
java - 如何理解LinkedBlockingQueue注释中的cross-generational linking导致了更频繁的major GC?

在阅读LinkedBlockingQueue源码时,有段关于弱一致性迭代器实现的注释:
/*
* To implement weakly consistent iterators, it appears we need to
* keep all Nodes GC-reachable from a predecessor dequeued Node.
* That would cause two problems:
* - allow a rogue Iterator to cause unbounded memory retention
* - cause cross-generational linking of old Nodes to new Nodes if
* a Node was tenured while live, which generational GCs have a
* hard time dealing with, causing repeated major collections.
* However, only non-deleted Nodes need to be reachable from
* dequeued Nodes, and reachability does not necessarily have to
* be of the kind understood by the GC. We use the trick of
* linking a Node that has just been dequeued to itself. Such a
* self-link implicitly means to advance to head.next.大概直译下是:
为了实现弱一致性迭代器,我们似乎需要保证前一个出队结点到所有结点的GC可达性。这可能会导致两个问题:
-允许行为异常(rogue)的迭代器会造成无限的内存保留
-如果一个结点在活着的时候进入老年代了(tenured),迭代器会造成旧结点到新结点的跨代联系,分代GC很难处理这种链接,导致重复的老年收集(major collections)
不过,只要有出队的结点需要可达到未删除的结点这个概念,可达性就没有必要由GC理解。我们会通过将已离队的结点连接到自己的方法,这样的自我连接暗指迭代器需要到head.next结点
个人理解下,保证前一个出队结点到所有结点的GC可达性的队列应该是这样的(current是迭代器的指针):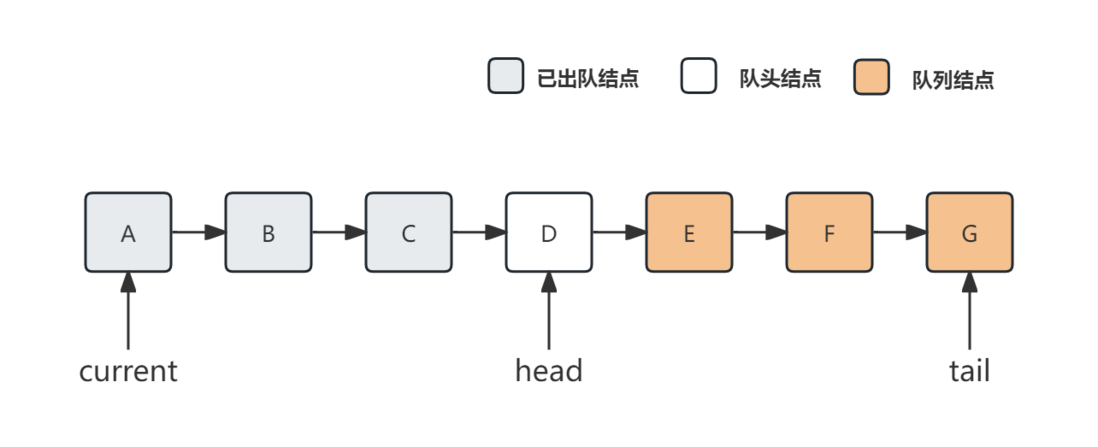
第一点倒好理解,current和head间的出队结点数量是可以无限增加的——只要current不动,队列又不断地入队出队,current和head间的结点就会不断地增加,导致这部分的内存也不断地增加。
但是第二点就不清楚具体是什么意思,为什么旧结点变成老年代后,和新生代结点的跨代联系(cross-generational linking)会导致更频繁的major GC呢?是因为离队的结点理应被GC回收却回收不了,变成老年代之后占据了老年代的空间,老年代剩余空间变少导致major GC更频繁吗?
