《存储》专题
-
Nginx内容缓存
主要内容:1. 介绍,2. 启用响应缓存,3. 涉及缓存的NGINX进程,4. 指定要缓存的请求,5. 限制或绕过缓存,6. 从缓存中清除内容,7. 字节缓存,8. 组合配置示例本节介绍如何启用和配置从代理服务器接收的响应的缓存。主要涉及以下内容 - 缓存介绍 启用响应缓存 涉及缓存的NGINX进程 指定要缓存的请求 限制或绕过缓存 从缓存中清除内容 配置缓存清除 发送清除命令 限制访问清除命令 从缓存中完全删除文件 缓存清除配置示例 字节缓存 组合配置示例 1. 介绍 当启用缓存时,NGINX
-
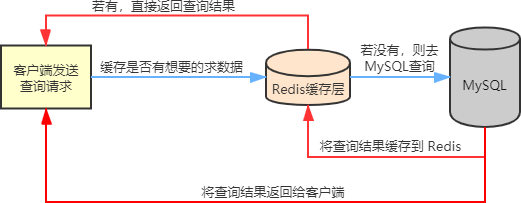 Redis缓存问题
Redis缓存问题主要内容:缓存穿透,缓存击穿,缓存雪崩在实际的业务场景中,Redis 一般和其他数据库搭配使用,用来减轻后端数据库的压力,比如和关系型数据库 MySQL 配合使用。 Redis 会把 MySQL 中经常被查询的数据缓存起来,比如热点数据,这样当用户来访问的时候,就不需要到 MySQL 中去查询了,而是直接获取 Redis 中的缓存数据,从而降低了后端数据库的读取压力。如果说用户查询的数据 Redis 没有,此时用户的查询请求就会转到
-
 Hibernate一级缓存
Hibernate一级缓存主要内容:缓存,Hibernate 一级缓存,快照区Hibernate 是一款全自动 ORM 框架,它会在应用程序访问数据时,自动生成 SQL 语句并执行,因此开发人员不需要自己编写 SQL 语句,但这也造成它无法像 MyBatis 一样,能够直接从 SQL 层面严格控制其执行性能以及对数据库的访问频率,所以很容易出现性能不佳的情况。 为此,Hibernate 提供了多种性能优化手段(例如 HQL、懒加载策略、抓取策略以及缓存机制),其中缓存机制是
-
包java.nio.file不存在
我正在研究如何从命令行编译Java。我得到的是: 我得到的是: HelloWorld: inner.java 内部2.Java 我正在用编译这个文件,这个文件工作得很好。 现在我的理解是,因为helloworld.java在它的import语句中引用了其他包,所以javac会去编译这些包。我猜对于所有的Java包,javac在内部都有。 反正-如果我在helloworld.java中添加以下导入行
-
alsa-内存泄漏?
问题内容: 我一直在追寻内存泄漏(由“ valgrind –leak-check = yes”报告),它似乎来自ALSA。这段代码已经存在于自由世界中一段时间了,所以我猜这是我做错的事情。 输出看起来像这样: 并继续一些页面 这是由于我在一个项目中使用ALSA并开始看到这种巨大的泄漏……或者至少是所说泄漏的报告。 所以问题是:是我,ALSA或valgrind在这里遇到问题吗? 问题答案: ht
-
Malloc内存问题
问题内容: 首先,我注意到当我分配内存与calloc时,内存占用量是不同的。我正在使用数GB的数据集。此数据可以是随机的。 我以为我可以分配大量的内存并读取其中的任何随机数据,然后将其强制转换为浮点数。但是,在进程查看器中查看内存占用量时,显然并没有要求使用内存(与calloc相比,我看到了较大的占用空间)。我运行了一个循环,将数据写入内存,然后看到内存占用量攀升。 我是否正确地说,直到初始化内存
-
保存双向ManyToMany
问题内容: 我有两个以下列方式注释的实体类 如果我存储类“ B”的实例,则关系将存储在数据库中,并且类“ A”中的吸气剂将返回B的正确子集。但是,如果我对“ A”中的B列表进行了更改,更改是否不存储在数据库中? 我的问题是,我该如何做到使任一类的更改都“级联”到另一类? 编辑:我尝试过删除mapedBy参数和定义JoinTable(和列)的不同变体,但我一直找不到正确的组合。 问题答案: 最短的答
