《地平线》专题
-
6.16.AVL 平衡二叉搜索树
在我们继续之前,我们来看看执行这个新的平衡因子要求的结果。我们的主张是,通过确保树总是具有 -1,0或1 的平衡因子,我们可以获得更好的操作性能的关键操作。 让我们开始思考这种平衡条件如何改变最坏情况的树。有两种可能性,一个左重树和一个右重树。 如果我们考虑高度0,1,2和3的树,Figure 2 展示了在新规则下可能的最不平衡的左重树。 Figure 2 看树中节点的总数,我们看到对于高度为0的
-
客户端负载平衡器:Ribbon
Ribbon是一个客户端负载均衡器,它可以很好地控制HTTP和TCP客户端的行为。Feign已经使用Ribbon,所以如果您使用@FeignClient,则本节也适用。 Ribbon中的中心概念是指定客户端的概念。每个负载平衡器是组合的组合的一部分,它们一起工作以根据需要联系远程服务器,并且集合具有您将其作为应用程序开发人员(例如使用@FeignClient注释)的名称。Spring Cloud使
-
23.1 性能优化 平均负载
什么平均负载 简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。 所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断
-
操作etcd集群 - 支持平台
注: 内容翻译自 Supported platforms 当前支持 下面的表单列出了常见架构和系统的 etcd 支持状态: 架构 操作系统 状态 维护者 amd64 Darwin 实现性 etcd maintainers amd64 Linux 稳定 etcd maintainers amd64 Windows 实现性 arm64 Linux 实现性 @glevand arm Linux 不稳定
-
5.1.37 37.判断平衡二叉树
一、题目 输入一棵二叉树的根结点,判断该树是不是平衡二叉树。如果某二叉树中任意结点的左右子树的深度相差不超过1 ,那么它就是一棵平衡二叉树。 二、解题思路 解法一:需要重蟹遍历结点多次的解法 在遍历树的每个结点的时候,调用函数treeDepth得到它的左右子树的深度。如果每个结点的左右子树的深度相差都不超过1 ,按照定义它就是一棵平衡的二叉树。 解法二:每个结点只遍历一次的解法 用后序遍历的方式遍
-
py2exe的跨平台替代方案
问题内容: py2exe很棒,每当我想打包一个要在Windows系统上运行的python程序时,我都会使用py2exe。 我的问题是,是否可以使用等效工具在Windows上打包程序,但是可以在Linux上运行? 问题答案: 好的,我已经做到了。这有点hacky,但是对于我的用例来说效果很好。 要点是使用ModuleFinder查找所有导入的模块,过滤掉所有系统模块,编译并压缩它们。 不幸的是,我的
-
python逐列平均列表列表
问题内容: 我有一个列表列表: 我想将其平均 我的代码好像不太优雅。这是遍历列表的幼稚方法,将总和保存在单独的容器中,然后除以元素数。 我认为有一种Python方式可以做到这一点。有什么建议?谢谢 问题答案: 纯Python: 印刷 NumPy: Python 3:
-
在Python中,无身份与平等
