《存储》专题
-
2.6 储存数据
一个程序免不了要储存数据,对于Chrome扩展也是这样。通常Chrome扩展使用以下三种方法中的一种来储存数据:第一种是使用HTML5的localStorage,这种方法在上一节的内容中已经涉及;第二种是使用Chrome提供的存储API;第三种是使用Web SQL Database。 对于一般的扩展,“设置”这种简单的数据可以优先选择第一种,因为这种方法使用简单,可以看成是特殊的JavaScrip
-
4. 存储密码
使用 phpass 库来哈希和比较密码 经 phpass 0.3 测试,在存入数据库之前进行哈希保护用户密码的标准方式。 许多常用的哈希算法如 md5,甚至是 sha1 对于密码存储都是不安全的, 因为骇客能够使用那些算法轻而易举地破解密码。 对密码进行哈希最安全的方法是使用 bcrypt 算法。开源的 phpass 库以一个易于使用的类来提供该功能。 示例 <?php // Include ph
-
MySQL存储引擎
MySQL常用存储引擎 MySQL常用存储引擎之MyISAM MySQL 5.5 之前版本默认存储引擎,在排序、分组等操作中,当数量超过一定大小之后,由查询优化器建立的临时表。 MyISAM 存储引擎表由 MYD (表数据) 、MYI (表索引) 与 frm (表结构) 组成。 MyISAM 特性 并发性与锁级别 表级锁 表损坏修复 check table tableName repair tab
-
存储机制 Slabs
一、前言 前几章节我们介绍了Memcached的网络模型,命令行的解析,消息回应,HashTable,Memcached的增删改查操作以及LRU算法模块。 这一章我们重点讲解Memcached的存储机制Slabs。Memcached存储Item的代码都是在slabs.c中来实现的。 在解读这一章前,我们必须先了解几个概念。 Item 缓存数据存储的基本单元 Item是Memcached存储的最小单
-
什么存储在堆上,什么存储在堆上?
问题内容: 任何人都可以用C,C ++和Java清楚地解释一下。什么都在堆栈上,什么都在堆上以及何时分配。 我所知道的, 每个函数调用的所有局部变量(无论是基元,指针还是引用变量)都在新的堆栈框架上。 使用new或malloc创建的所有内容都会进入堆。 我对几件事感到困惑。 是在堆上创建的对象成员的引用/基元是否也存储在堆上? 以及在每个框架中递归创建的方法的那些本地成员呢?它们都在堆栈上吗?如果
-
在Redis缓存中存储多个版本的数据