-
Java内存编译
问题内容: 我如何在运行时从字符串生成字节码(Byte []),而无需使用“ javac”进程或类似的东西?有没有像这样调用编译器的简单方法? 以后添加: 我选择接受最适合 我的 情况的解决方案。我的应用程序是一个尚处于设计草图阶段的业余项目,现在是考虑插入新技术的合适时机。另外,由于应该帮助我解决BL的人是JavaScript开发人员,因此在这种情况下,使用JavaScript解释器而不是存根编
-
1.3.3.3 留存分析
1.1. 1. 概念理解 留存: 用户在某时间开始使用应用,一段时候后,仍然继续使用该应用的用户,即被定义为留存用户; 留存分析: 分析用户参与情况或活跃程度的分析模型; 统计在选定的时间范围内,进行了初始行为的用户中,随后进行后续行为的人数及比例。 1.2. 2. 功能说明 分析用户对产品或某些功能行为的用户黏性 通过不同时间范围内的留存对比分析,找到用户流失的具体原因,对产品优化和改进提供实质
-
8.3 内存管理
一、内存连续分配 主要是指动态分区分配时所采用的几种算法。 动态分区分配又称为可变分区分配,是一种动态划分内存的分区方法。这种分区方法不预先将内存划分,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统中分区的大小和数目是可变的。 首次适应(First Fit)算法: 空闲分区以地址递增的次序链接。分配内存时顺序查找,找到大小能满足要求的第一个空闲分区。
-
Python内存泄漏
问题内容: 我有一个长时间运行的脚本,如果让脚本运行足够长的时间,它将消耗系统上的所有内存。 在不详细介绍脚本的情况下,我有两个问题: 是否有可遵循的“最佳实践”,以防止泄漏发生? 有什么技术可以调试Python中的内存泄漏? 问题答案: 看看这篇文章:跟踪python内存泄漏 另外,请注意,垃圾收集模块实际上可以设置调试标志。看一下功能。此外,请查看Gnibbler的这段代码,以确定调用后已创建
-
nodejs内存不足
问题内容: 我今天遇到一个奇怪的问题。对于其他人来说,这可能是一个简单的答案,但这让我感到困惑。为什么下面的代码会导致内存错误? 我得到了这两个错误之一…第一个是在节点的解释器中运行此代码时,第二个是通过nodeunit运行它时: 严重错误:CALL_AND_RETRY_2分配失败-内存不足 严重错误:JS分配失败-内存不足 问题答案: 当我尝试访问阵列时会发生这种情况。但是获取长度却没有。
-
Java 内存泄漏
本文向大家介绍Java 内存泄漏,包括了Java 内存泄漏的使用技巧和注意事项,需要的朋友参考一下 在Java中,垃圾回收(析构函数的工作)是使用垃圾回收自动完成的。但是,如果代码中有引用它们的对象怎么办?它无法取消分配,即无法清除其内存。如果这种情况一再发生,并且创建或引用的对象根本没有被使用,它们就会变得无用。这就是所谓的内存泄漏。 如果超过了内存限制,则程序将通过抛出错误(即“ OutOfM
-
Python整数缓存
问题内容: 在下面的python脚本中,为什么要执行第二个断言(即,将0加到257并将结果存储在y中,则x和y成为不同的对象)?谢谢! 问题答案: 整数是不可变的,因此任何更改它们的操作都将导致新的内存位置 正在检查对象的实际内存位置…并且基本上不应该用于检查值的相等性(尽管它可以在某些情况下任意工作)
-
HazelCast和SpringBoot缓存
我正在寻找集成Hazelcast到我的应用程序... 我的要求是将所有数据加载到缓存并从缓存中提取。。 我有两个选择。 1) Hazelcast IMap 2)因为我使用的是Spring启动,所以我可以使用(@Cacheable/@CacheEvict)。 我能得到一些建议吗... 提前谢谢你。。