
删除额外的逗号、空格

我有一个5页的pdf文件,每页有一个表,我需要提取。我需要从每一页提取所有的表,并将它们保存为数据帧文件,所有使用python,所以我转换了文件,使用tabula的csv文件
tabula.convert_into('input.pdf', "output.csv", output_format="csv", pages='all')
文件输出的主要问题。csv是指有几个额外的逗号。
实例
Id,Name,Age,,Score,Rang,Bonus
181,ALEX,,,,20,987
182,Julia,,,,18,8.390
183,Marian,,,,21,9.170
184,Julien,,0,175,60,9.095
Id,Name,Age,,Score,Rang,Bonus
215,Asma,26,,35,19,3.807
216,Juan,,,,20,7.982
217,Rami,,,,10,1.832
Id,Name,Age,,Score,Rang,Bonus
415,Jessica,,4 920,8 873,538,7.994
416,Karen,,890,6,12,9.993
417,Andrea,,0,69,283,7.200
Id,Name,Age,,Score,Rang,Bonus
419,Rym,10,,18,,10,7.196
420,Noor,10,,70,,910,8.291
421,Nathalie,0,,5,,0,0.900
"",Id,Name,Age,,Score,Rang,Bonus
456,,Joe,,10,13,0,74.917
457,,Loula,,0,18,11,9.990
458,,Maria,,0,15,172,6.425
459,,Carl,,15,17,11,3.349
Id,Name,Age,,Score,Rang,Bonus
566,Diego,,,,0,3.680
567,Carla,0,,26,1,19.361
当我将csv文件转换成行/列时,我得到了一些行偏移
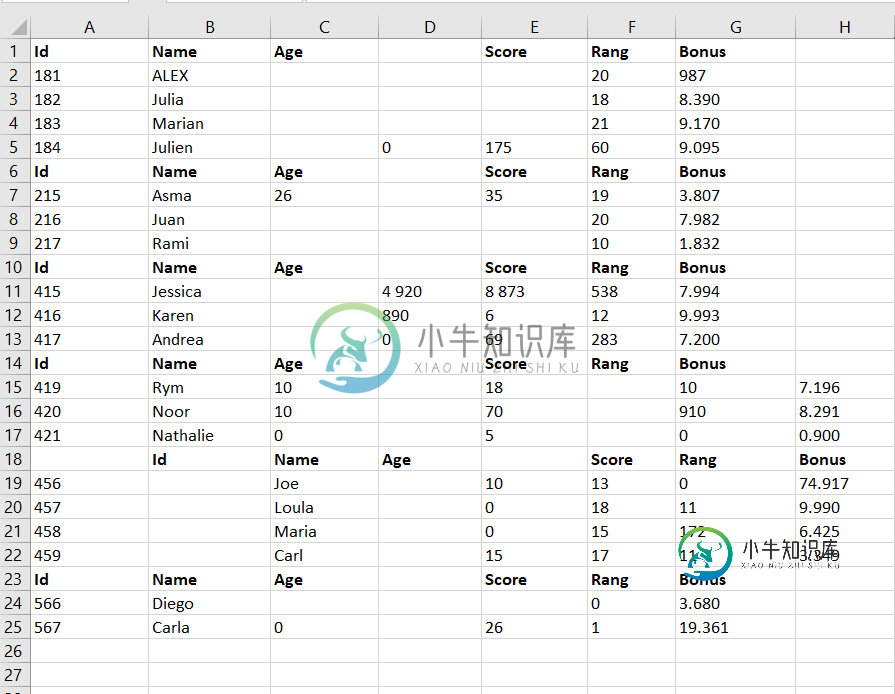
注意:dataframe应该有6列,其中包含空字段。我猜额外的逗号来自pdf文件中的空格。如何从csv文件中删除额外的逗号或删除pdf文件中的额外空间。
我真的很感激你的帮助。
共有3个答案

将CSV内容加载到数据框中后,删除第三列,您将获得所需格式的数据。
注意:我没有在这里添加任何列名。您可以在删除列之后添加它们
import pandas as pd
l = ['181,ALEX,,,,20,987', '182,Julia,,18,79,98,8.390', '183,Marian,,21,89,70,9.170', '184,Julien,,,,60,9.095']
df = pd.DataFrame([sub.split(",") for sub in l])
df.drop(2, inplace=True, axis=1)
print(df)
Output:
0 1 3 4 5 6
0 181 ALEX 20 987
1 182 Julia 18 79 98 8.390
2 183 Marian 21 89 70 9.170
3 184 Julien 60 9.095

我发现这比马丁·埃文斯的答案更容易理解
这是一个很好的例子,发电机产生的线路长度与清理后的第一条线路相同。并删除第一个空字符串,直到一行具有正确的长度。
像Martin的回答一样,它从示例数据中生成预期的数据帧。
import pandas as pd
from io import StringIO
import csv
f = StringIO("""Id,Name,Age,,Score,Rang,Bonus
181,ALEX,,,,20,987
182,Julia,,,,18,8.390
183,Marian,,,,21,9.170
184,Julien,,0,175,60,9.095
Id,Name,Age,,Score,Rang,Bonus
215,Asma,26,,35,19,3.807
216,Juan,,,,20,7.982
217,Rami,,,,10,1.832
Id,Name,Age,,Score,Rang,Bonus
415,Jessica,,4 920,8 873,538,7.994
416,Karen,,890,6,12,9.993
417,Andrea,,0,69,283,7.200
Id,Name,Age,,Score,Rang,Bonus
419,Rym,10,,18,,10,7.196
420,Noor,10,,70,,910,8.291
421,Nathalie,0,,5,,0,0.900
"",Id,Name,Age,,Score,Rang,Bonus
456,,Joe,,10,13,0,74.917
457,,Loula,,0,18,11,9.990
458,,Maria,,0,15,172,6.425
459,,Carl,,15,17,11,3.349
Id,Name,Age,,Score,Rang,Bonus
566,Diego,,,,0,3.680
567,Carla,0,,26,1,19.361""")
def clean_up(csv_file):
header = None
for line in csv_file:
if not header:
header = [v for v in line if v]
length = len(header)
continue
while len(line) > length:
line.remove('')
if line != header:
yield(dict(zip(header,line)))
df = pd.DataFrame(clean_up(csv.reader(f)))
print(df)
这给了你:
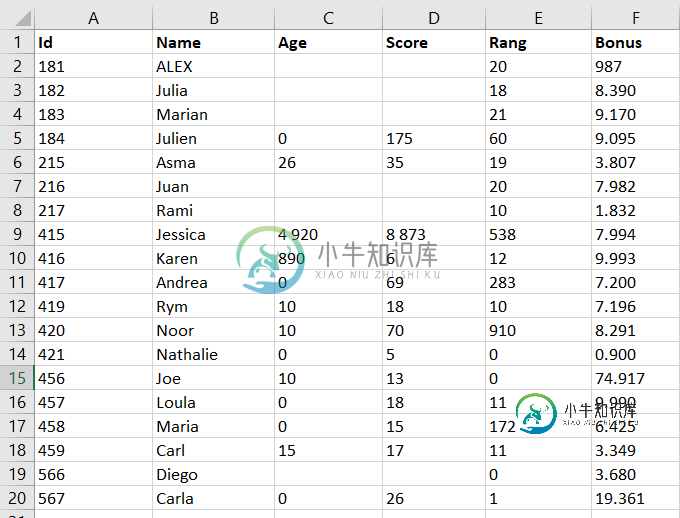
Id Name Age Score Rang Bonus
0 181 ALEX 20 987
1 182 Julia 18 8.390
2 183 Marian 21 9.170
3 184 Julien 0 175 60 9.095
4 215 Asma 26 35 19 3.807
5 216 Juan 20 7.982
6 217 Rami 10 1.832
7 415 Jessica 4 920 8 873 538 7.994
8 416 Karen 890 6 12 9.993
9 417 Andrea 0 69 283 7.200
10 419 Rym 10 18 10 7.196
11 420 Noor 10 70 910 8.291
12 421 Nathalie 0 5 0 0.900
13 456 Joe 10 13 0 74.917
14 457 Loula 0 18 11 9.990
15 458 Maria 0 15 172 6.425
16 459 Carl 15 17 11 3.349
17 566 Diego 0 3.680
18 567 Carla 0 26 1 19.361

我的策略是基于一个简短的正则表达式来捕获前两列和末尾的数字。
(\d+,[^,]+,) → numbers + comma + anything but comma + comma
,* → zero or more commas
(\d.+) → the rest of the line starting from the first number
然后我将两组插入中间逗留足够逗号,使总数为5(=6列)。
对我来说,这似乎是一个相当直截了当的方法。只要数字数据是右对齐的,它将适用于插入随机空格和逗号的任何输入变体。
import re,io
def fix_line(line):
# remove duplicate commas and spaces
line = re.sub(',,', ',', line.replace(' ', ''))
# groups: first two rows / middle (non-captured) / numbers
match = re.match(r'(\d+,[^,]+,),*(\d.+)', line)
if not match: # removes the headers
return ''
# align numbers to right: 6 columns = 5 commas
return match.groups()[0]+(','*(5-2-match.groups()[1].count(',')))+match.groups()[1]
data_corr = [fix_line(line) for line in lines]
df = pd.read_csv(io.StringIO('\n'.join(data_corr)),
names=re.sub(',,+', ',', lines[0]).split(',') # assign column names
)
假设此输入为变量行:
['Id,Name,Age,,Score,Rang,Bonus',
'181,ALEX,,,,20,987',
'182,Julia,,,,18,8.390',
'183,Marian,,,,21,9.170',
'184,Julien,,0,175,60,9.095',
'Id,Name,Age,,Score,Rang,Bonus',
'215,Asma,26,,35,19,3.807',
'216,Juan,,,,20,7.982',
'217,Rami,,,,10,1.832',
'Id,Name,Age,,Score,Rang,Bonus',
'415,Jessica,,4 920,8 873,538,7.994',
'416,Karen,,890,6,12,9.993',
'417,Andrea,,0,69,283,7.200',
'Id,Name,Age,,Score,Rang,Bonus',
'419,Rym,10,,18,,10,7.196',
'420,Noor,10,,70,,910,8.291',
'421,Nathalie,0,,5,,0,0.900',
'"",Id,Name,Age,,Score,Rang,Bonus',
'456,,Joe,,10,13,0,74.917',
'457,,Loula,,0,18,11,9.990',
'458,,Maria,,0,15,172,6.425',
'459,,Carl,,15,17,11,3.349',
'Id,Name,Age,,Score,Rang,Bonus',
'566,Diego,,,,0,3.680',
'567,Carla,0,,26,1,19.361']
输出:
Id Name Age Score Rang Bonus
0 181 ALEX NaN NaN 20 987.000
1 182 Julia NaN NaN 18 8.390
2 183 Marian NaN NaN 21 9.170
3 184 Julien 0.0 175.0 60 9.095
4 215 Asma 26.0 35.0 19 3.807
5 216 Juan NaN NaN 20 7.982
6 217 Rami NaN NaN 10 1.832
7 415 Jessica 4920.0 8873.0 538 7.994
8 416 Karen 890.0 6.0 12 9.993
9 417 Andrea 0.0 69.0 283 7.200
10 419 Rym 10.0 18.0 10 7.196
11 420 Noor 10.0 70.0 910 8.291
12 421 Nathalie 0.0 5.0 0 0.900
13 456 Joe 10.0 13.0 0 74.917
14 457 Loula 0.0 18.0 11 9.990
15 458 Maria 0.0 15.0 172 6.425
16 459 Carl 15.0 17.0 11 3.349
17 566 Diego NaN NaN 0 3.680
18 567 Carla 0.0 26.0 1 19.361
注意。如果输入为文件,则首先使用以下命令读取行:
with open('/path/to/file', 'r') as f:
lines = f.readlines()
-
问题内容: 使用Python v2,我让用户在字符串中输入金额,如下所示: 这将去除输入前面的所有空格,如果输入了$,则删除$。 如果输入逗号符号,是否可以删除逗号符号?IE:$ 10,000.00变为10000.00 谢谢你的帮助。 问题答案: 您可以使用删除所有逗号:
-
我在找正则表达式(?)仅删除逗号前后空格的方法。示例: 预期结果: 尽管进行了多次搜索,我仍然找不到满意的答案。
-
我发现这个问题在堆栈溢出和其他站点上也得到了回答。我尝试了所有的选择,但它们都是空白。我的tableview中有4个原型单元格。在故事板上,第四个单元格后没有空格。但在执行时,我发现第四排后面有空白。第四排之后,它们不再是分隔符,但空白的白色仍然是它们的。我尝试添加以下代码: 为了使整个视图看起来合适,我为视图和tableview设置了相同的背景色。除了这个白色区域之外,其他一切看起来都正常, 有
-
例如,我希望使用函数将转换为: 空格的解决方案是,所以我希望比较这方面的解决方案也能帮助解释一些正则表达式的基本原理。
-
问题内容: 我从数据库中得到了String,它有多个逗号()。我想删除 最后一个逗号, 但实际上找不到一种简单的方法。 我有的: 我想要的是: 问题答案: 要删除紧随字符串结尾的部分,您可以执行以下操作: 相对于/ solution,它需要对此类情况进行特殊处理,这可以优雅地处理空列表(空字符串)。 示例代码: 注意: 由于存在有关零件的一些注释和建议的编辑:表达式应与要删除的尾部零件匹配。 如果
-
我有一个字符串,其中有多个逗号和空格作为单词之间的分隔符。以下是一些示例: 我想使用正则表达式将上述3个示例中的任何一个转换为“word1, word2, word3”-(注意:结果中最后一个单词后没有逗号)。 我使用了以下代码: 我得到的输出是“word1,word2,word3,”。而实际上我想要“word1,word2,word3”。单词3后没有逗号。 我应该使用什么样的正则表达式和re方法