《就业》专题
-
如何在Kubernetes部署的应用程序中创建cron作业而不重复?
我试图找到一个解决方案,在Kubernetes部署的应用程序中运行cron作业,而不会出现不必要的重复。让我描述一下我的场景,给你一点背景。 我想安排在指定日期执行一次的作业。更准确地说:创建这样一个作业可以在任何时候发生,它的执行日期只有在那个时候才知道。需要做的工作总是一样的,但是需要参数化。 我的应用程序在库伯内特斯集群中运行,我不能假设在任何时候都只有一个实例在运行。因此,创建所述作业将导
-
访问 Jenkins 作业 DSL 中的ENV_INJECT变量
我无法访问JobDSL的groovy脚本中的任何Jenkins环境变量。我可以看到系统环境变量的值。 这是我正在运行的Groovy脚本: < code > println(system . getenv(" HOME "))println(system . getenv(" WORKSPACE ")) 这是输出: 我试过使用环境注入设置环境变量,但这也不起作用(所有设置变量都为空)。
-
Kubernetes中的Cron作业-连接到现有的Pod,执行脚本
null 有没有一种方法可以通过ScheduledJobs/CronJobs来实现这一点? http://kubernetes.io/docs/user-guide/cron-jobs/
-
每天在特定时间运行 CRON 作业
现在我每天下午3点运行我的cron作业 但是我想一天运行两次cron作业。上午10点30分和下午2点30分 我相信此命令将在上午 10:30 运行。我应该如何在下午 2:30 运行它?
-
[Cassandra]在spark作业中的Cassandra sql中的行键级别进行筛选,导致cpu利用率过剩
-
如何自动删除由 CronJob 创建的已完成的 Kubernetes 作业?
有没有一种方法,自动删除已完成的作业除了使一个Cron作业清理已完成的作业? K8s 作业文档指出,已完成作业的预期行为是让它们保持已完成状态,直到手动删除。因为我每天通过 CronJobs 运行数千个作业,我不想保留已完成的作业。
-
如何通过作业DSL设置主动选择参数的脚本沙盒
我有一个JobDSL脚本,它使用主动选择参数插件提供的主动选择参数创建了一个Jenkins管道作业。不幸的是,JobDSL不支持在沙盒中运行Active Choice Groovy脚本的参数(在UI中它是可用的),所以我试图通过configure block来启用它。 这是我的JobDSL脚本: 使用块,我正在尝试覆盖
-
如何使spark并发运行一个作业中的所有任务?
我有一个系统,其中REST API(Flask)使用spark-sumbit向正在运行的PySpark发送作业。 出于各种原因,我需要spark同时运行所有任务(即我需要设置执行器的数量=运行时的任务数量)。 这可能通过一项工作来实现吗?