问题内容: 各种Python指南都说使用代替。这是为什么?相等用于比较值,因此自然而然地询问是否具有用和表示的值。有人可以解释为什么是首选形式,并举例说明两者没有给出相同答案的例子吗? 谢谢。 问题答案: 人们使用的原因是因为使用没有优势。可以编写比较等于的对象,但这并不常见。 输出: 该运营商也快,但我不认为这确实非常重要。
-
非零值的整数平均值
问题内容: 我有一个大小为N *M的矩阵,我想找到每一行的平均值。值是从1到5,并且没有任何值的条目设置为0。但是,当我想使用以下方法查找均值时,它给了我错误的均值,因为它还计算了具有值的条目0。 如何获得仅非零值的均值? 问题答案: 获取每一行的非零计数,并将其用于平均每一行的总和。因此,实现看起来像这样- 如果您使用的是较旧版本的NumPy,则可以使用count的float转换来替换,例如,
-
平面文件NoSQL解决方案
问题内容: 对于小型项目,是否有内置的SQLite(或类似方法)保持SQL / NoSQL的优点,即: 存储 在 像SQLite这样 的(平面)文件中 (没有客户端/服务器方案,没有要安装的服务器;更精确的是:除了,无需安装其他任何东西) 可以将行存储为, 而 无需为每行都具有通用的结构,例如NoSQL数据库 支持简单查询 例子: 注意:这些年来,我一直惊讶于SQLite在几行代码中实际上有多少有
-
JavaScript平台独立行分隔符
问题内容: JavaScript中是否存在类似于Java的东西? 编辑:我正在使用非浏览器JavaScript环境Node.js 问题答案: 我遇到了同样的问题,并且遇到了这个非常古老的问题。经过一段时间的投资,我终于在os文档的最后找到了。 在这种情况下非常重要,否则您将在控制台中仅看到一个空白行(这是有道理的,因为这就是它应该做的)。在正常的用例中,它是不需要的。
-
将glob展平到一个目录
问题内容: 在Gulp中,我用来从目录中选择每个字体文件: 但是,我希望所有这些字体文件并排放置在一个目录中,而不是从目录中重新创建整个树。 在Gulp,Gulp Utils和npm-glob API中查看并没有真正帮助我,尽管我可以很容易地跳过它。 最好的方法是什么? 问题答案: 我会用gulp-flatten: 至于如何在内部完成,请检查:https : //github.com/armed/
-
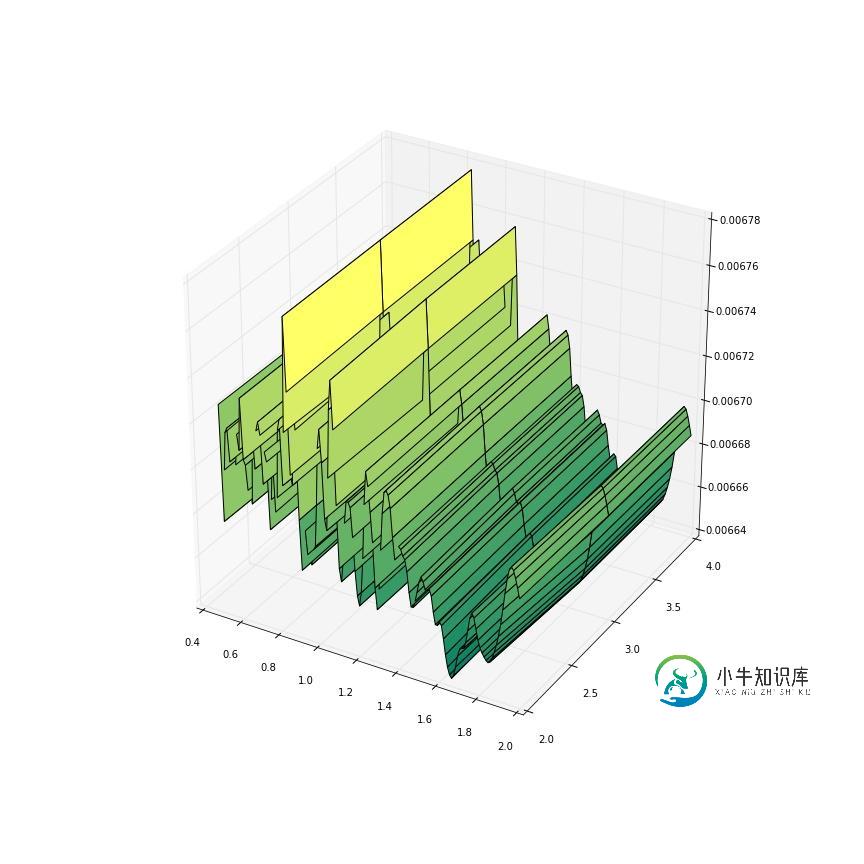 带有Pyplot的平滑表面图
带有Pyplot的平滑表面图问题内容: 我的问题几乎与此类似: 从矩阵平滑表面图 只是我的工具集是matplotlib和numpy(到目前为止)。 我已经成功生成了X,Y和Z网格以进行绘制 但是,由于这些值非常跳跃,因此看起来非常糟糕。 我想使事情变得平滑,至少使顶点连接或看起来像那样。 我的数据是这样生成的:我有一个函数 它根据x生成矩阵,计算其y次幂,选择列和行的子集,并计算最大奇异值。因此,Z [x,y]是svOfMa
-
嵌套平面图可观察rxJava
假设我有一个返回列表的博客帖子api 从列表创建可观察 将每个可观察拆分为
-
$HOME和“~”(平铺)之间的差异?
我一直认为和完全相同,因此可以互换使用。今天,当我试图在我的共享服务器上安装pylibmc(一个绑定到memcached的python)时,使用给了我错误,但没有。我想解释一下原因。 libmemcache是pylibmc的一个要求。我在我的主目录下安装了libmemcache,因为我在服务器上没有根。因此,要安装pylibmc,我需要确保安装脚本知道在哪里可以找到libmemcache。 当执行