问题内容: 我有一些产品数据需要在Redis缓存中存储多个版本。数据是JSON序列化的。获取纯(基本)数据的过程非常昂贵,将其自定义为不同版本的过程也很昂贵,因此我想缓存所有版本以尽可能进行优化。假设自定义基于单个参数,我可以将该参数用作缓存键的一部分。 我计划用来检索产品数据的过程是这样的: 一切都很好,但是我现在正在尝试找出在基础数据源发生更改时使缓存数据无效的最佳方法。如果基本产品信息发生变
-
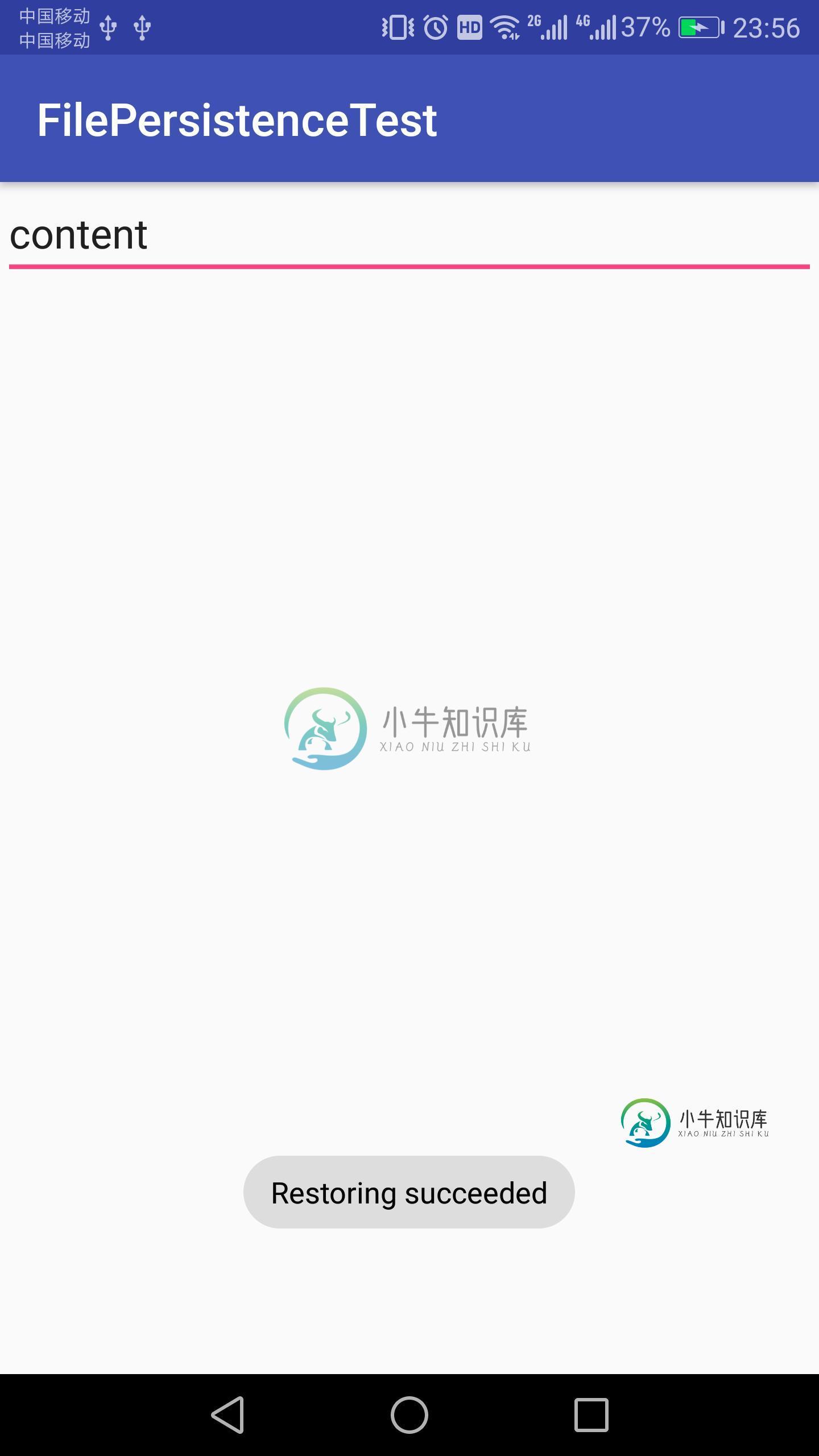 Android基础教程数据存储之文件存储
Android基础教程数据存储之文件存储本文向大家介绍Android基础教程数据存储之文件存储,包括了Android基础教程数据存储之文件存储的使用技巧和注意事项,需要的朋友参考一下 Android基础教程数据存储之文件存储 将数据存储到文件中并读取数据 1、新建FilePersistenceTest项目,并修改activity_main.xml中的代码,如下:(只加入了EditText,用于输入文本内容,不管输入什么按下back键就丢
-
PHP基于文件存储实现缓存的方法
本文向大家介绍PHP基于文件存储实现缓存的方法,包括了PHP基于文件存储实现缓存的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP基于文件存储实现缓存的方法。分享给大家供大家参考。具体如下: 在一些数据库数据记录较大,但是服务器有限的时候,可能一条MySQL查询就会好几百毫秒,一个简单的页面一般也有十几条查询,这个时候也个页面加载下来基本要好几秒了,如果并发量高的话服务器基本就瘫
-
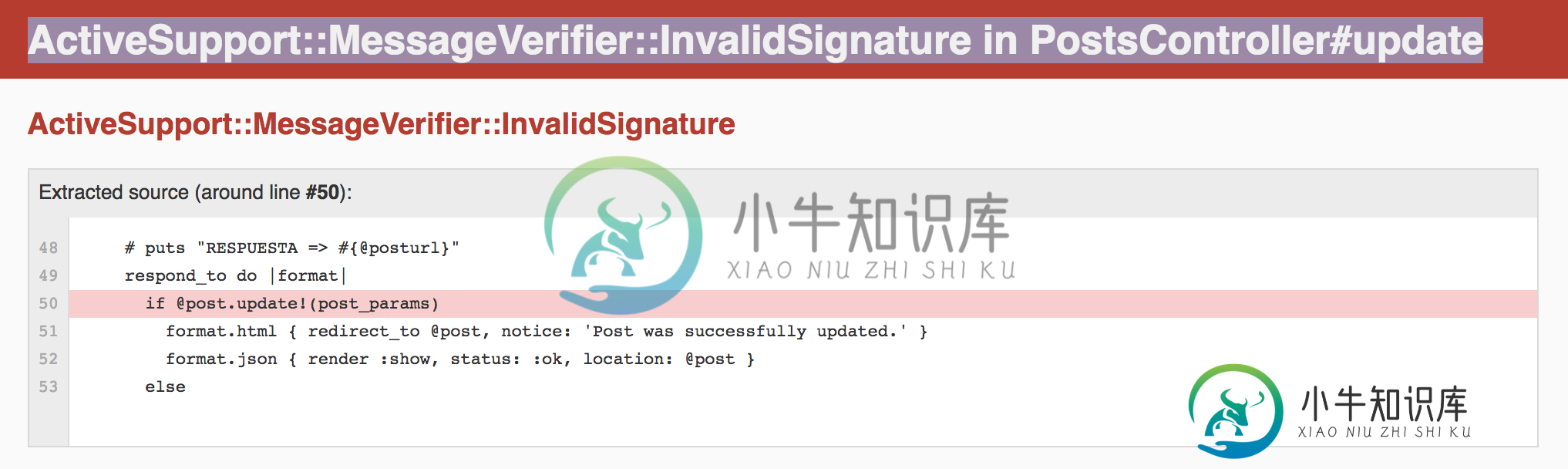 如何使用主动存储从URL存储图像
如何使用主动存储从URL存储图像我的问题是:当我使用活动存储时,如何从URL上传图像。我在Stackoverflow中使用了来自其他帖子的代码,但传递了model方法,即我需要存储在表中的param。奇怪的是,我收到了下一个错误: 但是当我从这个模型重新加载show视图时,图像显示为存储并部署在我的posts视图中。 在这里我的代码后模型: 这是我在控制器的编辑操作中的代码: 我得到了以下链接,其中谈到了从URL上传图像的机会,
-
MIPS中是否存在执行存储数据危险?
在具有管道和转发功能的MIPS体系结构上: add指令将在步骤3(执行操作)准备好结果,但我假设sw指令希望在步骤2(指令解码)得到结果 David A. Patterson的《计算机组织与设计》一书中有一个已解决的练习:在以下代码段中找到危险并重新排序指令以避免任何管道停滞: 解决方案: 在解决方案中,它正确识别加载使用危险并相应地重新排列代码,但是否也存在执行存储危险?
