
“解析器规则中的隐式令牌定义”是否值得担心?

我正在用ANTLR和ANTLRWorks 2创建我的第一个语法。我基本上已经完成了语法本身(它识别用所描述的语言编写的代码并构建正确的解析树),但除此之外,我还没有开始任何其他工作。
让我担心的是,解析器规则中标记的每一次首次出现都用黄色曲线下划线表示“解析器规则中的隐式标记定义”。
例如,在此规则中,“var”具有曲线:
variableDeclaration: 'var' IDENTIFIER ('=' expression)?;
具体外观:
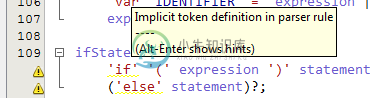
奇怪的是,ANTLR本身似乎并不在意这些规则(在进行测试台测试时,我在解析器生成器输出中看不到任何警告,只是关于我的机器上安装了不正确的Java版本),所以这只是AntlWorks的抱怨。
这是值得担心的还是我应该忽略这些警告?我应该在lexer规则中显式声明所有标记吗?官方圣经中的大多数例子,定义性ANTLR引用似乎完全按照我编写代码的方式进行。
共有2个答案

如果您正在编写不会跨多个解析器语法使用的lexer语法,那么您可以忽略ANTLRWorks2显示的此警告。

我强烈建议在任何重要的代码中更正此警告的所有实例。
此警告(实际上是我创建的)是为了提醒您以下情况:
shiftExpr : ID (('<<' | '>>') ID)?;
由于ANTLR 4鼓励用目标语言在单独的文件中编写动作代码,而不是将它们直接嵌入语法中,因此能够区分<代码>
此警告还有助于避免以下问题情况:
>
解析器规则包含无意中的令牌引用,例如:
number : zero | INTEGER;
zero : '0'; // <-- this implicit definition causes 0 to get its own token
-
如果我对“令牌”不感兴趣,因为规则已经建立了我要匹配的对象,而且我无论如何都要跳过它,那么用和令牌声明替换它有意义吗?(然后,代币的数量将会增加。)为什么在ANTLRWorks中这是一个警告?
-
需要注意的方法是和。实际上,我依赖于这样一个事实,即每个节点最终都分解为终端,因此如果一个节点没有被另一个重写处理(例如中的),那么它的每个终端都将位于中。对的每次调用都会添加到索引字段中,我假定该字段与AST和原始文本同步。也就是说,应该同时表示原始文本中的索引和当前标记的索引。 我最近遇到了一个空白问题。语法规则似乎悄无声息地吃掉了空白,而没有在任何解析器规则中提到它。这会导致空白标记无法通过
-
我对是否允许以下情况感到困惑: UPDATE:我知道当我在for循环中提供正确的声明类型时,它就会工作。问题是如果我不这样做会发生什么?
-
2. 隐含规则和模式规则 上一节的Makefile写得中规中矩,比较繁琐,是为了讲清楚基本概念,其实Makefile有很多灵活的写法,可以写得更简洁,同时减少出错的可能。本节我们来看看这样一个例子还有哪些改进的余地。 一个目标依赖的所有条件不一定非得写在一条规则中,也可以拆开写,例如: main.o: main.h stack.h maze.h main.o: main.c gcc -c ma
-
CloudGate解析规则可以直接导入使用,不需要任何额外的操作,非常方便! 规则列表 规则名称 下载地址 Surge https://async.be/Rule/Basic/Hosts Shadowrocket https://async.be/Rule/Basic/Hosts 解析规则 简要概述:通过实时同步Hosts信息源达到自动更新,同时使用解析模板进行生成。 无需任何其他操作,导入即可使
-
template.defaults.rules art-template 可以自定义模板解析规则,默认配置了原始语法与标准语法。 修改界定符 // 原始语法的界定符规则 template.defaults.rules[0].test = /<%(#?)((?:==|=#|[=-])?)[ \t]*([\w\W]*?)[ \t]*(-?)%>/; // 标准语法的界定符规则 template.def