
AWS EMR Spark-Cloudwatch

我在AWS EMR Spark上运行一个应用程序。这里,是spark提交作业-
Arguments : spark-submit --deploy-mode cluster --class com.amazon.JavaSparkPi s3://spark-config-test/SWALiveOrderModelSpark-1.0.assembly.jar s3://spark-config-test/2017-08-08
所以,AWS使用YARN进行资源管理。当我观察云观察指标时,我对此有几个疑问:-
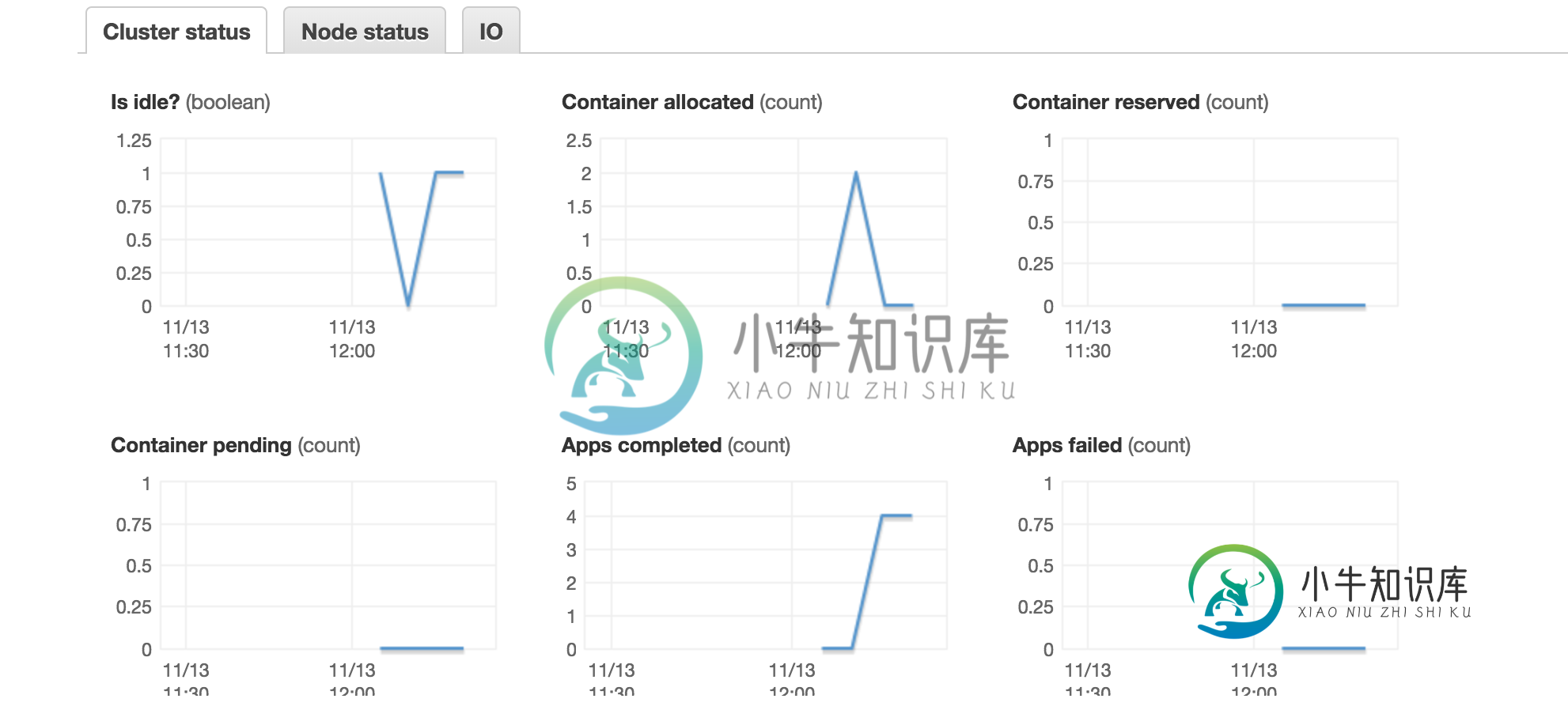
这里分配的容器意味着什么?我正在使用1 master
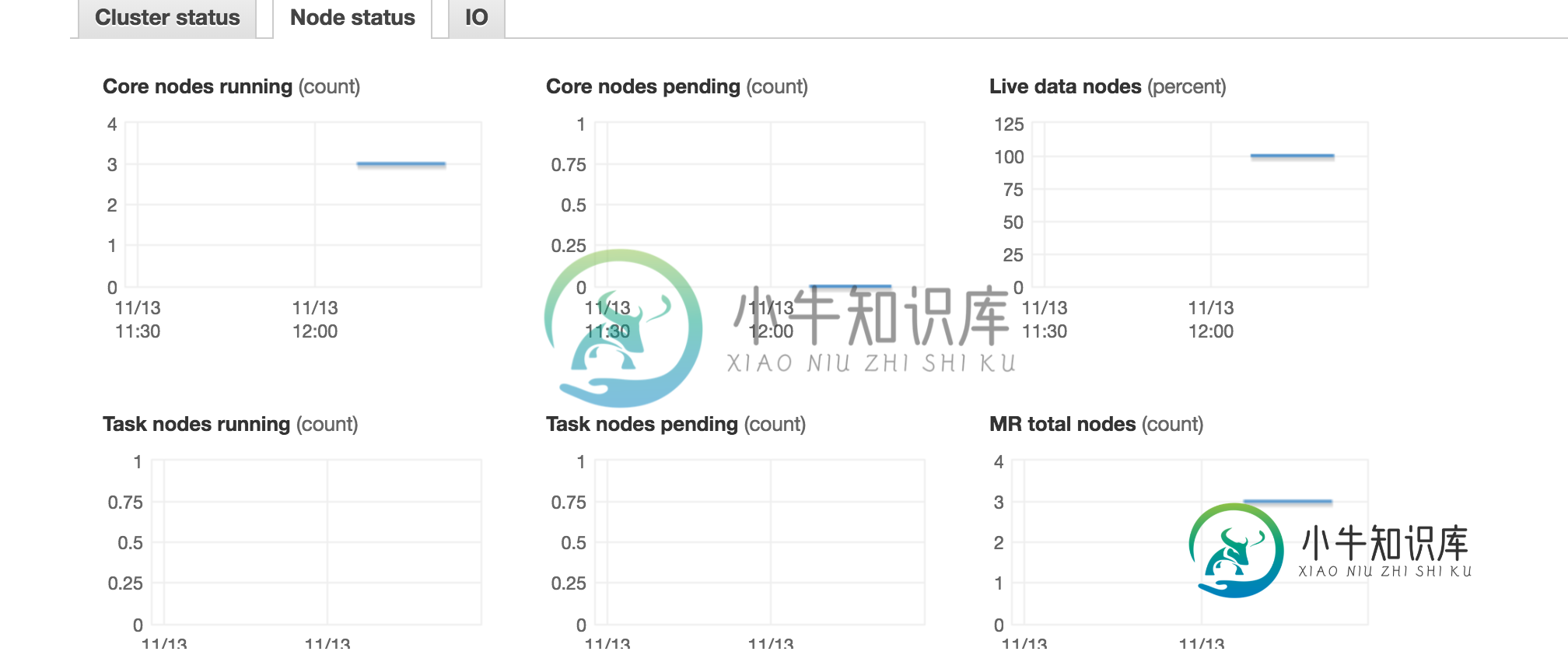
我将查询更改为:-
spark-submit --deploy-mode cluster --executor-cores 4 --class com.amazon.JavaSparkPi s3://spark-config-test/SWALiveOrderModelSpark-1.0.assembly.jar s3://spark-config-test/2017-08-08
这里运行的内核数是3。不应该是3(执行器数)*4(内核数)=12吗?
共有1个答案

1) 此处分配的容器基本上表示spark执行器的数量。Spark executor cores更像“executor tasks”,这意味着可以将应用程序配置为每个物理cpu运行一个executor,但仍然要求它每个cpu有3个executor Core(想想超线程)。
当您没有指定spark执行器的数量时,默认情况下在EMR上发生的情况是,假设动态分配,spark只会向YARN询问它认为在资源方面需要什么。尝试将执行器的数量显式设置为10,分配的容器最多为6个(最大数据分区)。此外,在“应用程序历史记录”选项卡下,您可以获得纱线/火花执行器的详细视图。
2) 这里的“核心”指的是EMR核心节点,与spark executor核心不同。“任务”与“监控”选项卡中的“EMR任务”节点相同。这与我的设置一致,因为我有3个EMR从节点。
-