-
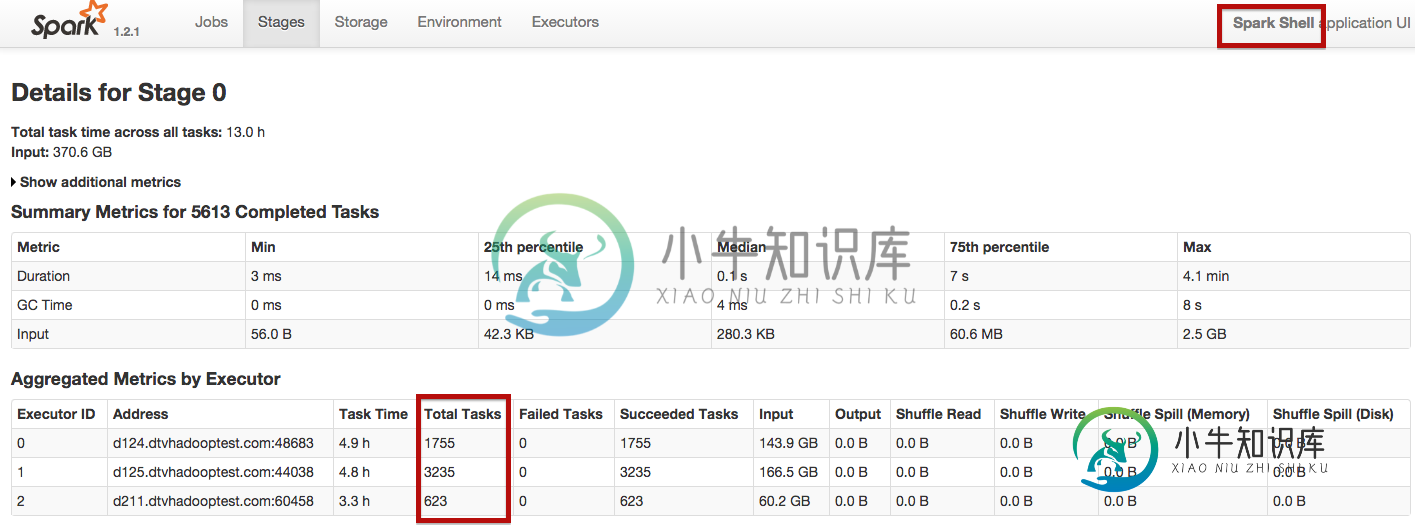 Python vs Scala(用于Spark作业)
Python vs Scala(用于Spark作业)我对Spark很陌生,目前正在通过玩pyspark和Spark-Shell来探索它。 现在的情况是,我用pyspark和Spark-Shell运行相同的spark作业。 这是来自Pyspark: 使用spark-shell,工作在25分钟内完成,使用pyspark大约55分钟。如何让Spark独立地用pyspark分配任务,就像它用Spark-shell分配任务一样?
-
如何优化Spark作业将S3文件处理到Hive Parquet表中
null 应用程序读取所有S3文件=>重新分区到文件数量的两倍=>缓存RDD=>自定义处理每行=>创建临时视图/缓存表=>计数num行=>选择数据子集=>减少分区数量=>创建数据子集的视图=>使用视图插入配置单元目标表=>取消RDD持久化。 我不确定为什么执行要花很长时间。是spark执行参数设置不正确,还是这里调用了一些错误的东西?
-
从远程客户端在Yarn集群上提交Spark作业
我被困在: 在我得到这个之前: 当我签出应用程序跟踪页面时,我在stderr上得到以下信息: 我对这一切都很陌生,也许我的推理有缺陷,任何投入或建议都会有所帮助。
-
如何从spark作业中对ADL进行身份验证
我正在构建一个spark库,开发人员将在编写他们的spark作业时使用该库来访问Azure data Lake上的数据。但是身份验证将取决于他们要求的数据集。我需要从spark job中调用rest API,以获取凭据并进行身份验证,以便从ADL中读取数据。这可能吗?我是新来的火花。
-
火花作业错误超出GC开销限制[重复]
我正在运行一个火花作业,我在spark-defaults.sh.设置了以下配置,我在名称节点中有以下更改。我有1个数据节点。我正在处理2GB的数据。 但我得到一个错误,说GC限制超过。 这是我正在编写的代码。 我甚至尝试了GroupByKey而不是也。但是我得到了同样的错误。但是,当我试图删除还原ByKey或GroupByKey我得到的输出。有人能帮我解决这个错误吗? 我是否也应该在hadoop中
-
无法使用Cassandra驱动程序运行Spark作业
Build.Gradle 分级。性质 例外情况: 代码: 有人知道怎么修吗?
-
如何在Datastax企业中启动没有Cassandra的Spark
我最近在我的5节点集群中安装了DataStax Enterprise(V5.0)。我计划使用3个节点作为spark,2个节点作为cassandra多节点集群。 另外,我应该更改DSE中的哪些conf文件,以便spark连接到在另一个节点上运行的cassandra(而不是在127.0.0.1:9042)