
如何在Python中使用Selenium Webdriver提取总搜索结果?

我试图使用selenium webdriver从给定搜索结果URL的IEEE Xplore搜索中提取搜索结果计数。我没有从下面的代码中得到任何错误,但我不确定如何从这里开始。
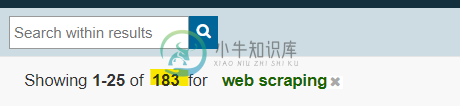
url = 'https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping'
chrome_driver_path = '\\xxxx\chromedriver.exe'
driver.get(url)
wait.until(presence_of_element_located((By.CLASS_NAME, "strong")))
#result = driver.??????
print(result)
driver.close()
共有2个答案

正如dukkee提到的,请检查api,但要回答您的问题,您可以选择如下选项:
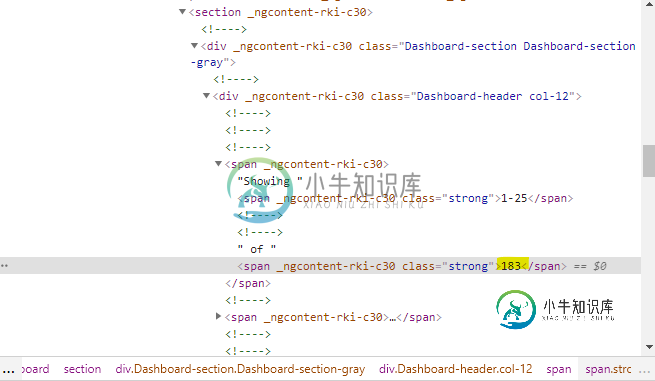
soup.select('div.Dashboard-header.col-12 > span span')[1].get_text()
找到具有唯一类的父div,然后转到span。
实例
from selenium import webdriver
from bs4 import BeautifulSoup
import time
url = 'https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping'
driver = webdriver.Chrome('C:\Program Files\ChromeDriver\chromedriver.exe')
driver.get(url)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
print(soup.select('div.Dashboard-header.col-12 > span span')[1].get_text())
driver.quit()

要打印搜索结果的数量,即184,您可以使用以下任一定位器策略:
>
使用css_selector和get_attribute(innerHTML):
driver.get("https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping")
print(driver.find_element(By.CSS_SELECTOR, "div.Dashboard-header span span:nth-of-type(2) ").get_attribute("innerHTML"))
使用xpath和文本属性:
driver.get("https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping")
print(driver.find_element(By.XPATH, "//div[contains(@class, 'Dashboard-header')]//span//following::span[2]").text)
理想情况下,您需要为位于()的元素的可见性引入WebDriverWait,并且您可以使用以下任一定位器策略:
>
使用CSS_SELECTOR和text属性:
driver.get("https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping")
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div.Dashboard-header span span:nth-of-type(2)"))).text)
使用XPATH和get\u属性(“innerHTML”):
driver.get("https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=web%20scraping")
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[contains(@class, 'Dashboard-header')]//span//following::span[2]"))).get_attribute("innerHTML"))
控制台输出:
184
注意:您必须添加以下导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
您可以找到有关如何使用Selenium-Python检索WebElement文本的相关讨论
链接到有用的文档:
get\u attribute()method获取元素的给定属性或属性
-
我使用logstash将我的mysql表数据保存到elasticsearch中。现在我想使用特定字段从elasticsearch获取数据。我可以使用id获取数据,但无法使用其他字段检索数据。 我正在使用elasticsearch 5.6.12和Spring boot 2.0 searchcontroller.java 我想用first_name搜索,但什么都没有显示。我在这里做错了什么?
-
问题内容: 我想使用python脚本在Google中搜索文本,然后返回每个结果的名称,描述和URL。我目前正在使用此代码: 这仅返回URL。如何返回每个URL的名称和描述? 问题答案: 并不是我一直在寻找的东西,但是我发现自己现在是一个不错的解决方案(如果我可以做得更好的话,我可以对其进行编辑)。我像在Google中一样搜索(仅返回URL)和Beautiful Soup软件包结合在一起来解析HTM
-
本文向大家介绍python实现提取百度搜索结果的方法,包括了python实现提取百度搜索结果的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现提取百度搜索结果的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的Python程序设计有所帮助。
-
当跨多个索引进行搜索时,elasticsearch的“多重匹配”查询将返回搜索结果中的索引名称。 响应包含字段,该字段告诉结果来自的索引 spring-data-elasticsearch中用于的类是和具有字段、、用于获取与elasticsearch查询相似的数据。但它不包含用于存储字段信息的相关字段。 还支持吗?我需要根据哪个客户端应用程序将生成一些URL发送搜索命中类型(name)。 这是我使
-
我正在使用Selenium(Java版本)测试一个基于OpenLayers的API。 我想测试一个使用的功能。控制修改功能。我想单击绘制的特征(SVG),然后拖动并检查它们是否存在、可见或隐藏。 我已经画了一个多边形,并且选择了它。见下图: 这些SVG元素的HTML如下所示: 假设我想选择红点。 我试过: 但是它总是返回一个空列表。 我做错了什么?有人能帮我吗? 多谢了。 编辑1-功能:垂直显示可
-
问题内容: 如果您在python中有一个列表,并且想要将索引1、2和5的元素提取到新列表中,您将如何做? 这是我的做法,但我并不十分满意: 有没有更好的办法? 更一般而言,给定一个索引元组,即使使用重复,您将如何使用该元组从列表中提取相应的元素(例如,元组产生)。 问题答案: 也许使用这个: