“field”:“salary
-
Spark:数据帧聚合(Scala)
我正在考虑将dataset1分解为每个“T”类型的多个记录,然后与DataSet2连接。但是你能给我一个更好的方法,如果数据集变大了,它不会影响性能吗?
-
GoogleMapReact标记聚类问题
嗨,我正在制作一个反应网站,理想情况下应该包括标记的聚类。 我使用了两种不同的技术,都能有效地显示在地图上,还有一种甚至是集群,但我希望我能将这些技术结合起来。 原因是这两种技术略有不同,使用有效集群的技术不会让我映射出组件,而是必须返回一个google标记。 这是我使用的第一种技术。 我真的很喜欢这种技术,因为它只是允许您将任何组件映射到屏幕的lat和lng。然而,使用这种技术,我无法得到这些标
-
Vertx聚类替代方案
除了Hazelcast之外,任何有Vertx群集管理器实际经验的人都对我们的以下要求有什么建议? 对于我们的(实时传感器数据)系统,我们在多个JVM中有数百个垂直链接,但我们不需要或不希望eventbus跨多个物理服务器。 我们在多个服务器上运行Vertx,但如果我们不在所有服务器之间共享一个eventbus,那么我们的平台就不那么复杂了(我们更愿意明确说明在服务器之间传递消息)。 Hazelca
-
ElasticSearch多级父子聚合
我有3个级别的父/子结构。假设: 公司- 由于这里经常更新可用性(以及员工),所以我选择对嵌套使用父/子结构。搜索功能工作正常(所有文档都在正确的碎片中)。 现在我想对这些结果进行排序。按公司(第1级)的元数据对它们进行排序很容易。但我也需要按第3级(可用性)进行排序。 我想要按以下顺序排列的公司列表: 与给定ASC位置的距离 评级DESC 最快可用性ASC 例如: A公司距离我们5英里,评分为4
-
ElasticSearch多词聚合顺序
我有一个描述容器的文档结构,它的一些字段是: 我想运行一个搜索聚合,该聚合在两个权重字段上有两个级别的术语聚合,但按权重字段的降序排列,如下所示: 样本文件: 预期输出(未完成): 但是,我不能按嵌套聚合排序。(错误:术语桶只能在子聚合器路径上排序,该子聚合器路径由路径中的零个或多个单桶聚合和最终的单桶或指标聚合构建...) 例如,对于上述示例输出,如果我在术语聚合上引入大小(如果我的数据很大,我
-
排序elasticsearch范围聚合
是否可以在elasticsearch中更改范围聚合结果的排序?我在elasticsearch中有一个键控范围查询,并希望根据键而不是doc_count进行排序。 我的文件是: 和聚合查询: 此查询的结果是: 我想根据关键字对结果进行排序,而不是根据范围值。根据elasticsearch文档,无法指定排序顺序,当指定排序顺序时,我得到以下异常: 你有什么办法吗?谢谢!
-
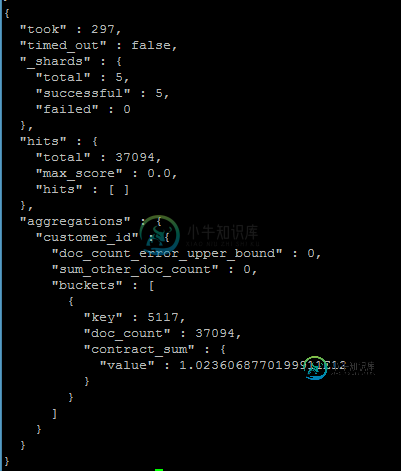 使用Java的ElasticSearch聚合
使用Java的ElasticSearch聚合我想在我的java应用程序中获得聚合。 首先,我用curl构造了REST查询。它看起来像: 结果和我预期的一样 之后我在java中创建了一些代码 问题是: 如何获取当前bucket项的“contract\u sum”聚合值? 当我在IntelliJ Idea中使用调试工具时,它似乎可以 请帮助我的代码示例。