《求职交流聚集地》专题
-
交易
交易有不同的分类,不同交易有不同的操作码。 这样做的好处就是明确用户行为,简化系统复杂度。 操作码列表 OpsTransfer:用于普通的链内转账 OpsMove:用于链间的转账 OpsNewChain:用于创建新的子链 OpsNewApp:用于创建智能合约 OpsRunApp:用于执行智能合约 OpsRegisterMiner:用于注册矿工 OpsUpdateAppLife:更新智能合约的生命周
-
对dataframe数据之间求补集的实例详解
本文向大家介绍对dataframe数据之间求补集的实例详解,包括了对dataframe数据之间求补集的实例详解的使用技巧和注意事项,需要的朋友参考一下 python的pandas库,对于dataframe数据,有merge命令可以完成dataframe数据之间的求取交集并集等命令。 若存在df1与df2 ,他们的交集df3=pd.merge(df1,df2,on=[.....])。但是又想通过df
-
如何请求node.js中的垃圾收集器运行?
问题内容: 在启动时,似乎我的node.js应用程序使用了大约200MB的内存。如果我搁置一段时间,它会缩小到9MB左右。 是否可以从应用程序内执行以下操作: 检查应用程序正在使用多少内存? 请求垃圾收集器运行? 我问的原因是,我从磁盘加载了一些文件,这些文件是临时处理的。这可能导致内存使用量激增。但是我不希望在GC运行之前加载更多文件,否则存在内存不足的风险。 有什么建议 ? 问题答案: 如果使
-
RabbitMQ 对集群节点停止顺序有要求吗?
本文向大家介绍RabbitMQ 对集群节点停止顺序有要求吗?相关面试题,主要包含被问及RabbitMQ 对集群节点停止顺序有要求吗?时的应答技巧和注意事项,需要的朋友参考一下 RabbitMQ 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
-
AWS API网关覆盖集成请求映射模板
当我发送一个带有POST请求的正文时,我的模板映射似乎被有效负载覆盖了。 我有一个调用Lambda函数的API网关资源。Lambda函数很简单,它只是回显它接收到的内容。 这个名为echo的Lambda函数通过POST调用Lambda函数。POST方法有一个集成请求映射模板(直接来自文档): 当我在没有尸体的情况下提出请求时,我会得到我期望的答复: 但是,当我用主体发出请求时,模板映射不再工作:
-
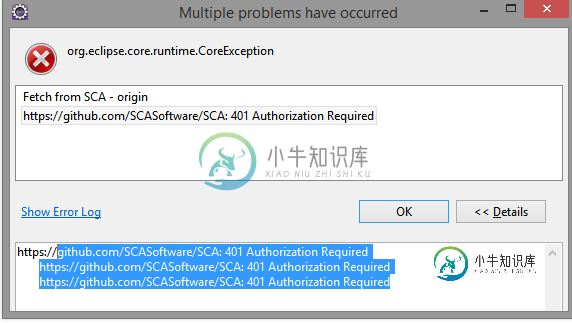 Eclipse Neon eGit集成提供异常401授权要求
Eclipse Neon eGit集成提供异常401授权要求升级到Neon后,我的Egit集成失败,出现以下异常 更新:参见eclipse bug I.errors.transportException:https://github.com/[REPOSITORY]/sca:401在org.eclipse.jgit.api.pushcommand.call(pushcommand.java:169)在org.eclipse.egit.core.op.pus
-
WSO2集成器:REST API GET请求缺少响应体
我正在使用WSO2 Integrator6.6.0使阻塞HTTP获得返回JSON响应的REST API(HTTP 200 OK)。 但我从未在序列中看到反应体。我不确定我做错了什么,已经用尽了所有可用的文档和其他线程。 执行调用的序列(简化为匿名),随后记录响应: 这只会导致一个日志行--根本没有响应体! 我可以在我的API应用程序中看到请求,我还可以看到它在日志中正确地返回响应体。此外,使用Po
-
7.3.4 获得请求参数集合的内置对象
EL表达式中的param和paramValues对象都可以获得请求参数集合,它们的区别是param对象返回的Map对象的value是String类型,而paramValues对象返回的Map对象的value是String[]类型。因此,paramValues对象可以用于获得可能有重名的请求参数集合。而param对象用于获得没有重名的请求参数集合。如要获得请求参数name的值,可以使用如下的代码:
-
谷歌数据流和发布订阅 - 无法实现一次交付
我正在尝试使用Google Dataflow和Apache Beam SDK 2.6.0的PubSub实现一次性交付。 用例非常简单: 'Generator'数据流作业将1M消息发送到PubSub主题。 “存档”数据流作业从PubSub订阅中读取消息,并保存到Google云存储中。 我在 Pubsub.IO.Write(“生成器”作业)和 PubsubIO.Read(“存档”作业)中都添加了“带
-
SQL Azure中的代码优先迁移-不支持没有聚集索引的表
问题内容: 我似乎无法进行代码优先迁移来创建SQL Azure数据库。 它总是抱怨SQL Azure缺少对没有聚簇索引的表的支持,而且我找不到周围的方法来创建数据库。 注意: 我用来在第一次创建数据库时创建更改跟踪表,因为显然它并不能为您做到这一点 如果我尝试`Update-Database,我会得到 未创建数据库。 更新: 我从头开始,并按照本指南启用了自动迁移(对数据库进行了刮擦,并从一个不存
-
结果集未打开。验证自动提交已关闭。Apache Debry
问题内容: 我正在为我的数据库使用apache derby。我能够对数据库执行插入操作。以下是尝试显示我唯一的表’MAINTAB’的内容的代码摘录。java.sql.Connection的实例为’dbconn’。 以下是输出。 当它第一次要求验证AUTOCOMMIT是否为OFF时,我从Derby文档中发现默认情况下AUTOCOMMIT对任何连接都是打开的。因此,我已使用dbconn.setAuto
-
事务提交/回滚不在spring集成通道适配器上
我正在使用spring integration来设置消息流。我从一个目录中读取文件,并对它们做一些事情。我已经在入站通道适配器上设置了一个poller,其中包括事务管理器和同步工厂。同步工厂将after-commit和after-rollback推送到通道,这些通道将原始文件推送到成功或失败文件夹。这一切都很好。 现在的问题是,当处理一些文件时,它们可能会产生新的消息,我想通过同样的过程循环。我不
-
返回子文档数组与用户定义数组的交集?
我正在尝试使用Mongo聚合框架来找出我文档中的数组和另一个用户定义的数组之间的交集。我没有得到正确的结果,我的猜测是因为我在数组中有数组。 这是我的数据集。 我的文档: 我的查询: 结果: 我不希望第一个公共字段为空。有人能告诉我我做错了什么吗?或者我能采取的任何变通办法。 我正在使用MongoDB 3.0.8。我知道Mongob 3.2可以提供一些功能来满足我的需求,但3.2升级不会很快在我们
-
将社交登录与自己的OAuth2 REST API服务器集成
无论我使用什么技术,任何通用的解决方案都将有所帮助。谢谢
-
ElasticSearch-按嵌套字段上的嵌套聚合排序聚合
在这里,我得到了错误: “无效的术语聚合顺序路径[price>price>price.max]。术语桶只能在子聚合器路径上排序,该路径由路径中的零个或多个单桶聚合和路径末尾的最终单桶或度量聚合组成。子路径[price]指向非单桶聚合” 如果我按持续时间聚合排序,查询可以正常工作,如 那么,有什么方法可以通过嵌套字段上的嵌套聚合来排序聚合吗?