《求职交流聚集地》专题
-
 C#制作简单的多人在线即时交流聊天室
C#制作简单的多人在线即时交流聊天室本文向大家介绍C#制作简单的多人在线即时交流聊天室,包括了C#制作简单的多人在线即时交流聊天室的使用技巧和注意事项,需要的朋友参考一下 实现网页版的在线聊天室的方法有很多,在没有来到HTML5之前,常见的有:定时轮询、长连接+长轮询、基于第三方插件(如FLASH的Socket),而如果是HTML5,则比较简单,可以直接使用WebSocket,当然HTML5目前在PC端并没有被所有浏览器支持,所以我
-
 2023届秋招 |字节跳动交互设计 流畅的一面
2023届秋招 |字节跳动交互设计 流畅的一面投的是交互设计的产品研发岗,早早投递流程慢如狗 流程:投递—收到设计笔试题—提交笔试题—约面—一面—收到二面邀约(字节的流程推进真的很离谱,笔试题交了两周才约面,直接约到三周后… 面试过程:面试体验还比较舒服,上来面试官比较客气地介绍了自己的身份,所属的部门,以及在做的项目等。然后就是常规的交互面试内容:自我介绍—作品集—面试官提问—反问。说一下印象比较深的几个问题: 比较注重细节,问了我项目里的
-
 2023届秋招 |字节跳动交互设计 流畅的一面
2023届秋招 |字节跳动交互设计 流畅的一面投的是交互设计的产品研发岗 面试过程:面试体验还比较舒服,上来面试官比较客气地介绍了自己的身份,所属的部门,以及在做的项目等。然后就是常规的交互面试内容:自我介绍—作品集—面试官提问—反问。说一下印象比较深的几个问题: 比较注重细节,问了我项目里的“金选榜单”界面的星级评判标准,为什么选择星星,为什么选择金色等,还给我了一些设计建议。 讲解笔试题的时候,因为我选择的设计题是redesign苹果的a
-
MongoDB$Geonear聚合流水线(使用查询选项和使用$match流水线操作)给出不同的结果no
我使用$geonear作为聚合框架的第一步。我需要过滤掉基于“标签”字段的结果,它工作得很好,但我看到有两种方式都给出了不同的结果。 MongoDB文档示例 我已经向“Position”键添加了2dSphere索引 两个查询返回的totalDocs似乎不同。 有人能给我解释一下这两个查询之间的区别吗?
-
如何使用IDE在Storm生产集群中提交拓扑
问题内容: 我在使用IDE向生产集群提交拓扑时遇到了一个问题,而如果我在命令行中使用command 执行同样的事情,它的运行就像天堂一样。我从githublink看到了同样的例子。 为了提交拓扑,我正在使用这些行集 请建议我这是否是运行的正确方法? 问题答案: 很好找到解决方案。当我们运行“ storm jar”时,它将在提交的jar中触发storm.jar的属性标志。因此,如果我们要以编程方式提
-
从远程客户端在Yarn集群上提交Spark作业
我被困在: 在我得到这个之前: 当我签出应用程序跟踪页面时,我在stderr上得到以下信息: 我对这一切都很陌生,也许我的推理有缺陷,任何投入或建议都会有所帮助。
-
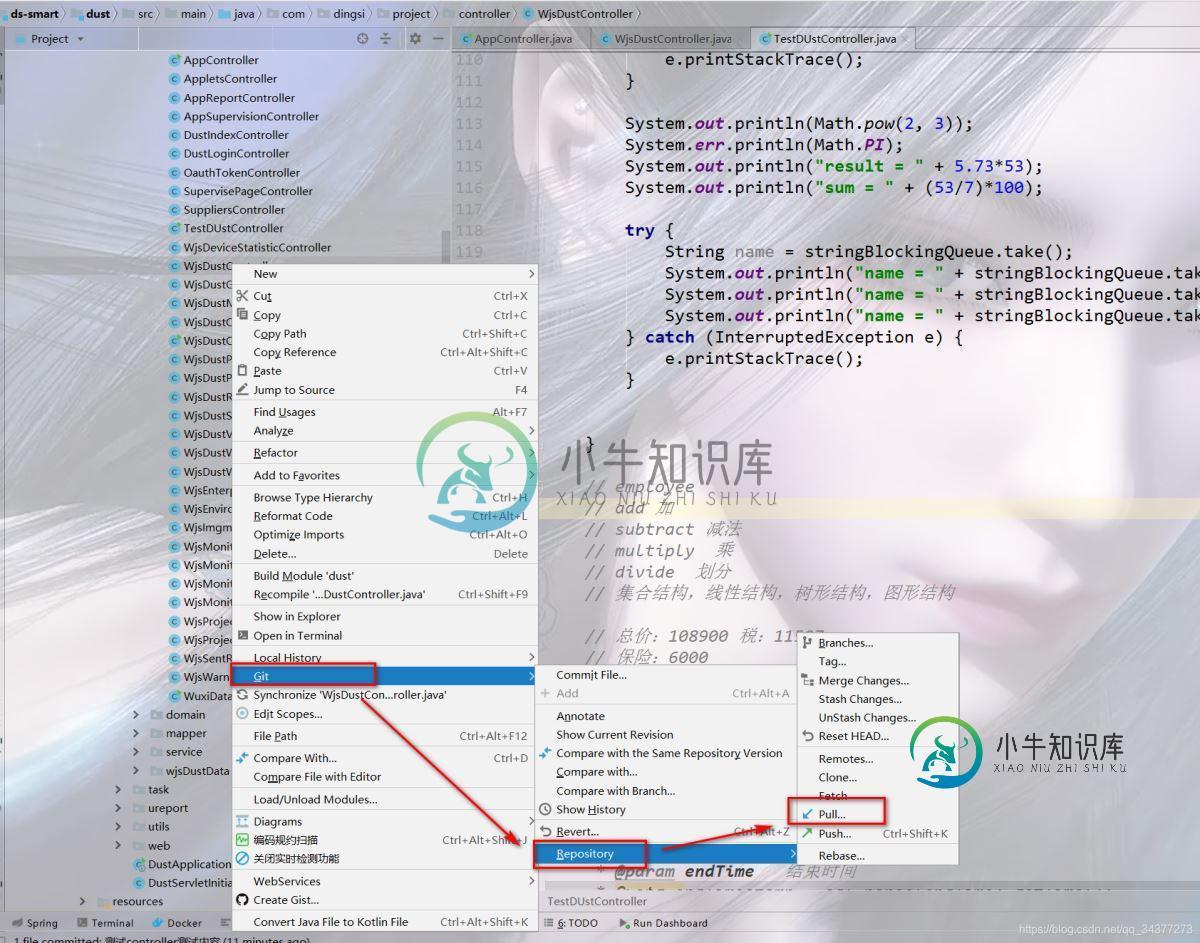 IDEA中项目集成git提交代码的详细步骤
IDEA中项目集成git提交代码的详细步骤本文向大家介绍IDEA中项目集成git提交代码的详细步骤,包括了IDEA中项目集成git提交代码的详细步骤的使用技巧和注意事项,需要的朋友参考一下 简介:在团队协作开发的过程中,好的代码管理能更加有效的使日常开发的过程中对各个开发人员提高开发速度。下面将详细介绍在IDEA中使用git提交代码的过程: 一:pull代码 在提交代码之前,我们必须先对代码就行更新操作,这一步非常重要,如果不进行更新代码
-
如何使用不相交集检测无向图中的圈?
算法: 图表: (1)-------(2) 邻接列表: [1] - [2] - 不相交集: {{1}, {2}} 迭代1: 边e=(1,2) 联盟(1,2) 不相交集={{1,2}} 迭代2: 边e=(2,1) 2和1都属于同一个集合,所以算法检测到一个循环,很明显图不包含循环。 对于有向图,该算法可以完美地工作。请帮我分析一下。
-
如何配置kubectl以与minikube和部署的集群交互?
当您使用minikube时,它会自动创建本地配置,因此可以随时使用。并且根据kubectl配置的引用,在kubectl命令中似乎支持多个集群。 环境变量似乎可以引用这些配置文件的多个位置,内置默认值为(这是minikube创建的)。 如果我希望能够使用kubectl调用多个集群的命令,我是否应该将相关的配置文件下载到一个新的位置(例如,下载到,将环境变量设置为引用这两个位置? 还是在调用kubec
-
spark与kafka的集成,spark中的例外-提交一个jar
我试着检查在Ubuntu下安装spark是否需要set HADOOP_HOME;但是,没有设置HADOOP_HOME,请仔细检查JAR的参数。 线程“main”java.lang.NullPointerException(位于org.apache.hadoop.fs.path.getName(Path.java:337)(位于org.apache.spark.deploy.deploy.deplo
-
使用数据集在Apache Spark中交叉加入非常慢
我已经在spark用户论坛上发布了这个问题,但没有收到回复,所以再次在这里提问。 我们有一个用例,我们需要做笛卡尔连接,由于某种原因,我们无法让它与数据集 API 一起工作。 我们有两个数据集: > 一个包含 2 个字符串列的数据集表示 C1、C2。它是一个包含 ~100 万条记录的小数据集。这两列都是 32 个字符的字符串,因此应小于 500 mb。 我们广播了这个数据集 如果我使用RDD ap
-
如何将作业提交给其他集群上的纱线?
我有一个安装了spark的docker容器,我正试图使用马拉松将作业提交给其他集群上的yarn。docker容器有yarn和hadoop conf dir的导出值,yarn文件还包含正确的emr主ip地址,但我不确定它从哪里作为本地主机? 错误:
-
是否可以将“查询”与“聚合”和“分组依据”组合(结果集)?
问题内容: 1个 结果集 : 2个 结果集2: 有没有办法可以做到这一点: 我想在RHEL 5上使用Sybase 12.5的解决方案,我也想知道在其他任何数据库系统中是否可行。 -–谢谢您的回答- 问题答案: 通过为该列使用CASE / WHEN并基于true / false求和1或0,您可以在同一查询中获得这两者。此外,如果您希望将另一个值的总和作为另一个,则可以执行相同的操作列…只需将其替换为
-
Spring Boot响应已经提交,对资源的请求异常
我使用的是部署在Wildfly8.2服务器上的Spring Boot(V1.2.4)。在应用程序中,我使用的是字体awesome V4.3。 我得到的“响应已经提交异常”如下三个文件的堆栈跟踪,每个文件都小于100KB。 null 请帮忙。
-
使用Runtime.getRuntime在kotlin中提交请求。执行数据错误
我正在 intellij 中构建一个插件,并希望提出 curl 请求。该插件是用kotlin编写的。 以下curl请求有效: 但以下带有数据的POST请求没有: 我正在使用这个函数来运行请求: 它只是抛出一个错误: 我已尝试使用-g开关运行请求以查找全局错误。但后来我遇到了另一个: 我在这里错过了什么? PS:我不得不将 curl 命令分解为数组,否则它不起作用。检查:无法通过 java Runt