
计算一行中出现的每个值,并从另一行中获得第三个对应值

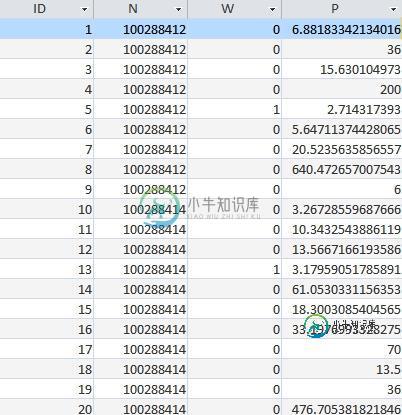
我有数据库与表如图所示。
列N包含重复的值,每个值必须计算在数据库中出现的次数。
如果计数为
我如何在mssql中实现它?
共有2个答案

我想出了两个问题来完成这项工作,首先
选择n,将(*)计数为N从mytable GROUP BY n;
返回n列中的值在表中出现的次数,第二列返回1-2-3个最高值
使用cte AS(SELECT n, p,ROW_NUMBER()OVER(PARTITION BY n ORDER BY p ASC)as rn from mytable)SELECT n, p, rn from cte WHERE rn
但我不知道如何从w列添加数据并将这些查询合并到一个查询中

请尝试以下查询:
select ID, N, W, P from (
select ID, N, W, P,
row_number() over (partition by N order by P desc) rn,
count(ID) over (partition by N) cnt
from TBL
) a where cnt >= 10 and rn = 3
如果N列中的特定值不少于10个条目,则上述将相应地返回P列的第三大值。
-
我想知道是否可以在一个MySQL表中计算pet列中包含值Cat的行数,并在pet列中包含值Dog的同一个表中计算行数。并比较每个查询返回的行数,如果包含Cat的行少于包含Dog的行,则输出“Cat”,反之亦然。 编辑:这是我想要的一个例子。 因此,根据哪只宠物的排数最少,它应该与猫、狗、马或蛇产生回声。
-
我试图计算可能的成对数,这可以通过从两个集合中获取值来实现。没有人停下来Rest。我还尝试使用JavaSet实现它。但我陷入了逻辑,如何计算这种可能的组合。 问题示例: 这里,可能的对组合是 [0,2] , [0,3] , [1,2] , [1,3] , [4,2] , [4,3] 代码如下: 输入可能在某个级别上有所不同,如下所示 这里,可能的对组合是[0,1]、[0,3]、[2,1]、[2,3
-
问题内容: 我有一个示例数据框显示如下。对于每一行,我想先检查c1,如果它不为null,则检查c2。通过这种方式,找到第一个非空列并将该值存储到列结果中。 我现在正在使用这种方式。但是我想知道是否有更好的方法。(列名没有任何模式,这只是示例) 当有很多列时,此方法看起来不好。 问题答案: 首先使用回填s,然后通过以下方式选择第一列: 要么: 性能 :
-
问题内容: 我有一个表,其中包含商店中每件商品的单价和其他详细信息。 另一个包含每个订单中包含的项目的详细信息。 现在我要计算 请注意,我希望它成为表本身的一部分,而不是作为其他视图或查询。我怎样才能做到这一点?我为此研究了触发器和其他机制,但是它们是否适用于不同表中的值,尤其是在存在此类约束的情况下? 我尝试过根据另一列计算出的Column进行以下触发吗?: 但这似乎没有用 问题答案: 这是如何
-
问题内容: 表格如下: 我想获取班级列表,以及每个班级-属于每个班级的学生人数。我怎样才能做到这一点? 问题答案: 您需要这样做-
-
我需要计算每行的平均值,并存储在最后一个元素中。我设法做到了,但后面的行是前一行的累计平均值。例如: 输入: 1 2 3 0 4 5 6 0 输出: 1.00 2.00 3.00 2.00 4.00 5.00 6.00 7.00(应为5.00) 这是我的代码 提前谢谢。:)