-
.net:使用存储过程中的dataAdapter存储.net datatable
我有一个存储过程叫做 我试图将它们的结果存储在数据表中。 它会导致以下错误: 系统。数据。Odbc。ORA-00900:无效的SQL语句 在ConexionBD.ConnectAndQuery(stringlayername、decimalidelemento、stringidelementostring、stringconexion)。 我的代码:
-
在Redis缓存中存储多个版本的数据
我有一些需要在Redis缓存中存储多个版本的产品数据。数据是JSON序列化的。获取普通(基本)数据的过程是昂贵的,将其定制成不同版本的过程也是昂贵的,因此我希望缓存所有版本以尽可能优化。假设定制是基于一个参数的,我可以使用该参数作为缓存键的一部分。 我计划用于检索产品数据的过程如下所示: 所有这些工作都很好,但我现在正在尝试找出当底层数据源更改时使缓存数据无效的最佳方法。如果基本产品信息发生变化,
-
将 EhCache 磁盘存储内容加载到内存中
如EhCache留档所述: 实际上,这意味着持久性内存中缓存将启动,其所有元素都将在磁盘上。[...]因此,Ehcache设计不会在启动时将它们全部加载到内存中,而是根据需要懒惰地加载它们。 我希望内存缓存启动时将所有元素都存储在内存中,我该如何实现? 这是因为我们的网站对缓存执行了大量的访问,所以我们第一次访问网站时,它的响应时间非常长。
-
Spring网关Redis会话存储类型-保存问题
我有一个微服务架构中的spring网关。 当请求到达网关时,它必须以下面提到的方式进行操作 创建会话并设置属性 在redis中保存会话 将请求路由到Microservice B Microservice B接收会话ID并从会话获取属性 在尝试实现这一点时,(第2点)保存会话ID的操作发生在调用microservices B并返回其响应(第4点)之后。(即第2点发生在第4点之后)。 但是,在请求被路
-
Database ricks将Rdata文件保存到AWS S3存储桶
我使用数据砖在R中开发了一个模型。我想将输出数据文件保存在 AWS S3 存储桶上,但当我保存文件如下时,它不会保存到挂载的驱动器。 使用R将数据挂载到S3的最佳方法是什么? 我已经尝试了下面的示例代码,它可以工作,所以我知道我在AWS和Database ricks之间的连接可以工作。