共有1个答案

理解LinkedBlockingQueue中的"cross-generational linking"与更频繁的major GC
在Java的垃圾回收(GC)机制中,特别是使用分代收集器(如CMS, G1等)时,堆内存被划分为几个代(通常是年轻代和老年代)。年轻代用于存放新生成的对象,这些对象通常很快变成不可达并被GC回收。老年代则存放存活时间较长的对象。
在LinkedBlockingQueue的上下文中,当谈到"cross-generational linking"时,它指的是在GC过程中,老年代的对象(已经经过多次GC仍然存活的对象)与新生代的对象之间建立了直接引用关系。这种跨代的引用关系会对GC性能产生负面影响,原因如下:
- GC策略差异:年轻代和老年代的GC策略通常不同。年轻代通常使用复制算法或标记-清除-压缩算法,这些算法可以快速回收大量短命对象。而老年代则使用标记-清除或标记-整理算法,这些算法处理起来相对较慢。跨代引用会迫使GC在处理年轻代时也要考虑老年代的对象,增加了处理的复杂性。
- 空间碎片化:跨代引用可能导致老年代空间碎片化。如果老年代的对象频繁引用新生代的对象,而这些新生代对象又被快速回收,就会在老年代留下大量空洞,降低空间利用率。
- 增加major GC的触发频率:当老年代空间不足时,会触发major GC(即老年代的垃圾回收)。如果由于跨代引用导致老年代空间被快速填满(例如,由于新生代对象本应被回收却因跨代引用而保留),那么major GC的触发频率就会增加。
- 处理时间延长:由于跨代引用,GC在扫描和处理对象时需要跨越不同的代,这增加了GC的处理时间,可能导致应用程序的暂停时间变长。
在LinkedBlockingQueue的实现中,为了避免这种跨代引用,采用了将已离队的结点连接到自己的技巧。这样,即使迭代器持有了某些结点的引用,这些引用也只是指向结点自身,不会指向队列中的其他结点,从而避免了跨代引用的问题。这种做法确保了即使迭代器存在,也不会阻止队列中的结点被GC回收,从而避免了因跨代引用导致的性能问题。
总结来说,跨代引用在LinkedBlockingQueue中会导致更频繁的major GC,主要是因为它增加了老年代空间的占用率,使得老年代更快地被填满,从而触发了更多的major GC。通过避免跨代引用,可以减少GC的复杂性和开销,提高应用程序的性能。
-
问题内容: 我试图通过一些在线材料来学习Java中的注释。 在下面的代码,发生了什么事我亲爱的“Hello World”的字符串,我在这行通过:? 上面是定义的注释,下面是其用法 当我运行此代码时,它只是打印 请帮帮我,我完全不了解注释。 问题答案: 注释基本上是可以附加到字段,方法,类等的数据位。 在Java中声明注释的语法有点尴尬。它们看起来有点像接口(毕竟是用声明的),但它们并不是真正的接口
-
我所知道的是: 注释是在java 5中添加的 注释可以在方法、类和属性中使用 注释可以在运行时、类、源代码中使用(我不知道如何使用类和源代码,以及它们的特性) 当java程序运行时,可以实现带有保留的注释,即运行时注释 我想实现一个注释,具有以下特性: > @MyAnnotation(allowMethods={xxx.doSomething}) public void getValue(){}
-
通常,当我在Kotlin代码中使用Java库中的注释时,我必须指定target以指定编译代码中必须注释的元素: 而不是指定,我希望能够简单地使用,特别是如果它发生在许多地方。 问题:有没有一种方法可以提示Kotlin编译器在所有位置使用不同的目标,这样如果我使用,它就会像处理一样处理它?或者有没有其他方法可以省略指定目标?如何实现这一目标?是否可以在编译阶段通过注释处理完成(像Lombok那样)?
-
根据Hibernate留档,注释的解释如下: 在嵌入式id对象中,关联表示为关联实体的标识符。但您可以通过@MapsId注释将其值链接到实体中的常规关联。@MapsId值对应于包含关联实体标识符的嵌入式id对象的属性名称。在数据库中,这意味着客户。用户和客户ID。userId属性共享相同的基础列(本例中为user\u fk)。 它还说: 虽然JPA不支持Hibernate,但它允许您将关联直接放置
-
我试图理解JPA中注释的属性。我创建了以下示例,其中客户有一个订单列表: 现在,当我使用Hibernate生成表时,我看到Hibernate只创建了2个表: 另外,如果我试图保存一个客户和一些订单,我会看到下面由Hibernate生成的DML语句: 为什么hibernate尝试在TBL_ORDER中插入和更新记录,而不是仅仅运行一个插入查询? 现在,如果我删除mappedBy属性并尝试生成表,那么
-
我在使用@mockbean注释时遇到了麻烦。文档说MockBean可以替换上下文中的bean,但我在单元测试中得到了一个NoUniqueBeanDefinitionException。我看不出如何使用注释。如果我可以模拟回购,那么显然会有不止一个bean定义。 错误消息: