
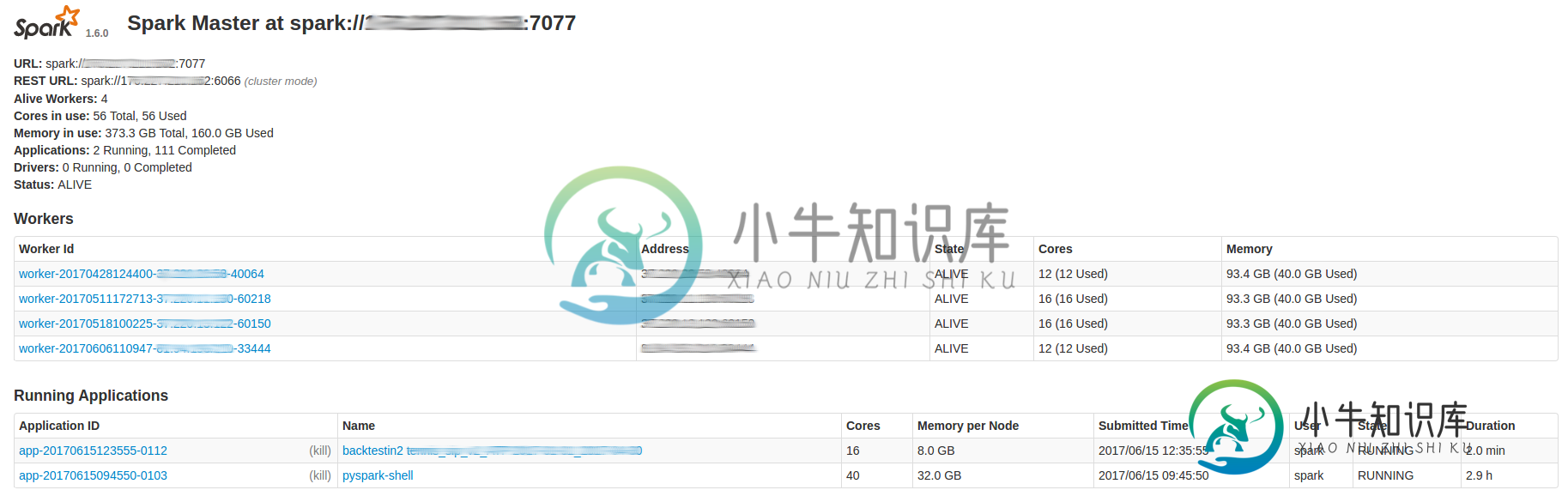
如何读取Spark UI

我试图在这张图片中了解当前的Spark情况。
在我看来是什么样子
- 4台工人机器,每个机器具有93.3 Gb Ram
(注意:我确定作业是如何在节点之间拆分的。)
我的期望
- app
pyskark-shell每台机器使用10个内核,每台机器使用32 Gb RAM,每台CORE=320 Gb总使用量 - app
backtestin2使用16个内核在机器之间拆分,每个内核在每台机器中需要8 Gb=总共128 Gb
这是否意味着每个节点的内存在特定应用程序的节点上运行的所有任务之间共享?我认为属性conf.set('spark.executor.memory',executor_memory)应该是每个任务。
理论基础:
我确实知道每个任务需要多少内存,但我不知道每个执行者需要多少任务:因此我无法估计每个执行者的内存。
共有1个答案

这是否意味着每个节点的内存在特定应用程序的节点上运行的所有任务之间共享?
没错,每个节点的内存是指为每个节点上的应用程序分配的总内存。此内存根据spark内存配置进一步拆分(http://spark.apache.org/docs/latest/configuration.html#memory-管理层)。在估计内存需求时,需要考虑将有多少内存用于存储(即缓存的数据帧/RDD)和执行。默认情况下,一半的内存用于执行任务,另一半用于存储。还可以配置可并行运行的任务数(默认为#个内核)。假设一半的内存用于执行,并且假设您已经对数据进行了适当的分区,那么使用默认配置运行应用程序所需的内存总量约为2*(#个并行运行的任务)*(运行最大任务之一所需的内存)。当然,这个估计高度依赖于您的特定用例、配置和实现。中有更多与内存相关的提示https://spark.apache.org/docs/latest/tuning.html . 希望Spark UI在将来能够得到改进,以便更清楚地了解内存使用情况。
-
徒步旅行例子 我们首先创建到应用程序的三个连接(内存池、共识和查询)(在本例中本地运行 kvstore)。 I[10-04|13:54:27.364] Starting multiAppConn module=proxy impl=multiAppConn I[10-04|13:54:27.366] Starting localClient
-
问题内容: 当有字符可用时,是否有一种优雅的方法来触发事件?我想避免投票。 问题答案: 您将必须创建一个单独的线程以阻止读取,直到有可用的线程为止。 如果您不想实际消耗输入,则必须用内部缓冲区包装它,读入缓冲区,然后喊叫,并在要求输入时从缓冲区返回数据。 您可以这样解决:
-
问题内容: 我有以下代码: 和此web.xml(缩短了程序包并更改了名称,但外观相同) 我想在过滤器之后调用Servlet。我希望可以做到这一点,但是我总是会遇到以下错误: 问题答案: 你可能开始使用 in 使用HttpServletRequest : 你的servlet尝试调用相同的请求,这是不允许的。你需要做的是使用制作请求正文的副本,因此你可以使用多种方法读取它。
-
问题内容: 我正在尝试使用PHP构建Web应用程序,并且正在使用memcached从数据库存储用户数据。 例如,假设我有以下代码: 我不太确定如何读取变量并从中获取数据。我将需要能够阅读电子邮件和密码列。 我希望有人可以向我解释这是如何工作的。 谢谢 问题答案: PDOStatement :: fetch 从结果集中返回一行。该参数告诉PDO将结果作为关联数组返回。 数组键将与您的列名匹配。如果您
-
我已经创建了可执行的jar文件(使用Eclipse),有一组图像(.png)文件要嵌入到jar中。因此,我添加了一个源文件夹,其中包含项目中文件夹中的所有图像。代码必须访问这些文件才能使用
-
我无法找出是否可以在pom.xml文件中读取Spring的application.properties中的任何数据。 拜托,有人能帮我吗? 谢谢你。