问题内容: 我正在尝试使用我的程序实现以下目的:在AWS CloudWatch上创建日志组在上述日志组下创建日志流在上述日志流下放置日志事件 所有这些都用go lang 现在,当我运行上述代码时,它成功创建了日志组和日志流,并且可以在AWS CloudWatch中进行验证。但是由于某些原因,PutLogEvents失败并显示以下错误: 我不确定这里可能出什么问题。任何建议或指示将非常有帮助。 提前
-
我有一个lambda函数,负责检查服务器状态。当SQS收到新消息时需要调用它,并且不允许在SQS中更改任何内容。我尝试使用SQS Lambda触发器,但它会将消息推送到Lambda函数中= 我正在寻找处理这个问题的方法。我尝试使用CloudWatch来处理这个问题,但我不知道这是否可能?当SQS收到新消息时,Cloudwatch如何触发Lambda函数? 提前谢谢。
-
设置CloudTrail时,您必须指定一个S3存储桶来存储数据。 由于我使用CloudWatch(和CloudWatch度量/警报)进行存储,我认为我不需要在S3中冗余存储数据。 即使在为CloudTrail配置了CloudWatch之后,我也必须继续使用S3存储,这有什么原因吗?有没有办法关闭CloudTrail的S3存储?
-
在AWS控制台中,我们可以轻松地为step function statemachine启用cloudwatch日志记录和X-ray,但我希望我的资源完全由Terraform管理,从以下页面:https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/sfn_state_machine 目前,Terrafor
-
我正在尝试根据Cloudwatch触发器,特别是Cloudwatch scheduled(cron)触发器设置ECS Fargate作业以运行。我已经设置了ECS群集,当我在群集上手动创建ECS Fargate任务时,作业运行正常,没有错误。我还设置了Cloudwatch cron触发器,我可以在Cloudwatch指标中看到触发器是按照我配置的方式设置的。我遇到的问题是,这两件事没有相互交谈。我
-
我创建了一个AWS Lambda函数,并在Cloudwatch中创建了一个计划事件规则,每5分钟触发一次: